図 3.6-1 Warwick Framework
報告者: 杉本重雄委員
3.6.1 はじめに
1990年代のインターネットとWorld Wide Web(WWW)の急速な発展により我々の情報環境は大きく変化した。我々は日常的にGoogleやYahoo!を用いて必要な情報を探している。これは机の上から世界中で発信される情報にアクセスし、必要な情報を探すことを意味する。このようなことは10年前には考えられなかったことである。
Digital Library(電子図書館、ディジタル図書館、ここではディジタルライブラリあるいはDLと記す[1])はインターネット上での重要な応用分野と位置づけられ、研究開発が積極的に進められてきた。こうした研究開発は大きく分けると新しい情報技術の開発を目的とする研究中心のものと、図書館などをベースにして実際的なDL環境を提供するものに分けることができる。前者の代表格はアメリカのNSF他の共同助成で進められたDigital
Library Initiative(DLI)であろう[1]。DLという分野から容易に理解できることであるが、そこには多様な技術要素が含まれており、またそれらの統合技術も重要な要素となっている。そこで進められた研究は、図書館で直接そのまま利用できるシステムの開発を目指したものとは言えないが、応用分野と計算機科学・情報学分野を結びつけた新しい取り組みであり、かつ図書館に注目を集めたという点からは大きな役割を果たしたものであると言える。また、NSFによるNational
SMETE Digital Library(NSDL)[2]プログラムは、数学・科学技術・工学分野での教育・学習資源の開発とそれらの利用のための基盤の研究開発を目指している[2]。これは教育学習コンテンツの開発をもサポートするものであり、インターネット上に教育学習コンテンツとその利用環境(すなわち図書館)の実現を目的とするものである。一方、後者には大学図書館や国立図書館などで進められた新しい図書館環境を提供するものや、大学などの組織による新しい情報資源の蓄積と流通の取り組みがある。図書館による取り組みとして典型的なものにはアメリカ議会図書館のAmerican
Memoryに代表される歴史資料・貴重資料のディジタル化のプロジェクトがある。大学図書館では、電子出版物の提供、資料の電子化と提供、インターネット情報資源へのアクセス支援、ネットワーク時代に適した新しい図書館環境の提供といった幅広い取り組みがなされてきている。
ネットワーク上での情報資源の流通は、情報資源に関する情報の記述、すなわちメタデータの重要性を広く認識させることになった。例えば、教育・学習資源、ビデオデータ、地理的・空間的情報、電子商取引、資料保存というように、メタデータは多様な分野で開発が進められている。こうしたいろいろなメタデータ規則の中で、インターネット上での情報資源の発見を目的としてDublin
Core Metadata Element Set(DCMES)と呼ばれるメタデータ規則の開発が進められてきた。DCMESは、多様な分野の多様な情報資源に関する記述を前提として開発されてきたメタデータ規則である。DCMESの取り組みにおける基本的かつ重要な視点は、多様なコミュニティで作り出される多様な資料(情報資源)に対して相互利用可能なメタデータのための規則を作り上げること、すなわちinteroperability(相互運用性、相互利用性)であろう。
interoperabilityがインターネット上の情報流通、DLにとって重要であることは言うまでもない。例えば、1997-98年にDLの研究戦略を議論するワーキンググループでも重要な研究トピックとして議論されている[3]。また、2001年のJoint
Conference on Digital Libraries(JCDL 2001)[3]での基調講演において、Clifford
LynchはDLにおけるinteroperabilityについて述べた[4]。さまざまな草の根的活動から多様な情報資源が作り出されるインターネット環境においては、標準規格に基づくトップダウンで厳密な相互利用性だけではなく、ボトムアップでより緩やかな相互利用性が求められると考えられる。
以下、本報告では、3.6.2節で1990年代に進められたDLに関するいろいろな研究開発活動について概観し、簡単にまとめる。3.6.3節では、Dublin
Coreの解説とメタデータに関して今後求められると考えられる視点について述べる。3.6.4節ではinteroperabilityに関して簡単に考察する。なお、報告者は本ワーキンググループのこれまでの報告書でDLやメタデータに関して多く述べてきた。そのため、本報告では詳しい内容については以前の報告を参照するのみにとどめる[5]。
3.6.2 Digital Library
3.6.2.1 DLのための新しい技術の研究開発の活動
1990年代にはいくつものDLあるいはそれに関連する領域の研究助成プログラムが欧米で進められた。前述のDLIはそうしたものの代表格で、1994年からの4年間に進められたPhase
1(DLI-1)と1998年から始められたPhase 2(DLI-2)に分かれている。DLI-1では規模の大きな6プロジェクトが進められたのに対し、DLI-2では大きなものから小さなものまで数多くのプロジェクトが進められてきている。ヨーロッパでは、イギリスのeLibプログラムやドイツのGlobalInfoがあるほか、EUでの第5フレームワークの中のInformation
Societies Technology(IST)プログラムの中で研究助成が進められた。
DLIが持っていた特徴は、複数の研究助成母体による共同助成であったことと、計算科学、情報学の研究者、図書館や出版社といったコンテンツ所有者が参加するという異分野をつなぐプロジェクトであったことである。DLI-1では、NSFのほか、DARPAとNASAが研究助成母体として参加した。一方、DLI-2の場合、助成母体がNSF、DARPA、NASAに加えて、議会図書館(LoC)、人文基金(NEH)、医学図書館(NLM)に広がり、自然科学・技術分野から医学、人文社会科学分野までカバーしている。DLI-1は、計算機科学と情報学を基礎とするDLのための要素技術の研究を中心に進められた。一方、DLI-2はよりコンテンツ指向を強めている。また、ディジタル資料の長期保存といった図書館の基本機能に関するものもある。DLI-1のアナウンスがなされたのは1993年の後半である。これはNCSA
Mosaicが現れた時期と重なる。DLI-Iが開始されたのは、ちょうどWWWが爆発的に広がり始めた時期に重なる。これは、インターネットを用いて簡単に情報発信ができ、かつ大量の情報にアクセスができるということを、だれもが肌で感じることができるようになった時期であった。このことはDLI-1にとって幸運であったと思われるが、その一方、激しいネットワーク環境の中で研究を進めなければならない、大変な時期であったとも言えよう。これまでの報告の中でDLI-1およびDLI-2のプロジェクトについては触れているので、ここでは全体的な特徴についてのみ触れることにする[6]。
DL研究は、情報検索や自然言語処理、文書処理、データベースなどさまざまな要素情報技術を総合的に利用するための新しい技術の開発であると言える。そこでは、要素技術そのものの重要性はもちろんのこと、それらを対象コンテンツと組み合わせること、また、利用者に適した総合的な利用環境を提供することが強く求められるものである。
