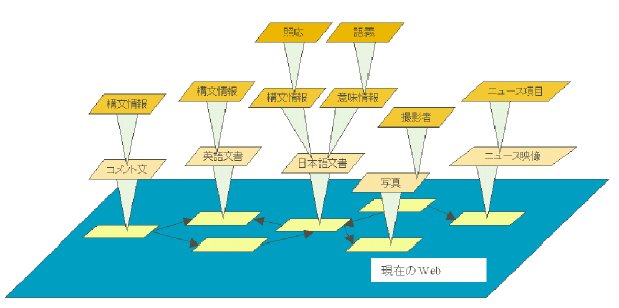
図 3.7-1 アノテーションによるWebコンテンツの拡張
報告者: 長尾確委員
3.7.1 デジタルコンテンツのトランスコーディング
デジタルコンテンツがあたりまえのものとして世の中に溢れ出したのは20世紀の情報技術の進歩からすると必然的であっただろう。そして、それら膨大なコンテンツを活用するための技術もさまざまなものが発明され、進歩をとげていくことは間違いがない。これまでは、ともかくコンテンツを作成して流通させることが主目的であったのに対し、これからは、それらのコンテンツをいかに賢く利用するか、あるいは、いかに多様に、多目的に利用するか、ということが最も重要な課題になると思われる。
コンテンツ技術には、デジタルコンテンツを作成・保存・伝達する技術のほかに変換・加工・再利用する技術も含まれる。本報告では、特に後者に力点を置いている。
デジタルコンテンツの変換・加工・再利用の形態には、例えば、パーソナライゼーションとアダプテーションがある。デジタル放送の映像やWebページなどのデジタルコンテンツをユーザの好みに応じて変換することをパーソナライゼーションと呼び、それらのコンテンツをPCやPDA(Personal
Digital Assistant)や携帯電話などのデバイスの特性に合わせて変換することをアダプテーションと呼ぶ。
本報告では、デジタルコンテンツのパーソナライゼーションとアダプテーションを合わせたものをトランスコーディングと呼ぶ。現状では、インターネットへのアクセスはPC経由で行われることが多い。しかし、この様相は近年、急激に変わりつつある。PCに加えて、携帯電話やPDA、テレビ、カーナビなどを使ってインターネットにアクセスする機会がますます増加するだろう。このとき重要となるものがトランスコーディングである。例えば、PCで表示することを前提にして作成したWebページを携帯電話などで表示する場合、画像の縮小やテキスト部分の圧縮といった操作を自動的に行う必要がある。トランスコーディングには、少ない伝送容量を使ってサーバからクライアントにコンテンツを配信できるという利点のほかに、ユーザの嗜好に応じた理解しやすいコンテンツを生成できるといった利点がある。
コンテンツプロバイダやサービスプロバイダは、それそれの機器に対応したコンテンツを個別に用意しなくても済む。具体的な応用例としては、PC向けWebコンテンツのトランスコーディングによって、携帯電話向けのコンテンツを生成するといった利用法がある。
図 3.7-1 アノテーションによるWebコンテンツの拡張
3.7.2 セマンティックトランスコーディング
このトランスコーディングをさらに進めて、テキストの要約などの内容に基づく処理の精度を高める工夫を盛り込んだのが、報告者の提案するセマンティックトランスコーディングである[8]。具体的には、コンテンツに含まれるテキスト文要素に言語的なアノテーション(補足情報)を加えることによって、要約や翻訳などの自然言語処理の精度を大きく向上させることができる。例えば、アノテーションによってコンテンツに含まれるテキスト文の意味を明確にすると、正確な要約や翻訳が期待できる。コンテンツにアノテーションをつける手間が増すが、重要な情報にはアノテーションをつけて正しく伝達し、共有すべきという考えに基づいている。このアノテーションはコンテンツの内容理解を促進するものと位置づけられる。現在、報告者らは原著者を含む多くの人々が文書の内容に関する補足的情報を付加できるような枠組み作りや、その情報を加味して文書を読者に適した形に加工する仕組み作りに取り組んでいる。
図 3.7-1で示されるように、アノテーションは、現在のWebに上位構造を作る基盤になる。現在のWebコンテンツが最下層で、アノテーションはコンテンツに情報をつけ加えるメタ(上位)コンテンツ、さらにメタコンテンツに対するメタコンテンツのように階層をなしている。
セマンティックトランスコーディングは、ユーザが指定したWeb上の新聞記事などのコンテンツを任意の圧縮率で要約して表示したり、テレビ番組などの映像データからユーザの好みに応じた話題だけを抜き出して、ダイジェスト映像を作成したりといったことを可能にする。さらに、要約したコンテンツを翻訳したり、テキストを音声化して聴いたりすることもできる。コンテンツサーバにおかれたテキスト、画像、音声、映像などのコンテンツはトランスコーディングプロキシによって、ユーザの使用するデバイス(PC、携帯電話、カーナビなど)や、ユーザの要求(概要をつかみたい、母国語で読みたい、声で聞きたい、など)に合わせて加工される。このとき、アノテーションと呼ばれる付加情報を用いて、より精度の高い要約・翻訳を行う。アノテーションはアノテーションサーバに蓄えられている。
セマンティックトランスコーディングの手法を使って、具体的にはHTML文書などのWebコンテンツがかかえる、以下の3つの課題を解消できるだろう。