DLI-1の研究プロジェクト募集の資料[4][5]によると、研究領域が、(1)任意の形式のデータを取り込むための技術、(2)多様な情報に関する情報検索、フィルタリング、抄録作成などの技術、(3)多様でかつ大量の情報を扱うDLのためのネットワークプロトコルなどの技術、となっており、基本的に技術中心であることがわかる。一方、DLI-2の資料によると[6]、大枠として研究とテストベッド開発に分けられている。さらにこの「研究」が(1)人間中心分野として、ユーザインタフェースや情報発見のためのソフトウェアやモデルなど、情報を作り出し、探し、利用するという人間の活動を助けるための研究、(2)コンテンツおよびコレクション中心分野として、多様なデータの取り込み、メタデータ、相互運用性、分野依存の対象とそれを扱う技術といった情報資源を扱うための研究、(3)システム中心の分野として、多様でかつ大量の情報資源を多様な利用者対象と利用者環境において提供するための研究、の3分野に分けられている。また、DLI-2では国際間での共同プロジェクトを推進した。DLI-2では、違う視点を持つ研究者を集めることをより推進したと言える。これは1997年に開かれたSanta
FeでのワークショップのDLに関する研究戦略の議論の結果を反映したものである[7]。
DLI-2と並行して、NSFではDLに関連する分野の研究助成として2つのプログラムが始められた。ひとつはInformation Technology
Research(ITR)[8]であり、情報技術一般の研究を対象とする非常に大きなプログラムである。もうひとつがNational SMETE Digital
Library(NSDL)である。DLI-2の一部はNSDLのプロジェクトとして進められている。インターネットの教育利用に関しては、K-12[7]として広く進められてきており、大学学部レベルでの教育とあわせてK-16といわれることもある。現在、あちこちの大学で遠隔学習プログラムの提供が進んでおり、インターネットを利用した学習、教育は重要なトピックとなっている。そうした状況においてNSDLの果たす役割は大きいと感じる。
3.6.2.2 図書館を基礎としたディジタルライブラリの開発
従来、研究は大学や研究所に所属しないと困難であるとされてきた。研究に必要な資料を持つ図書館が近くにないと研究が進められない、というのがその理由の1つである。図書館(あるいは図書館のようなサービス)が研究者にとって重要であることは、従来とまったく変化していない。しかしながら、インターネット上での情報流通の発達によって、図書館に行く前に(あるいは行かずに)、インターネットで情報を探すということが一般化してきていると思える。もちろん、行動パターンの違いは分野や個人に依存するところが大きいことは言うまでもないが、こうした傾向は先端的な自然科学・技術分野でより顕著であるように感じられる。こうした環境下、この10年の間に図書館での電子的な情報環境は、大学図書館を中心として大きく変化してきた。現在では、多くの図書館がホームページを持ち、図書検索サービスなどを提供している。図書館におけるDLサービスの典型的な機能を下に並べる。
(1) 電子的に出版される資料の提供(典型的なものは電子雑誌やデータベース)
(2) 貴重資料や歴史資料の電子化と提供
(3) 大学など図書館が所属する組織・機関から出版されるさまざまな情報資源の電子化とアクセスの支援
(4) インターネット上の情報資源へのアクセス支援
(5) ネットワークを介したレファレンスサービス
(6) 電子化資料の長期保存
(7) 図書館内外におけるDL機能を利用した総合的な利用環境の整備
以上の項目に関して簡単に考察したい。
(1) 電子的に出版される資料の提供
電子的に出版される資料の提供は、出版物を利用者に提供するという意味では図書館としてごく基本的な機能である。学術雑誌の電子出版の発展とともに最近では数千タイトルの雑誌を提供する大学図書館も普通になってきている。一方、小規模の学会などでは、独自に電子ジャーナルに対応することが必ずしも容易ではない。遡及的な電子化や電子ジャーナルの長期保存などの問題がある。
(2) 貴重資料や歴史資料の電子化と提供
貴重資料や歴史資料の電子化は、図書館がもつ貴重資料そのものへのアクセスを制限する一方、電子的な複製物によりアクセス性を飛躍的に高めるという、「保存とアクセス」の両方の観点から進められてきている。また、電子化はこれからも進められていくと思われる。一方、電子化された資料が実際に役に立つかどうかについても十分に考慮されないといけない。単に、電子化しインターネット上で提供するだけではなく、教育利用での利用性の促進や評価、DLI-2に見られるような新しい情報技術との組み合わせによる新しい分野の開拓といった活動が求められる。
(3) 大学などから出版されるさまざまな情報資源の電子化とアクセスの支援
大学などの組織が出版する情報資源の電子化とアクセス支援は発信とアクセスの両面での技術が求められる。例えば、資料の電子化のために適切な技術を選ぶこと、資料に適切なメタデータを与え組織化することが求められる。また、発信される情報を再利用するための技術も求められる。大学や研究所といった組織に限らず、電子政府のような、巨大な情報発信元を想定してみるとこうした機能の必要性が理解しやすい。
(4) インターネット上の情報資源へのアクセス支援
インターネット上での情報資源アクセスを効率的に行うためのポータルサイトあるいはゲートウェイサイトの重要性は広く認められている。実際にこうしたサービスを実現するには、「有用な情報資源」あるいは「高品質な情報資源」を見つけ、それらに対して利用者にとって有用な情報を持つ高品質なメタデータを記述し、それらを適切にメンテナンスすることが求められる。しかしながら、現状ではこれらの多くが人手に頼らざるを得ない。
(5) ネットワークを介したレファレンスサービス
レファレンスサービスは、図書館員によるサービスであり、これをネットワーク上で提供しようという取り組みが進められている[9][10]。レファレンスサービスには、質問者が何を聞きたいのかを明確化することなども必要とされる人間主体の作業である。そのため、サービスそのものを機械化することは困難であると思えるが、リファレンスサービスを支えるための環境を作り上げることが、DLの研究開発にとって重要であることは疑えない。
(6) 電子化資料の長期保存
資料の長期保存は図書館の機能としては基本的なものである。ところが、情報媒体技術の進化の激しさは、電子媒体に蓄積された資料、特にもともと電子的に蓄積された資料(Born
Digital)の長期にわたる保存を難しくしている。アメリカ議会図書館の場合、ディジタル資料の長期保存が重要課題として報告されており[11]、また議会からそうした課題を中心としてDLをさらに開発するための大きな予算を与えられている。
(7) 図書館内外におけるDL機能を利用した総合的な利用環境の整備
図書館内の計算機とネットワークの環境は、この10年で大きく変わってしまったように思われる。公共図書館ではまだこれからであるかもしれないが、大学図書館では、端末用のパソコンがずらっと並んでいることはもう珍しくない。図書館内外(あるいはキャンパス内外)での利用環境の違いを少なくしていくための技術や制度が求められると思われる。
全体を通して、この10年間でずいぶん図書館および利用者の情報環境は変化したことは間違いない。一方、諸外国と比較してわが国を見た場合、図書館とそれ以外、特に研究開発部門との連携が弱いと感じられる。また図書館間での連携も弱いように感じる。研究開発能力を高めるためには必要な情報が容易に手に入ることが必要であることは言うまでもない。例えば、アメリカの場合、Digital
Library Federationという組織が早くから作られ、情報の共有やプロジェクトを進める母体にもなっている。わが国を見ると、コンテンツをより使いやすくするための環境整備に十分な手当がなされていないように感じる。
3.6.2.3 ディジタルライブラリに関するその他の話題、取り組み
インターネット環境における新しい取り組みとしていくつか興味深いものがあるのでそれを紹介したい。最初のものは、プレプリント、テクニカルレポート、学位論文などを電子的に作られた資源を蓄積提供するサービス(リポジトリ)による協調プロジェクトであるOpen
Archives Initiative(OAI)である[12]。これは別個に作り上げられてきたサービス間でコンテンツを協調的に提供する環境を作り出すことを目指しており、例えば資源に関するメタデータの収集(metadata
harvesting)のためのプロトコルを決めている。このプロジェクトは、複数のリポジトリによる横断的な利用が可能になるのみならず、収集したメタデータを利用した付加価値サービスの可能性も含んでいる。
上のようなサービスの広がりは学術情報の流通経路を変える可能性を持っている。学術雑誌に掲載される論文が学術情報の中心であることは疑えない。ところが、学術雑誌の価格が高く、かつ学術領域の広がりとともに雑誌の数が増えていくことは大学図書館と研究者にとっては頭の痛い問題である。研究者にとっては学術雑誌に論文を掲載することが自身の業績評価につながる一方、研究者の大学の図書館がその雑誌を購入していない、あるいは購入の継続を打ち切ってしまい自分の論文が掲載された雑誌を図書館で読めない状況も出てくる可能性がある[8]。その一方、WWW上に無料で公開されるテクニカルレポートや学位論文などの学術情報資源はどんどん増えている。査読システムによってqualityは保証されるが手に入れにくい(高価な、あるいは限られた場所でしか利用することのできない)雑誌に掲載された論文と、qualityは自分で判断しなければならないがWWW上で容易に手に入れることのできる論文のどちらが本当に役に立つのか、といった問題に関する議論が必要なのであろう。
もう1つの話題は、電子資料の長期保存に関する取り組みである。これまで図書館や文書館では紙の資料を中心とした資料保存を行ってきた。先に述べた貴重資料の電子化のように「保存とアクセス」の両面から資料の電子化が進められる一方、電子媒体による出版の発展は電子出版物の保存という観点から、これまで以上に困難な問題をもたらしている。納本図書館である国立図書館、わが国の場合は国立国会図書館にとって、これは非常に大きな問題である。電子出版物は大きく分けてCD-ROMなどのパッケージに入れて出版されるものと、ネットワーク上で出版されるものがある。前者をパッケージ系出版物、後者をネットワーク系出版物と呼ぶことにする。パッケージ系出版物の場合、媒体技術の進歩が早いために蓄積媒体を利用するためのハードウェアがなくなってしまう可能性に対処しなければならない。パッケージ系、ネットワーク系いずれの場合も、コンテンツの利用に特別のソフトウェアあるいは利用環境が必要とされる場合、そうしたソフトウェア環境を稼動可能な状態で保存しつづけることが難しい。また、WWW上で提供される資料の場合、どのような資料を保存の対象とすべきかを決めること(保存対象範囲の定義)が必ずしも容易ではない。また、電子ジャーナルの場合、印刷物と異なり出版社はライセンスのみを提供することになるので実体の保存に対しだれが責任を持つのかといった問題が生じる。電子資料の保存に関してはコンテンツの内容的問題、知的財産権にかかわる問題など、社会制度的な問題もあるが、技術的にも克服しなければならない点が多くある。次に、電子資料の保存に関するいくつかの活動を紹介してみたい。
(1) DLI-2の中で進められているミシガン大学とリーズ大学(イギリス)の共同プロジェクトCAMiLEONはEmulationをベースにした電子資料の保存方法の開発を目的としている[13]。また、コーネル大学のプロジェクトPRISMでも電子化資料の保存を扱っている[14]。
(2) スタンフォード大学を中心として進められているプロジェクトLOCKSS(Lots of Copies Keep Stuff Safe)は、電子ジャーナルの保存のためにジャーナルへのアクセスのために用いられるPC上にコピーを残す仕組みを作り、それをネットワーク上の多数のPCで動作させることによって、実質的に資料を保存するという取り組みを進めている[15]。
(3) 北欧、オーストラリア他の国立図書館において、WWW上の出版物を収集し、保存する取り組みを進めている[16]。図書館によって、内容による選択的収集を行っている館と、内容によらない網羅的収集を行っている館がある。
(4) Alexa Internet社では、インターネット上の資料のアーカイブ作りを目的としてWWW上の資料をロボットで収集し、蓄積・提供するサービスInternet
Archiveを進めている[17]。ここでは、例えば「1999年のWWW上の資料」を探すことのできるサービスWayback Machineを提供している。しかしながら、動的に作成されるページやデータベースの中でしかアクセスできないページなどロボットによる自動収集の制約を含んでいる。
3.6.3 メタデータについて
3.6.3.1 メタデータとは
メタデータは簡単には「データに関するデータ(Data about Data)」と定義される。この定義に基づくと、目録、索引、抄録、シソーラスといったものから、資料の識別子、書評や内容のRatingまですべてメタデータに含めて考えることができる。利用者はインターネットやDL上で情報資源を見つけ出し、その内容を評価し、利用する。メタデータなしにはこうした操作を行うことは困難である。メタデータは従来の目録と同じものと(乱暴には)言うこともできるが、メタデータは内容とメディアの多様化、利用者と利用環境の変化などに対応するべく提案されてきているものである。例えば、図書館での目録は、基本的には、1冊の本、1タイトルの雑誌に対して付与されている。これは、図書館での資料の取り扱いの単位に対応する。一方、インターネット上では、単純にとらえるとURIが与えられる資料単位が操作の基本単位ということになり、図書館での資料とインターネット情報資源の違いが良く理解できる。また、メタデータに関して、記述の視点と利用の視点(例えば、情報資源の発見)の違いに留意する必要がある。記述の視点からは、できるだけ正確かつ詳細に対象資源に関する記述をすることが望まれる。利用の視点からは、一般の利用者による情報資源検索には詳細な情報が利用されることは少ない。また、異なる規則・基準に基づいて作られたメタデータを横断的に検索する場合やそれらを収集して利用する(metadata
harvesting)場合には詳細情報は必ずしも用いられない。
現在、応用に応じていろいろなメタデータ規則が提案されている。その一例を下に示す。
・ Dublin Core Metadata Element Set: インターネット上の情報資源の発見を目的として定義されたもの[18](昨年度までの報告書などに詳しい解説がある)。
・ IEEE Learning Object Metadata(IEEE LOM): 学習、教育情報資源に関するメタデータ。IMS、Ariadneなどで遠隔教育・学習分野で利用されている[19][20][21][22]。
・ MPEG-7: オーディオ・ビデオデータのためのメタデータ[23]
ほかに、政府行政情報、地理情報、環境情報、電子商取引、倫理的内容などいろいろな分野でのメタデータ開発が進められている。
3.6.3.2 Dublin Core Metadata Element Setについて
Dublin Core Metadata Element Set(DCMES)はインターネット上での情報資源の発見を目的として開発が進められてきたもので、現在いろいろな分野で応用が進められている。図書館や美術館・博物館での利用、教育情報資源への適用などが進められてきているほか、ヨーロッパ各国での政府情報のためのメタデータとして利用されている[9]。欧米を中心として標準規格化が進んでいる[10]。わが国でも大学図書館を中心として利用が進んできており、国立国会図書館、国立情報学研究所でもネットワーク情報資源のためのメタデータ規則として適用している[24]。また、昨年10月東京で第9回のDublin
Core Workshopを、規模を拡大した国際会議として開催した[11]。
報告者は、これまでDublin Coreは昨年度までの報告書などで紹介してきたのでここでは詳しく述べず、Dublin Coreの基本的な考え方と利用の現状について述べる。なお、基本となる15エレメントについては表
3.6-1に示す。
*基本概念
(1)「情報資源の発見」のためのメタデータ