Webは、新しいスタイルの文書のあり方を示したという点において革新的だったと言えるだろう。Webコンテンツの自由度の高さは疑いようがない。しかし、現状ではWebコンテンツを読者が読みやすいような体裁に機械的に変換することは非常に困難である。
図 3.7-1にあるように、従来のWebコンテンツは1枚の平面上に存在する要素群としてとらえることができる。セマンティックトランスコーディングでは、Webコンテンツを平面から立体に拡張する手法を提案する。コンテンツの各要素に意味や文書構造を示すアノテーションを付加する。このことによってWebコンテンツに、コンテンツの各要素の意味や文書構造を記述した上位構造を築くことができる。代表的なアノテーションの例としては、リンク元の文書に埋め込まれていないハイパーリンクである外部リンクや、コンテンツに対するコメントなどが挙げられる。アノテーションを作成して公開することが容易になれば、Webコンテンツの表現力は大幅に高まり、その利用価値が飛躍的に向上するだろう。
セマンティックトランスコーディングは、基本的にテキストコンテンツの処理を中心としたものであるが、その手法は映像や画像などの非テキストコンテンツの加工にも応用され、マルチメディアデータを含むコンテンツに適用できる。
3.7.3 アノテーションとトランスコーディング
さて、アノテーションあるいはメタデータに対するこれまでのさまざまな取り組みでは、コンテンツを高度化するという目的は共有しているが、コンテンツの検索や分類以外の具体的な目的への利用可能性についてあまり考慮されていない。これに対して報告者らのアプローチでは、特にトランスコーディングへの応用を目指し、いくつかのシステムをすでに実装し、実験を進めている。
セマンティックトランスコーディングで用いられるアノテーションには、大きく分けて3つの種類がある。テキスト文の言語構造などを付与する言語的アノテーション、画像やハイパーリンクなどのコンテンツを構成する各要素に対するコメントアノテーション、ビデオ映像などマルチメディアデータの意味的構造を記述するためのマルチメディアアノテーションがある。
具体的な応用例としては、Webページの要約や翻訳、レイアウト変換、「音声→テキスト」や「テキスト→音声」といった変換、映像から要約した映像への変換などが挙げられる。さらに、複数のコンテンツからユーザの好みに合った新規のコンテンツを生成するといった応用も視野に入っている。実際にアノテーションを付与する手法は、コンテンツの種類によって異なる。
3.7.3.1 アノテーションエディタ
コンテンツに効率良くアノテーション情報を付加するために、報告者らはアノテーションエディタと呼ばれるオーサリングツールを開発している。これをアノテーションデータの自動生成や編集に用いる。アノテーションエディタはJavaアプリケーションとしてユーザ側のクライアント上で利用できる。生成したアノテーションデータは、アノテーションサーバへ送信され、分類/格納される。
アノテーションデータの記述には、XMLを用いる。アノテーションを作成したWebページが更新された場合、更新前のアノテーションデータの再利用をはかる[1]。更新前のアノテーションデータを参照しながら、更新後のアノテーションデータの再構成を試みるような仕組みを取り入れる予定である。
このエディタを使って、ユーザは言語構造(構文や意味に関する構造)に関するアノテーションをテキスト文に付加したり、コンテンツ内の画像や音声といった要素にコメントをつけたりすることができる。言語構造に関するアノテーションは自動生成できる。ただし、その構造にあいまいさが含まれる場合は、ユーザがアノテーションエディタを操作して修正する。言語構造の表示は、グラフィカルに表示してその構造が把握しやすいように工夫した。
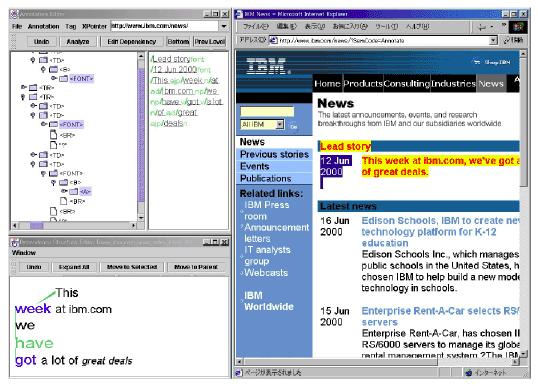
図 3.7-2 アノテーションエディタの画面例
図 3.7-2は、アノテーションエディタの画面例である。これは、テキストに含まれる言語構造を自動解析し、その結果を修正するツールである。言語構造を視覚的にわかりやすく表示し、簡単なマウス操作で修正できる。その他の機能として、HTML文書の任意のタグ要素にコメント文をつけ加える機能がある。
さらに、報告者らはコンテンツの原著者がアノテーションを制御する方法を開発している。原著者が自分のコンテンツに対する一切のアノテーションを許可しない場合、コンテンツ内にアノテーションを許可しないという記述を入れることによって、アノテーションサーバがそれを認識し、アノテーションエディタからの要求がきても拒否するような仕組みになっている。
3.7.3.2 言語的アノテーションとテキストトランスコーディング
テキスト文書のトランスコーディングとは、言語的アノテーションを用いたテキスト文書の加工を指す。言語的アノテーションは、修飾-非修飾関係といった言語構造や固有名詞、動詞などの品詞や語義などをコンテンツに関連づける。具体的には、XML[14]形式のタグと属性を使って言語構造や語義をもとのコンテンツに付与する。