DCMESは情報資源を発見するためのメタデータ、すなわち利用者が情報資源を探すための情報資源の記述データを提供することが本来の目的である。「情報資源の記述」という観点から見ると、できるだけ詳細に定義されたメタデータエレメントや厳密な意味定義のなされた統制語彙に基づく記述が望ましいように思われる。しかしながら、利用者の観点からは、情報資源を探すために詳細な記述を用いることは多くない。そのため、情報資源の発見の観点から、できるだけ基本的な内容のエレメントからなるメタデータ記述規則を決める努力がなされてきた。
(2)コア・メタデータ・エレメント・セット(Core Metadata Element Set)
報告者はコア(Core)ということばが大きな意味を持っていると理解している。ネットワーク上にはさまざまな分野の、さまざまな種類の、さまざまな目的で作られた情報資源がある。これらに共通に適用できるメタデータ記述規則を作るには、それぞれの分野や目的で必要とされるエレメントをすべて含むように定義する方法と、すべての分野や目的で共通に利用可能であると考えられるエレメントのみを含むように定義する方法がある。前者の方法をとると巨大な規則を作ることになり、実現性に疑問がある。Dublin
Coreは後者の方法をとったものである。
| 要素名 | identifier | 定義および説明 |
| タイトル | Title | 情報資源に与えられた名前。 |
| 作成者 | Creator | 情報資源の内容の作成に主たる責任を持つ実体。 |
| 主題およびキーワード | Subject | 情報資源の内容のトピック。 |
| 内容記述 | Description | 情報資源の内容の記述。 |
| 公開者(出版者) | Publisher | 情報資源を利用可能にすることに対して責任を持つ実体。 |
| 寄与者 | Contributor | 情報資源の内容への寄与に対して責任を持つ実体。 |
| 日付 | Date | 情報資源のライフサイクルにおける何らかの事象に対して関連づけられた日付。 |
| 資源タイプ | Type | 情報資源の内容の性質もしくはジャンル。 |
| 形式 | Format | 物理的表現形式ないしディジタル形式での表現形式。 |
| 資源識別子 | Identifier | 与えられた環境において一意に定まる情報資源に対する参照。 |
| 情報源(出処) | Source | 現在の情報資源が作り出される源になった情報資源への参照。 |
| 言語 | Language | 当該情報資源の内容の言語。 |
| 関係 | Relation | 関連情報資源への参照。 |
| 対象範囲 (空間的・時間的) |
Coverage | 情報資源の内容が表す範囲あるいは領域。 |
| 権利管理 | Rights | 情報資源に含まれる、ないしはかかわる権利に関する情報。 |
(3)Simple Dublin Core(Simple DC)とQualified Dublin Core(Qualified DC)
Dublin Coreの開発において、はじめ13の基本エレメントエレメントからなるエレメントセットが合意され、その後15エレメントに定義しなおされた。これがSimple
DCと呼ばれるもので、現在までにANSIなどの標準規格となっているものである。一方、この開発過程で、詳細な記述のための限定子(qualifier)に関する議論が行われてきた。この過程では、「エレメントをより詳細に表す」といっても基本的な性質が異なるものがあることが明確化されてきた。例えば、作成者を詳細(あるいは正確に)表す方法として、正確な記述のための典拠ファイルのレコード名など作成者に与えられたユニークな識別子で記述する方法と、作成者の名前、所属、連絡先などの組で記述する方法がある。前者の場合にはどのような典拠ファイルを使っているのか、あるいはどのような統制語彙を用いて表しているのかを示す必要がある。後者の場合、作成者である人(あるいは組織)を表す値の構造、すなわち下位のエレメント(サブエレメント)の定義が必要である。このほか、「詳細に表す」ということには、「作成者」の意味が小説や論文の「著者」であるのか、「作曲家」あるいは「作詞家」であるのかといった、エレメントの意味の詳細化の場合がある。Dublin
Coreでは値の表現形式に関する指定(すなわち統制語彙やデータ形式)を指示するもの(Encoding Scheme qualifier、コード化スキーム限定子)と、エレメントの意味の詳細化を表すもの(Element
Refinement qualifier、エレメント詳細化限定子)の2種類の限定子を持っている。一方、上のサブエレメントに対応するものは限定子としては含まれていない。これは、作成者に関するサブエレメントを、人を表すためのエレメントセットと理解できる。すなわち、サブエレメントの場合は、別個のエレメントセットとして定義することができる。このようにして定義された限定子を含むDCMESがQualified
DCと呼ばれる。限定子の定義については平成12年度の報告書に示しているのでここでは省略する。
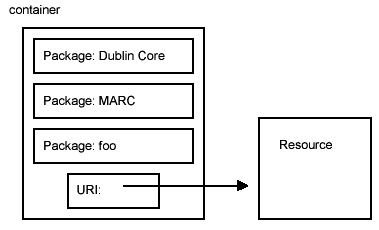
(4)Warwick Framework
1996年春にイギリスのウォーリックで開催された第2回のワークショップで提案されたWarwick FrameworkはDublin Coreの位置づけとネットワーク上でのメタデータのとらえかたの上で大きな役割を果たしている。Warwick
Frameworkは図 3.6-1に示す概念的なモデルを与える。Warwick Frameworkは複数のメタデータ規則による記述(パッケージと呼ぶ)をひとつの入れ物(コンテナ)に入れ、まとめるというものである。MARCなどの従来の目録規則では、それ自身で閉じたものとして定義されてきたが、インターネット上での情報資源や利用方法の多様性に対応するには、単一の規則のみで記述することをせず、いくつかの記述規則を利用してひとつのメタデータを記述する枠組みを与えている。この考え方は、WWWコンソーシアムのResource
Description Framework(RDF)の考え方に影響を与えている。
図 3.6-1 Warwick Framework
*Dublin Coreの利用
(5)Dublin Coreの適用方法
現在、DCMI推奨となっているメタデータの記述要素はSimple DCの15エレメントとDCMI推奨限定子、およびDCMI Type Vocabularyである。一方、これまでDublin
Coreはいろいろな応用に利用されてきている。こうした応用では、推奨エレメント・限定子に加え、それぞれの目的に則して独自の拡張がなされていることが多い。例えば、国立国会図書館のメタデータ規則の場合、主題の記述のためにNDCが限定子として利用されているが、NDCはDCMIの推奨限定子には含まれてはいない。また、Open
Archives Initiativeに見られるように、異なるメタデータ規則の下に作られたメタデータの共通部分としてDublin Coreを利用することもある。一般に、メタデータの記述の際にはできるだけ「高品質な記述」が求められる。「高品質な記述」には、できるだけ詳細であること、できるだけ内容の記述が統制されていることが含意されている。一方、前にも述べたように情報資源の発見の側からは、あまりに厳密な規則はエンドユーザには意味のないものである。
(6) Dublin Coreの具体的な記述形式
DCMIでは具体的な記述形式の定義をHTML以外には積極的には進めてこなかった。その理由は、記述形式の定義を進めることによってエレメントの意味定義に影響が出る可能性を避けたためである。一方、Dublin
Coreを利用して作られた応用サービスでは、それぞれのシステム構成に応じた表現方法が用いられている。現在、DCMIでは、XMLおよびRDFでの記述形式の定義を進めている。
(7) 新しいエレメントや限定子の導入
上に述べたように実際の応用においては、必要に応じたエレメントや限定子の導入がなされている。一方、DCMIの中でも新しいエレメントや限定子の導入が進められている。例えば、教育分野での利用に関して、どのような利用者に適した資源であるのかを記述するためのaudienceエレメントやそれに関連する限定子が提案されている。政府情報や図書館への適用に関しても同様に議論が進められている。
(8)エレメントセットとアプリケーションプロファイル
Simple DCでは15のエレメントの定義に加えて、「すべてのエレメントは省略可能(Optional)であり、かつ繰り返し可能(Repeatable)である」と定義している。これに対して図書館でのDublin
Coreの利用に関するワーキンググループ(DC-Libraries)では、図書館での利用では、例えば「タイトルエレメントは必須、主題エレメントは適用可能な場合必須、内容エレメントは記述を推奨」というように提案している。こうした応用ごとの適用規則をアプリケーションプロファイル(application
profile)と呼んでいる。そこで、メタデータ規則をエレメントセットとアプリケーションプロファイルに分けて定義しなおすことにする。エレメントセットはエレメントや限定子など、メタデータとして対象情報資源の性質を記述するための語彙とその意味を定めるものであり、アプリケーションプロファイルはエレメントセットを対象分野に適用する際に定める適用規則である。例えば、Simple
DCの定義は、15エレメントの名前とその意味の定義に加え、「すべてのエレメントは省略可能(Optional)であり、かつ繰り返し可能(Repeatable)である」としている。この場合、15エレメントの定義がエレメントセット、15エレメントに関して省略可能かつ繰り返し可能と定義している部分がアプリケーションプロファイルということができる。また、アプリケーションプロファイルは複数のエレメントセットをもとにして定義することも可能である(図
3.6-2参照)。
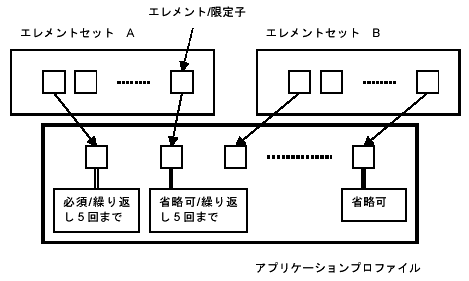
図 3.6-2 エレメントセットとアプリケーションプロファイル
*Dublin Coreの開発と維持
(9) Dublin Core Metadata Initiative(DCMI)
Dublin Coreの開発は、OCLCによる支援の下に草の根参加者によって進められてきた。Dublin Coreの開発の初期の段階ではOCLCやNSF他の助成の下で進められてきたが、Simple
DCの合意が得られ標準化を進める必要が出てきたころからDCMESの開発と維持の活動を行う組織を明確にする必要が出てきた。そのため、Dublin Core開発を支えてきたOCLCがホストする形でDCMIと呼ばれる組織が1999年ごろから構成されてきた。その後Dublin
Coreの利用がさまざまな分野で広がるにつれ、新しいエレメントや限定子の導入をも含めたDCMESの維持、地域ごとのコミュニティによるDublin CoreのLocalizationなどいろいろな活動の必要性がでてきた。こうした将来の活動に向け、現在DCMIの再編成が進められている。
(10) 限定子の拡張とDumb-Down(ダム・ダウン)原則
上に示したように、分野や応用に応じた限定子が導入されている。限定子が無秩序に定義されるのを防ぎ、Dublin Coreとしての相互利用性を保つため、DCMIでは限定子の導入に関する基本原則を決めている。これはDumb-Down原則と呼ばれるもので、「限定子つきの表現から限定子を取り除いても、当該エレメントとその値の間で矛盾が生じてはならない」というものである。例えば、「有効になった日付(Date
Valid)は3月20日である」(エレメント: 日付(Date)、限定子: 有効になった(Valid)、値: 3月20日)から「有効になった(Valid)」という限定子を取り除いて「日付(Date)は3月20日である」としても、矛盾は生じない。一方、サブエレメントの場合を考えてみよう。例えば、「作成者の名前は杉本重雄、所属は図書館情報大学」(エレメント:
作成者(Creator)、限定子: 名前と所属、値: 杉本重雄と図書館情報大学)の場合、限定子を取り除くと「作成者は杉本重雄、図書館情報大学」となり、図書館情報大学が作成者になってしまうので矛盾する。この例から、先に述べた値の構造を表す限定子(サブエレメント)が一般的にはDumb-down可能ではないことが理解でき、Qualified
DCの中に含まれていない理由がわかる。
(11) 分野や地域によるコミュニティ
これまでの開発においてはDCMIの場での標準作りと応用ごとのDCMESの適用が行われてきたが、今後は政府情報や教育情報といった応用分野の要求に基づく開発、地域ごとの要求、特に英語圏以外の要求に基づく開発が進むと考えられる。また、DCMESの各国語への翻訳、各国での標準の維持なども求められる。こうした活動を進めるには分野や地域ごとのコミュニティを作り上げる必要がある。
(12) わが国での状況
わが国では、大学図書館を中心にDublin Coreの利用が広まってきており、日本語で書かれた情報資源に対するメタデータの記述方法に関する知見も蓄積されてきている。また、Dublin
Coreの国際会議(DC-2001)として東京の国立情報学研究所で開催した。しかしながら、現時点ではJISによる標準化はまだ行われていない。日本語あるいは日本の情報資源のためのエレメントや限定子などに関する議論や意見交換を行うための組織作りが求められている。
3.6.3.3 メタデータ規則の利用
ネットワーク上には多様な情報資源が提供されると同時に、それらの利用目的、利用方法、利用環境も多様である。このことは、ひとつの情報資源であってもいろいろな視点からメタデータを付与することの必要性を意味する。例えば、教材として利用するビデオ資料の場合、教育資料としてのメタデータとビデオデータとしてのメタデータの両方が求められる。ネットワーク上での情報資料検索の場合、政府関係資料や地理情報資料というように分野を特化して利用する場合はそれぞれの資料向けのメタデータが望ましいが、広い範囲から資料を探す場合はDublin
Coreのようなコアメタデータが望ましい。また、メタデータの記述対象のとらえ方もさまざまである。Dublin Coreの場合は、情報資源を対象とし、情報資源を扱う主体は視野の外である。IFLAのFRBRモデルでは、対象をwork(知的生産物のもともとの内容)、expression(知的生産物を何らかの表現手法により表したもの)、manifestation(出版物として知的生産物を実体化したもの)、item(出版物の1点)の4段階でとらえている[25]。電子商取引用のindecsの場合、人(people)、物(stuff)、取引(deal)が記述対象となる[26]。LagozeらによるABC
metadata modelではイベントを重要な要素としてとらえている[27]。
ネットワーク上ではいくつものデータベースに対する横断的な検索が有用である。例えば、Z39.50は分散環境上での横断的検索に広く利用されているプロトコルである。横断検索を実現するには、共通のメタデータ規則の下に検索質問を受けつけることが必要であり、そのため、メタデータ規則間あるいはメタデータエレメント間の対応関係の定義(Crosswalk)が必要とされる。Crosswalkをできるだけ機械的に作成、維持することが求められる。
WWWコンソーシアムによるResource Description FrameworkはWWW上でのメタデータ記述のための共通基盤を提供するための取り組みである。RDFはModel
and SyntaxとSchemaの2つに分かれている。前者はメタデータ記述のための構文とその基になるモデルを定義し、後者はメタデータのエレメントや限定子などメタデータ規則に含まれる語彙の定義を与える仕組みを定義している。その後のSemantic
Webの取り組みは、WWW上での情報流通のための意味的基盤を与えようというものであるが、現時点での中心は、RDF Schemaによるメタデータを表す属性の語彙の定義を含め、WWW上での情報交換のための語彙の定義(ontologyあるいはvocabulary)が中心的な話題となっているようである。Dublin