言語的アノテーションは、コンテンツに含まれるテキスト文の言語構造に関するアノテーションである。語間の係り受けや代名詞の指示対象、多義語の意味といった詳細な情報を含む。この言語的アノテーションは、ドキュメントの内容理解に大きく貢献し、テキスト文のトランスコーディング以外にも、例えば、内容検索や知識発見などにも利用できる。
言語的アノテーションの記述形式として、GDA(Global Document Annotation)と呼ばれるものがある[1]。これは、XML形式のタグを利用して、文書の統語・意味・談話構造を明示化するものである。
GDAタグつきドキュメントは、例えば以下のようなものである。
<su><adp opr="loc"><adp opr="psr">人間の</adp><np
sense="0f2e4c">細胞</np>には、</adp><np syn="p"><np><vp><adp><adp><np
sense="0f74e9">自動車</np>でいえば</adp><adp opr="iob">アクセルに</adp>当たり、</adp><adp
opr="obj"><np id="a1"sense="3be2c7">がん</np>を</adp><adp
opr="gra">どんどん</adp>増殖する</vp><n>「<namep id="a2"><np
eq="a1" sense="3be2c7">がん</np><n id="a3"sense="3bf4d0">遺伝子</n></namep>」</n></np>と、<np><adp><np
sense="107ab3">ブレーキ</np>役の</adp><n>「<namep
id="a4"><np eq="a1" opr="obj"sense="3be2c7">がん</np><n
sense="10d244 3cf57c">抑制</n><n eq="a3" sense="3bf4d0">遺伝子</n></namep>」</n></np></np>がある。</su><su><adp
opr="cnd"><adp opr="sbj"><np><adp opr="psr"><np
eq="a2 a4" sense="0face2">双方</np>の</adp>バランス</np>が</adp>取れていれば</adp>問題はない。</su>
これらは統語構造を表しており、各エレメント(タグで囲まれた部分)は統語的構成素である。ここで、<su>は1文の範囲を表し、<n>、<np>、<vp>、<adp>、<namep>は、それぞれ名詞、名詞句、動詞句、形容詞句/形容動詞句(前置詞句、後置詞句を含む)、固有名詞句を表す。syn="p"は等位構造(例えば、例文中の「〜がん遺伝子と〜がん抑制遺伝子」)を表す。等位構造の定義は、係り受け関係を共有するということである。特に何も指定がない場合は、例えば、<np><adp
opr="x">A</adp><n>B</n></np>はAがBに依存関係があることを表す。また、opr="x"は<adp>エレメントの関係属性を表している。また、sense="*"は語義属性を表している(属性値としては、例えばEDR単語辞書[5]の概念識別子が利用できる。また、1語が複数の語義を持つ場合は、属性値が複数になる)。
この形式を用いて、テキスト文書の要約や翻訳を実現する。例えば、このタグを使った要約のアルゴリズムは以下のようになる[9]。
(1) 要素とその参照要素の間で重要度が等しくなり、それ以外では重要度が減衰するように重要度の計算(活性拡散)を実行する。
(2) 重要度の拡散演算が終了した時点で、平均重要度の大きい順に文を選択する。
(3) 選択された文で削除すると意味が通らない必須要素を抽出する。
(4) 文の必須要素をつなげて文の骨格を生成し、要約に加える。代名詞などの参照表現の先行詞が要約に含まれない場合は参照表現を先行詞で置き換える。
(5) 要約が指定された分量に達したときは終了する。まだ余裕がある場合は、次に重要度の高い文と省略した要素の重要度を比較して、高い方を要約に加える。
必須要素になり得る要素は、大きく分けて3つある。1つは要素の主辞である。主辞とは、ほかの要素に依存しない中心となる要素である。もう1つは内容、原因、条件、主題などの関係属性を持つ要素で、例えば、主語や目的語などが当てはまる。ほかに、等位構造が必須要素の場合は、それに直接含まれる要素も必須要素になる。等位構造とは、例えば2つの要素Aと要素Bが、ANDあるいはORの関係で結ばれている構造を指す。等位構造の要素のうちいずれを削除しても文の意味が変わってしまう。
報告者らの手法では、特定の個人の趣味や嗜好に、より柔軟に適合するように一連の処理を実行することが可能である。例えば、要約を開始する時点でユーザが任意のキーワードを入力して嗜好や興味を反映できるようになっている。ユーザが入力したキーワード