Coreにおいても、メタデータを記述するための統制された語彙に関する議論は多くあり、こうした問題は古くて新しい問題の1つのようである。
先に述べたようにネットワーク上でいろいろなメタデータ規則が用いられる。Dublin Coreの範囲内で見てもいろいろな拡張がなされている。メタデータの流通性、相互利用性を高めるには、メタデータ規則に関する情報の流通性を高めることが求められる。そのため、メタデータ規則を登録し、提供するサービスであるメタデータスキーマレジストリ(あるいは、メタデータレジストリ)の重要性が認められている。例えば、EUのSchemasプロジェクトでは多数のメタデータ規則を収集、登録している[28]。図書館情報大学ではDCMESを中心として多言語によるメタデータレジストリを実現している[29]。DCMIでもレジストリに関するワーキンググループを作り、DCMIレジストリの構築を進めている。メタデータレジストリは、単にエレメントや限定子の定義の参照記述を人間が見るためだけに限らず、エレメントや限定子に対し、ネットワーク上で一意に定まる識別子を与えることでエレメントなどの意味定義の基底を与えること、エレメントなどを長期にわたって維持管理するための基盤となることが期待される。さらに、新しいエレメントや限定子を定義する上で参考となる情報を与えるといった付加価値サービスを行うことができると考えられる。
3.6.4 Interoperability
Interoperability(相互運用性、相互利用性)はDLにおける重要なトピックのひとつである。1997年から98年にかけて進められたEUとNSFの共同助成によるDLの研究戦略を議論するワーキンググループにおいてもinteroperabilityは主要なトピックとして議論がなされた[30]。Interoperabilityに関するワーキンググループの報告書[31]の中で階層的なモデルを提案し、ネットワーク上に分散したDL間でのinteroperabilityを実現するための課題について議論している。
Dublin CoreではSemantic Interoperabilityということばキーワードとして用いられてきた。直訳すると意味的相互運用性である。これは「特定の表現形式に依存することなくメタデータを記述するエレメントの意味(だけ)を決め、意味的な相互利用性を保とう」というものである。Dublin
Coreでは、HTMLによる基本的な記述形式を除いては具体的な表現形式に関する議論はほとんど行われてこなかった。表現形式に関する議論を避けてきた背景には、意味と表現形式の議論は必ずしもうまく切り分けられないためエレメント定義を進める過程において表現形式に関する議論に引っ張られることを避ける必要があったこと、具体的な表現形式はシステムの実現方法に負うところが大きいことがある。また、エレメントの意味定義に関する合意が形式定義のために損なわれることを避けたためであるとも言える。
2001年6月に開催されたJoint Conference on Digital Libraries 2001(JCDL '01)のClifford
Lynchによる基調講演はinteroperabilityをテーマとするものであった。同氏は講演の中で、Dumb-Down(ダムダウン)原則とOpen
Archives Initiative(OAI)に触れていた。Dumb-Down原則は、詳細レベルでのinteroperabilityが保証できないときに記述の詳細度を落とすことでinteroperabilityを守るための原則を与えている。また、OAIのmetadata
harvestingは、個別に定義されたメタデータを横断的に収集するためのプロトコルを決めている。そこでは共通のエレメントを決める必要があり、Dublin
Coreを基礎とするエレメントを決めている。
Lynchの基調講演の際に、ミシガン大学教授のMargaret Hedstromから「Digital Libraryにおける重要な課題であるディジタル資料の保存(Preservation)は時間的相互運用性(Temporal
Interoperability)と言ってもよいのではないか。」という指摘があり、Lynchもそれに同意していた。ディジタル資料の保存には、何らかの媒体に蓄積された資料の保存だけではなく、資料を利用するための技術も保存する必要がある。ところが、技術の進歩の速さは技術の保存を困難にしている。資料を利用するために必要なハードウェアやソフトウェア技術が消えてしまうことによる資料の実質的消失は大きな問題として広く認識されている。
Hedstromは「マイクロフィルムによる保存は原資料の機能をすべて保存しているものではなく、それと同じことがディジタル資料にも当てはまってもよいのではないか。作られたときとまったく同じ状態で、技術とともに保存しなければならないものばかりとは限らない」と述べている[12]。ディジタル資料の保存のために、時を越えてどのような精度のinteroperabilityを求めるかが現実的な課題であることが理解できる。資料保存というと、1次コンテンツをいかに保存するかにのみ注目が向きがちであるが、利用された技術、コンテンツの保存履歴などメタデータとして記録し、保存する必要があることは言うまでもない。
メタデータのコミュニティからはontologyということばが良く聞こえてくる。大規模知識ベースなどのAI指向のコミュニティで続けてこられたものが、ネットワーク上での意味的なinteroperabilityの必要性とともに(再び?)注目されたものと理解している。上のEU-NSFワーキンググループでもInformation
Modelとしてontologyに関する議論をしている。一方、もともと図書館分野では統制語彙が広く用いられてきたので、それ自身は新しいひびきはあまりない。しかしながら、これまでの統制語彙(あるいはそのために作られたシソーラスや辞書)が、いわば閉じた世界での利用を前提としていたのに対し、ネットワーク上では異なる語彙の基に作られたデータ(あるいはデータベース)間でのinteroperability、いわば開かれた世界でのinteroperabilityがより重要になる。
話題をDublin Coreに戻したい。Dublin Coreの議論の中で、interoperabilityの観点から重要であると考えられるトピックに、上に示したDumb-down原則のほかにエレメントセットとアプリケーションプロファイルの分離とメタデータスキーマレジストリがある。エレメントセットとアプリケーションプロファイルを別々に考えることはエレメントおよび限定子の意味定義と、応用に適用する際の記述上の規約を分離したととらえることができる。両者を分離することでCrosswalkの作成やDumb-downのための基礎となるメタデータ規則の定義がより明確にできる。先に示したように、メタデータスキーマレジストリはメタデータのinteroperabilityのために重要な役割を持っている。Dublin
Coreのレジストリの場合で考えると、namespaceの管理、各国語訳と英語で記されたオリジナルの記述との間の管理、継続的な開発に伴う版の更新といった点でレジストリの果たす役割は大きい。
現在のインターネットでは、さまざまなコミュニティによって多様な情報資源が発信され、蓄積されている。言語、文化、分野の違いを越えて相互に情報資源を利用できるようにすること、また時間を越えて情報資源の利用性を保つことの重要性は明らかである。コミュニティごとの高い自由度を保ちつつ、コミュニティ間のinteroperabilityが求められると言える。しかしながら、これを実現することは必ずしも容易なことではない。従来interoperabilityを得るためには詳細に決められたプロトコルに従うことが前提であったように思うが、Dumb-down原則やtemporal
interoperabilityの議論にもあるように、緩やかな相互利用性・相互運用性についても理解を深める必要があるように感じる。
3.6.5 おわりに
国家情報基盤(National Information Infrastructure)、世界情報基盤(Global Information Infrastructure)ということばとともに1990年代のはじめから半ばにかけて、DLに関する研究開発が大きな期待とともに始められた。WWWの爆発的な広がりとともに、我々の情報環境は急激に変化した。例えば、現在、報告者自身の研究活動はインターネットおよびインターネット上のいろいろなツールなしにはまったく成り立たない。DLという分野がインターネットに密接に関連したものであることが理由の1つではあろうが、研究者一般についてかなり共通していることであるとも思う。本報告の執筆にあたって、雑誌や論文集の論文、種々の報告書など、ほとんどインターネット経由で得ることができた。その中にはかなり1992-93年に作られたものも有り、この分野では「古い」資料も含まれている。
図書館現場でのDLサービスもこの5、6年でかなり進んだと思われる。例えば、大学図書館で提供される電子ジャーナルのタイトル数も最近では非常に増加した。それでも「電子図書館
= 歴史資料の電子化」というイメージがいまだに強いようにも感じる。このイメージだけでとらえられたままでは、DLとしては失敗なのであろう。図書館(あるいはそれに似た機能を持つ組織)はネットワーク上での出版、情報流通の増加に対応した中継ぎとしてのサービスを提供することが基本であると思う。その一方で図書館自身による情報資源の開発と提供が求められていることも確かである。求められる機能として重要なものに、サブジェクトゲートウェイやネットワーク上でのリファレンスサービスなど情報資源へのアクセス支援サービスがある。こうしたサービスは人手中心に進められている一方、こうしたサービスの実現を支援するための情報技術は十分であるとはいえない。先に、述べた資料の長期保存技術とともにこうした情報技術の開発が望まれる。
DL分野はいろいろな要素情報技術を総合的に応用することが求められる分野である。EU-NSF共同のDLの研究戦略に関するワーキンググループで選ばれた5分野(知的財産権、Interoperability、情報発見、メタデータ、多言語情報アクセス)は、グループの活動から4年ほどたつが、これらが情報技術の観点から見たDLの重要な基盤分野であることは今も変わっていないと思う。DLI-1とDLI-2を比較すると、DLI-1では各プロジェクトの中でいろいろな要素情報技術の研究が見られたのに対し、DLI-2の方がよりコンテンツ指向であると考えられる。これは特定の応用分野のコンテンツとそれに適した情報技術開発を組み合わせた中小規模のプロジェクトが多いためでもあろう。また、DLI-2にはディジタル資料の長期保存やサブジェクトゲートウェイ関連の技術開発など、DLI-1が行われていた間のWWWの発展と電子的な情報資源の急激な増加によって必要性が明確になったものも含まれている。こうした点がDL分野の特徴を表しているともいえよう。また、教育・学習(e-Learning、遠隔学習、遠隔教育)、電子政府、電子商取引など隣接分野でのDLのための技術や知識の適用も重要な話題であると考えられる。
最後に、メタデータ分野の観点から、DLにおいて重要と思われる点をいくつか挙げてみたい。
(1) 多様なinteroperabilityとメタデータ規則の流通
ネットワーク上では、それぞれの応用にあわせて規則を決めることのできる自由度が求められる一方、地理的距離、時間的距離、言語や文化の違い、分野の違いを超えてネットワーク上で相互にデータやサービスを利用し合うための共通性が同時に求められる。そこではいろいろなレベルでの相互利用性が求められることになる。同時に、そうしたinteroperabilityを支えるにはメタデータ規則(メタデータスキーマ)をネットワーク上で流通させる仕組みが重要である。
(2) メタデータを作り、維持するための技術
現時点では高品質であることを求められるメタデータの作成には人手がかかる。また、そうしたメタデータを作成する対象を選定すること、すなわちある程度のコストをかけてもメタデータを作る価値がある情報資源であると判断することにもコストがかかる。加えて、ネットワーク情報資源の特性として内容の更新が容易であるという点がある。この点はメタデータの維持管理を難しくしている。こうした点に対する情報技術開発が望まれる。
(3) 多言語メタデータ
言うまでもなくインターネット上では多様な言語が利用されており、多言語情報アクセスのための情報技術はメタデータの作成や利用においても重要である。
参考文献
| [1] | Digital Library Initiatives, http://www.dli2.nsf.gov/ (DLI-2のホームページ。DLI-1へのリンクもある). |
| [2] | NSDL, http://www.ehr.nsf.gov/EHR/DUE/programs/nsdl/ (http://www.smete.org/も参考). |
| [3] | NSF-EU Collaboration, http://www.iei.pi.cnr.it/DELOS/NSF/nsf.htm |
| [4] | NSF 93-141 - Research on Digital Libraries, http://www.nsf.gov/pubs/stis1993/nsf93141/nsf93141.txt (Sep. 1993). |
| [5] | 杉本重雄: ディジタル図書館へのアプローチ - DL関連研究分野に関して, ディジタル図書館, No. 3, http://www.dl.ulis.ac.jp/DLjournal/No_3/05-sugimoto.html (Mar. 1995). |
| [6] | DIGITAL LIBRARIES INITIATIVE - PHASE II, http://www.nsf.gov/pubs/1998/nsf9863/nsf9863.htm (1998). |
| [7] | Report of the Santa Fe Planning Workshop on Distributed Knowledge Work Environment: Digital Libraries, http://www.si.umich.edu/SantaFe/ (Sep. 1997). |
| [8] | Information Technology Research, http://www.itr.nsf.gov/ |
| [9] | Internet Public Library, http://www.ipl.org/ |
| [10] | Collaborative Digital Reference Service, http://www.dl.ulis.ac.jp/DLjournal/No_3/05-sugimoto.html |
| [11] | Committee on an Information Technology Strategy for the Library of Congress, Computer Science and Telecommunications Board, National Research Council, LC21: A Digital Strategy for the Library of Congress, 238p., http://books.nap.edu/html/lc21/ (2000). |
| [12] | Open Archives Initiative, http://www.openarchives.org/ |
| [13] | CAMiLEON - Creating Ctreative Archiving at Michigan and Leeds: Emulating the Old on the New, http://www.si.umich.edu/CAMILEON/ |
| [14] | Information Integrity in Distributed Digital Libraries, http://www.prism.cornell.edu/ |