と関連する単語を重要語として処理する。重要語を含む要素は重要度の初期値をかなり大きくとり、活性拡散を行う。さらに、ユーザの趣味や嗜好の学習機能も含まれている。キーワード設定の履歴に応じて、コンテンツに含まれる要素の重要度を決めることができる。これによって、要約システムは特にユーザからの入力がなくても、そのユーザに特化した要約を生成することができる。このほか、テキスト文書のトランスコーディングの例としては翻訳が挙げられる。現在、英語から日本語、および英語からヨーロッパ言語(ドイツ語、フランス語、スペイン語、イタリア語)の自動翻訳をトランスコーディングとして実現している。英日翻訳に関しては、日本アイ・ビー・エムが開発した翻訳エンジンを使用している。PC向け翻訳ソフトウェア「インターネット翻訳の王様」の翻訳エンジンを、アノテーションを考慮して翻訳するように拡張したものを用いている[13]。

図 3.7-3 オリジナルドキュメント
図 3.7-4 要約・翻訳されたドキュメント
図 3.7-3はオリジナルのコンテンツであり、要約・翻訳した結果が図 3.7-4である。
翻訳エンジンによる誤訳の多くの部分は、語間の係り受け解析の失敗や、多義語の訳語選択の失敗による。係り受けや語義を明示化したアノテーションをコンテンツに付加することによって、翻訳精度の改善が見込める。将来的にはコンテンツの作者は、トランスコーディングによって誤解が生じるのを防ぐために、積極的にアノテーションをつけるようになると思われる。
近い将来、Webコンテンツを母国語でしか表現していない人々が、トランスコーディングによってさまざまな言語圏の人々に情報発信できるようになるだろう。
また、読者の理解度に合わせて専門的な表現をより一般的な表現に書き換えて、わかりやすい文章にする、パラフレーズトランスコーディングについても研究を進めている[2]。
3.7.3.3 コメントアノテーションと音声トランスコーディング
セマンティックトランスコーディングシステムは、テキスト文などのコンテンツを音声合成によって、音声に変換することもできる。テキスト文だけでなく、画像とテキスト文が混在するコンテンツの場合、画像の説明にあたるコメントアノテーションを用いることによって、非テキスト要素も含めて音声化することができる。さらに固有名詞など、正しい読み方が音声合成用の辞書にない場合も言語的アノテーションによって、読み方を指定することができる。
コメントアノテーションは、主に非テキスト要素に対する任意のコメントを含むアノテーションである。コメントはテキスト文だけでなく、画像やハイパーリンクなども含むことができる。例えば、コメントアノテーションを含んだ画像をマウスポインタで指すと、その画像の説明ウィンドウがポップアップして表示される。あるいは画像とテキストを含むコンテンツ全体を合成音声で読み上げた場合、画像部分に関してはコメントアノテーションを参考にして音声化する。コメントアノテーションは以前から研究が行われている。例えば、コメントを管理するサーバと、コンテンツにコメントを加えて加工するプロキシを別個に用意するというものである[10][11]。これはコンテンツを共有するグループが、コンテンツに関する補足情報を効果的に共有できるように配慮したものである。基本的には、セマンティックトランスコーディングの枠組みもこれと同様である。ただし、コメントを付与する単位がコンテンツ全体ではなく、任意のHTMLの要素に対して行える。コメントはそれを読む人間のためであると同時に、そのコンテンツを機械が理解して適切にトランスコードするための手段としてとらえている。
実際にコンテンツを音声に変換してユーザに配信するには2種類の方法があるだろう。1つはトランスコーディングを担当する外部サーバが音声データを作成してクライアントに配信する方法である。クライアントが音声合成機能を持たない場合に有効である。例えば、携帯電話からWebページにアクセスするときに使う。もう1つは、音声合成システムを備えたクライアントに加工したテキストデータを配信する方法である。この場合、音声合成に適した形式にコンテンツをトランスコードすることになるだろう。MP3のデコーダが内蔵された携帯電話が発売されるようになった。今後、配信された音声データを携帯電話に一時的に保存して、ユーザの都合の良いときに聞くといった使い方が盛んになると思われる。
3.7.3.4 イメージトランスコーディング
画像のトランスコーディングは、ユーザが使用する機器の表示能力などに合わせてコンテンツに含まれる画像のサイズや解像度を変換する処理である。ただし、変換された画像は必ずもとの画像へのリンクを含むようにしてあるため、オリジナルのサイズや解像度で見たいときは、単にその画像をクリックすればもとの画像が現れる。
画像のトランスコーディングとテキストのトランスコーディングを併用することにより、ユーザの好みに応じて、画像と文書の表示バランスを変えることができる。表示する要約の分量や、画像と文書の表示バランスは、ページに埋め込まれた設定ウィンドウで調整する。
3.7.3.5 マルチメディアアノテーションとビデオトランスコーディング
マルチメディアコンテンツのメタデータあるいはアノテーションは、これまで主に著作権管理、検索、選択などの応用を目指して設計されてきているが、さらに多くの応用を可能にする枠組みとしてセマンティックトランスコーディングが利用できる。
映像コンテンツをトランスコーディングする場合、まず映像コンテンツに含まれる音声のトランスクリプト(書き起こしたテキスト文)を用意する。このトランススクリプトに、意味構造や、シーンの変わり目のタイムコード、シーンごとのキーフレームの位置、映像の各シーンに登場するオブジェクトの名前とその出現位置(時間と座標)などをアノテーションとして付加する。
セマンティックトランスコーディングにおけるマルチメディアアノテーションでは、トランスクリプトを自動的に生成して、半自動的にアノテーションを作成できる。映像のシーンの変わり目も自動認識し、シーンに関するタグづけを支援する。
このシステムは、現在のところ、映像コンテンツの要約の生成、映像コンテンツからテキストと画像からなるコンテンツへの再構成や、ビデオ音声の翻訳などが実現できる。

図 3.7-5 ビデオアノテーションエディタ
図 3.7-5はビデオアノテーションエディタの画面例を示している。このエディタは、ビデオのシーンへの分割と音声部分のテキスト化を行う。自動処理の結果はインタラクティブに修正できる。
ビデオアノテーションエディタは、まず、ビデオデータを音声データと動画像データとに分離する。音声データについては、2か国語放送のようにチャンネルごとに異なる言語音声が収録される場合があるため、さらに左右のチャンネルごとに音声を分離する。両チャンネルの音声信号の差分の平均が閾値以上である場合は異なる音声とみなし、多言語音声識別・認識処理にかける。こうして得られるトランスクリプトは、タイムコードと認識された単語列および言語情報を含んでおり、次に示すようなXML形式のデータとして表現される。
<text lang="ja">
<w in="1.264000" out="1.663000">残す</w>
<w in="1.663000" out="2.072000">時間も</w>
<w in="2.072000" out="2.611000">少なくない</w>
<w in="2.611000" out="3.180000">ましたが</w>
<w in="3.180000" out="3.778000">最後に</w>
<w in="3.778000" out="4.856000">次近々発売</w>
<w in="4.856000" out="5.215000">される</w>
<w in="5.215000" out="5.934000">マイクロソフト</w>
<w in="5.934000" out="6.153000">の</w>
<w in="6.153000" out="6.462000">オート</w>
<w in="6.462000" out="6.802000">マップ</w>
<w in="6.802000" out="7.191000">トリップ</w>
<w in="7.191000" out="8.039000">パンダを紹介</w>
<w in="8.039000" out="8.538000">しましょう</w>
...
</text>
一方、動画像データはシーン検出処理およびオブジェクトトラッキングにより、タイムコードとシーンの代表イメージ(キーフレーム)を含むシーン情報データと、オブジェクトの名称と説明とイメージ、関連するURLへのリンク、出現タイムコード、画像上の位置の軌跡情報からなるオブジェクト情報データを、次に示すようなXML形式のデータで表現する。
<scene>
<v in="0.066733" out="11.945279" file="s0.jpg"/>
<v in="11.945279" out="14.447781" file="s1.jpg"/>
<v in="14.447781" out="18.685352" file="s2.jpg"/>
...
</scene>
<object>
<vobj begin="1.668335" end="4.671338" name="Davids"
desc="anchor" img="o0000.jpg" link="http://...">
<area time="1.668335" top="82" left="34"
width="156" height="145"/>
<area ... />
</vobj>
...
</object>
2か国語放送のようなビデオデータの場合、シーン情報やオブジェクト情報のタイムコードとそれに対応するトランスクリプトのタイムコードとがチャンネル(言語)ごとに異なることが多いため、これらのアノテーションデータはチャンネルごとに作成し、各情報をまとめて記述する次のようなビデオアノテーションデータを作成する。
<vax file="D:¥demo.mpg">
<text channel="0" src="D:¥demo¥0.vt"/>
<text channel="1" src="D:¥demo¥1.vt"/>
<scene channel="0" src="D:¥demo¥0.vs"/>
<scene channel="1" src="D:¥demo¥1.vs"/>
<object channel="0" src="D:¥demo¥0.vo"/>