| [15] | LOCKSS Web Site, http://lockss.stanford.edu/index.html |
| [16] | PADI - Preserving Access to Digital Information (National Approaches), http://www.nla.gov.au/padi/topics/65.html |
| [17] | Internet Archive, http://www.archive.org/index.html |
| [18] | Dublin Core Metadata initiative, http://dublincore.org/ |
| [19] | ARIADNE - Alliance of Remote Instructional Authoring and Distribution Networks for Europe, http://www.ariadne-eu.org/ |
| [20] | IMS Global Learning Consortium, Inc., http://www.imsproject.org/ |
| [21] | 先端学習基盤協議会, http://www.alic.gr.jp/ |
| [22] | Greenberg, J. (ed.): Metadata and Organizing Educational Resources on the Internet, Haworth Press, 302p. (2000). |
| [23] | The MPEG Home Page, http://mpeg.telecomitalialab.com/ |
| [24] | ディジタル図書館, No. 22 (Mar. 2002) (http://www.dl.ulis.ac.jp/DLjournal/に掲載予定). |
| [25] | IFLA, Functional Requirements for Bibliographic Records, http://www.ifla.org/VII/s13/frbr/frbr.pdf (1998). |
| [26] | Rust, G.: The <indecs> metadata framework, http://www.indecs.org/pdf/framework.pdf (June 2000). |
| [27] | Lagoze, C. and Hunter, J.: The ABC Ontology and Model, Journal of Digital Information, Vol. 2, issue 2, http://jodi.ecs.soton.ac.uk/Articles/v02/i02/Lagoze/ (Nov. 2001). |
| [28] | Forum for Metadata Schema Implementers, http://www.schemas-forum.org/ |
| [29] | Nagamori M., et al.: A Multilingual Metadata Schema Registry Based on RDF Schema, Proceedings of International Conference on Dublin Core and Metadata Applications 2001, http://www.nii.ac.jp/dc2001/proceedings/product/paper-31.pdf |
| [30] | An International Research Agenda for Digital Libraries - Summary Report of the Series of Joint NSF-EU Working Groups on Future Directions for Digital Libraries Research, http://www.iei.pi.cnr.it/DELOS/NSF/Brussrep.htm (Oct. 1998). |
| [31] | Birmingham, W., et al.: EU-NSF Digital Library Working Group on Interoperability between Digital Libraries, http://www.iei.pi.cnr.it/DELOS/NSF/interop.htm (Oct. 1998). |
| [32] | Margaret Hedstrom: Digital Preservation: Problems and Prospects, ディジタル図書館, No. 20, pp. 3-15, http://www.dl.ulis.ac.jp/DLjournal/No_20/1-hedstrom/1-hedstrom.html (Mar. 2001). |
---------------
[1] 「図書館」ということばから、従来の建物ないしは施設を基盤としたサービスを連想させることが多い。ここでは機能中心に述べるため「館」という連想を避けるため「ディジタルライブラリ」と記している。
[2] SMETEはScience, Mathematics,
Engineering and Technology Educationに対応する。
[3] 以前はACMとIEEE-CSがそれぞれDigital
Libraryに関する国際会議を行っていたが、2001年からそれらが統合しJCDLとなった。http://www.jcdl.org/参照。
[4] 米国Coalition for Networked
InformationのExecutive Director。講演題目は"Interoperability: the Still-Unfulfilled
Promise of Networked Information"。
[5] 報告書のURLは、http://www.icot.or.jp/FTS/REPORTS/Report-index-J.html。
[6] DLI-1に関しては平成8年度の報告http://www.icot.or.jp/FTS/REPORTS/H8-reports/H08NAI-WG/H0903R1ch34.html#anchor-ch3-7、DLI-2およびNSDLに関しては平成12年度の報告http://www.icot.or.jp/FTS/REPORTS/H12-reports/H1303-AITEC-Report4/AITEC0103R4-html/AITEC0103R4-ch3-6.htmを参照。
[7] K-12はKindergarten to 12th
Gradeを意味し、幼稚園から高校までの教育におけるインターネット利用が進められている。
[8] 図書館における電子出版物(特に電子ジャーナル)の導入、提供などに関する種々の問題に関して知識と情報を共有し、意見交換をする取り組みが進められている。例えば、アメリカを中心とする国際的な取り組みであるSPARC(the
Scholarly Publishing and Academic Resource Coalition, http://www.arl.org/sparc/)、わが国での国立大学図書館協議会による取り組みなどがある。図書館での現実的な対応に関してはここでは触れない。
[9] DCMIのホームページからプロジェクト(http://dublincore.org/projects/)や政府情報のためのメタデータとしての採用例(http://dublincore.org/news/adoption/)を見ることができる。
[10] ヨーロッパ: CEN/ISSS CWA13874。アメリカ:
ANSI Z39.85。
[11] http://www.nii.ac.jp/dc2001/に会議の論文集がある。
[12] 図書館情報大学で開催した第20回ディジタル図書館ワークショップでの講演による[30]。