<object channel="1" src="D:¥demo¥1.vo"/>
</vax>
ビデオトランスコーディングには、ビデオの文書化(ビデオからテキストとイメージの集合への変換)、ビデオの要約、ビデオの翻訳などが含まれる。それらについて簡単に説明する。
ビデオからテキストとイメージへの変換は、ビデオトランスコーディングの基本となる変換である。例えば、もし、クライアントのデバイスがビデオを再生することができない場合、ユーザはビデオのコンテンツにまったくアクセスできなくなってしまう。その場合、ビデオトランスコーダーはそれぞれのシーンを代表するイメージとそれぞれのシーンの内容を表すテキストを含めたドキュメントを作成してユーザに提示することができる。このドキュメントは、PCのブラウザに表示されるときは、ビデオプレイヤを内部に埋め込んだマルチメディアプレゼンテーションとして機能する。つまり、イメージをクリックして、それに関連するシーンをプレイヤ上で再生したり、再生中のシーンのトランスクリプトを、背景色を変えて強調したりすることができる。また、シーン内の人物や対象物の領域を選んで、それに関連づけられたコメントなどの情報をポップアップウィンドウに表示することもできる。さらに、後述するように、生成されたドキュメントを、テキストトランスコーダを用いて要約あるいは翻訳することもできる。
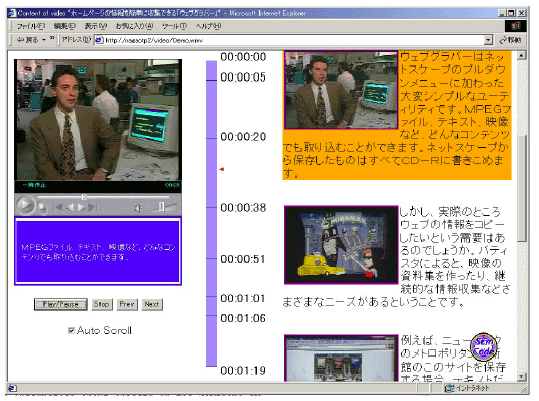
図 3.7-6 ビデオドキュメント
図 3.7-6は生成されたビデオドキュメントの画面例である。左上がビデオプレイヤの画面でその下に字幕ウィンドウがある。中央の垂直のバーはタイムバーで、右のウィンドウには、シーンのキーフレームと、そのシーンのトランスクリプトが表示されている。
ビデオの要約は、まずビデオのトランスクリプトを要約して、その要約に対応するビデオシーンを抽出することによって行われる。これは、トランスクリプトが対応する音声の出現するタイムコードを含んでいるため、そのタイムコードを含むシーンを選択することで要約できる。
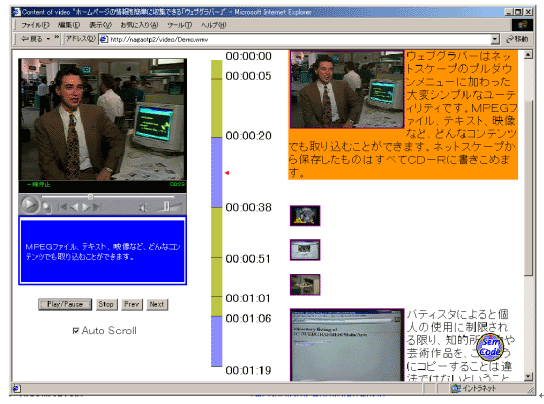
図 3.7-7 要約されたビデオドキュメント
図 3.7-7は要約されたビデオドキュメントの画面例である。中央のタイムバーの青色の部分が要約に相当する。また、要約に含まれないシーンのキーフレームは小さく表示される。もちろん、要約だけ再生させることもできるが、その他のシーンもキーフレームをクリックすることによって再生できる。また、テキストの要約と同様に、要約のサイズを変えたり、キーワードを入力したりするなど、インタラクティブに要約をカスタマイズすることができる。
ビデオの翻訳には、2種類あり、トランスクリプトを翻訳してテキストとして表示するだけの場合と、翻訳結果を音声合成によって音声にし、ビデオの再生と音声の再生を同期させることによって、他の言語のビデオを作成する場合がある。後者の部分は、まだ実現されていないが、近い将来にこの機能も統合される予定である。
報告者は映像コンテンツが今後重要な情報ソースになることを確信している。そのため、要約やフィルタリングに限定されない、コンテンツの再利用を可能にするさまざまな枠組みをできるだけ早めに用意しておきたいと考えている。ここでのアノテーションを利用した手法は、将来の枠組みに対しても容易に付加情報を変換して対応できるようにした。例えば、MPEG-7[7]のようなアノテーションの標準的なフレームワークが確立した場合にも容易に移行できるだろう。
3.7.4 インタフェースロボット
ロボット技術の目覚ましい進歩に伴い今世紀には人間とコンピュータの対話のスタイルの劇的な変化が予想される。そこで、報告者らは人間とコンピュータの新しい対話スタイルを想定して、統合された普遍的なプラットフォームを適用し、それを通して、この分野で重要な役割を果たすことを目標とする。ここでは従来のようなコマンド入力中心の一方通行型の操作ではなく音声出入力システムを用いた双方向型の対話のメカニズムが中心になる。また、学習・適応・記憶をつかさどり、対話システムの主要なプログラムとなる感情ユニットを開発して、人間的なモダリティを備えた対話インタフェースの実現を目指している。こうしたシステムはさまざまな情報端末に対応する強力なツールとなり、それにより自然な対話が実現すれば多くのユーザが利用することになるだろう。
自然言語インタフェースのような従来のシステムでは細かい制約が多く自然な会話は成立しにくかった。ユーザにはコマントの正確さが求められるし、コンピュータは予期しない文章には応答できず文脈も強く制約される。こうした問題のため、このようなシステムにおける会話は目的を1つに絞った単純なものとなってしまう。こうした会話は人間の日常的な会話とはかけ離れた不自然なものである。こうした理由から、その用途は電話案内などの特殊なものに限られており、一般的普及には至らなかった。
日常会話を観察すれば、その中でさまざまな内容が展開され複数の目的に向かった発話が同時になされていることがわかる。ある発話とそれに続く発話のつながりは明らかに希薄である。コンピュータはそのような日常会話の特性にあわせてシステムを実用に耐えるべく調整しなければならない。人間の会話というものは、本来、思いもよらない方向に発展する性質のものである。報告者らが提案する会話システムはこのような会話を扱うことによって人間の会話により近い自然な雰囲気を作ることが目標である。ここで提唱されるシステムは即応的発話ユニットとプランに基づく発話生成ユニットそしてそれらを統合する感情ユニットから成る。
即応的発話ユニットは入力に対して局所的な観点から出力を返す。一方プランに基づく発話生成ユニットは会話の全体的なフェーズを考慮しながら会話をコントロールする。さらに感情ユニットは前者が後者をコントロールし、後者が前者を活性化するような設計を
備えている。感情ユニットは両者から情報を受け取り、複雑な感情状態を作りだす。その感情状態がまた両者に再供給される、という仕組みである。
このような柔軟な会話ナビゲーションユニットの導入により、文脈が刻々と変化し何の目的も持たないようでありながら大局的には1つの筋道に従って展開する人間の会話により近いインタラクションが現実的なものになるだろう。
テキストを主として処理を行う従来のテクノロジーに対して、報告者らは、文脈に基づく手法を適用する。そこではフレーズや断片的発話に関する口語的処理が中心となる。それによって文法からの逸脱、いい間違い、言い換え、言いよどみ、音声認識上の問題といった自発的対話への対処も可能になるだろう。
3.7.5 会話ロボットPongとQB
このようなアーキテクチャに基づいて、新たなヒューマンインタフェースとして会話ロボットに関する研究を進めている。報告者らの取り組むロボットは、手足の動きなど外観の機能や動きを追求するのではない。「人間にとって役に立つ、便利な助手のような存在」として利用できるようにするための仕組み、つまり知能の部分にフォーカスを当てている。人間とのコミュニケーションの手段は非常に身近な「会話」である。しかしながら、人間が機械に対して話しかける行為に抵抗を感じるという問題をまずはクリアしなければ役には立たない。人間は無意識のレベルで、存在感があり、動作する対象が自分に注意を向けていることを感じ取ると、それは「自分とコミュニケートする対象なのだ」と直感的に認識していると思われる。つまり、直感的で臨場感のある「会話」によって、人間と機械がスムーズなコミュニケーションを行うために、「ロボット」という入れ物を利用するわけである。その1つが以下に紹介するロボットPongである。
3.7.5.1 Pong
Pongは、話しかけられると、ユーザの意図を理解し、必要な情報を集めて自動的に処理し、適切な応答の生成を試みる。さらにはユーザと行ってきた会話の履歴を記憶する能力を持たせることにより、ユーザの嗜好にあった行動をロボットが自発的に行ってくれるようになるだろう。また、ユーザに特化し同調するような仕組みとして感情を理解できるシステムもあらかじめ組み込んでおけば、ユーザがうれしいとき、ロボットもうれしいし、楽しいとロボットも喜んでくれるだろう。ロボットが知性と感情を持ちあわせるようになったとき、便利さだけでなく、人間を癒してくれる存在となるだろう。

図 3.7-8 Pongとの対話
図 3.7-8は、Pongと報告者との対話風景である。
最近、ペット型ロボットなどにより人間とある種のコミュニケーションを行うロボットに関心が高まっている。しかし、エンターテインメント性だけを追求していると、いつか飽きられてしまうだろう。しかし、人間との会話や知識を処理するインテリジェンスを持たせたとき、人間にとって本当に信頼のおけるパートナーになり得るだろう。
以下はPongとの会話例である。
Pong「こんにちは。ボクはPongって言うんだ。アメリカのIBM研究所で生まれたロボットなんだ。ボクは人間の言葉が少しだけわかるんだ。ボクに何か聞いてよ」
人間「君は何ができるの?」
Pong「いろいろできるよ。例えば計算とか」
人間「じゃ、問題を出すよ」
Pong「いいよ」
人間「100×200は?」
Pong「100×200の答えは2万だよ」
人間「じゃ、100÷7は?」
Pong「100÷7の答えは割り切れないよ。14.28571428……」
人間「どうもありがとう」
Pong「どういたしまして」
「ピンポン(卓球)」の「ポン」から名づけられたこのロボットは、もとはIBMアルマデン研究所で開発されたものである。人間の感情を理解できるコンピュータの開発を目指す「ブルーアイズ」プロジェクトの産物である[4]。赤外線LEDを頬に埋め込み、鼻の部分に仕込まれたカメラを使って人の顔などの画像を入力する。人の方向を向いて笑ったり、人が視界からいなくなると悲しそうな表情をしたりするなど、人間の行為に対して反射的な応答を示すことができる。ここで重要なのは、顔表情が人間とのコミュニケーションを促進する働きがあるということである。これは、コンピュータアニメーションでも同様なことが言え、インタフェースエージェントにキャラクタの外観を与え、表情やジェスチャなどのノンバーバルモダリティを持たせる研究がいくつか行われた。現在では、インタフェースエージェントという名前を聞いたときに、コンピュータスクリーン上の擬人的なキャラクタを想像する人は少なくないであろう。しかし、スクリーン上のバーチャルなキャラクタに絶対的に不足しているのは、「彼(彼女)が今そこにいて、自分に関心を向けている」という存在感あるいはアウェアネスであろう。物理的な存在感ほど人間の直感に訴えるものはない。バーチャルリアリティが目指しているのも、まさにその部分をソフトウェアによって制御可能にすることだと思われる。
インタフェースが物理的な存在感を持ち、人間と会話ができ、働きかけができるものであるなら、親密度はぐっと増し、コンピュータ(の埋め込まれた環境)はとっつきにくく、使いづらいというようなイメージを払拭できるかも知れない。
そのような発想から生まれたのが、Pongのような会話ロボットである。ロボットに話しかけるだけで、テレビを見なくても、新聞を読まなくても、その日のニュースや情報を得ることができるようになる。例えば、以下のような具合である。
人間「Pong、インターネットってわかる?」
Pong「もちろんわかるよ。インターネットを使うといろんな情報が手に入るよ」
人間「じゃあ、日経新聞のページが見たい!」
Pong「日本経済新聞のホームページだね。スクリーンに出すよ」
人間「読んでくれる?」
Pong「東京証券取引所の先物取引で……」
人間「英語のページも見たいな。ブルーアイズのホームページをお願い」
Pong「ブルーアイズのページを出すよ」
人間「英語わかる?」
Pong「もちろんわかるよ。でも、まだあまり上手じゃないけど」
人間「説明してくれるかな」
Pong「ページに書いてあることを説明するよ。ブルーアイズは……」
今後、すべての家電にコンピュータが搭載されネットワーク化される、いわゆる「情報家電」の時代がやってくると言われている。家庭内がネットワークでつながると、それらを使いこなすにはどうしたらいいか、また新たな問題が発生してしまうだろう。これまでならテレビのスイッチを入れればテレビがついたように、操作する対象と操作内容が1対1の関係であったためにわかりやすかったものが、さまざまな機械が依存関係を持ち、何を操作すると何に影響するのかがわかりにくくなってしまうだろう。このような依存関係をすべて人間に把握させるのは困難なので、インタフェースとしてのロボットにその役割を担ってもらおうということである。ロボットに情報家電のすべての機能および依存関係を把握させておき、ロボットに自分の要求を言葉で伝達すると、ロボットは人間の意図と状況を認識し、家電を操作し、状況を報告する、という具合になるだろう。そのようになって初めて、ロボットは人間にとってなくてはならない存在になると思う。
Pongには、音声認識、音声合成、対話処理技術のほかに前述のセマンティックトランスコーディング技術が統合されている。このように、会話ロボットはさまざまな技術を統合するテストベッドにもなる。
最後にインタフェースエージェントとロボットの今後の方向性について述べる。物理的な存在であるロボットの弱点はそのままの形では情報世界を移動できないことである。しかし、ロボットの記憶や知識は人間にとって重要なものであり、例えば外出先であっても、それを利用したい状況は多いと思われる。人間がロボットを引き連れて移動することも考えられるが、それよりも、ロボットの記憶や知識を受け継いだ(ソフトウェア)インタフェースエージェントを携帯型システムに常駐させ、移動中であってもインタラクション可能にするやり方が有効であろう。
この場合、物理的な存在感は感じられないが、以前のインタラクションの記憶が継承されていれば人間にとってロボットとエージェントは一貫したものと感じられ、電話で遠隔地の人間と話すように、エージェントと会話して、要求を伝達することができるだろう。
このように、インタフェースエージェントと会話ロボットはその多くの部分を共有し、記憶の一貫性を保ち、状況に応じてインタラクションのスタイルを変えられるようになると思われる。
また、ロボットとエージェントは、コミュニティを媒介し、人同士のコミュニケーションを促進するシステムとしても機能する。例えば、会話ロボットは遠隔地にいるもの同士が非同期でコミュニケーションする場合に、物理的な存在感を備えた、擬似的な対面性を実現することができる。また、長い経験を通じて個人情報を獲得したロボットやエージェントは、その人の外在化された記憶あるいはパーソナリティを持つシステムとして機能できるようになるだろう。これは、ロボットやエージェントが文字通り人間の代理人になるということであるが、もしロボットやエージェントの信用や責任という問題がうまく技術的あるいは社会的に解決できれば、人間は自分のコピーあるいは分身を作って同時に複数の作業ができるようになるだろう。

図 3.7-9 QBとの対話
3.7.5.2 QB
QBは、Pongの後継機となる、表情豊かな移動型会話ロボットである。このロボットは、Pongと同様に、人間の言葉を聞いて、さまざまな質問に答えてくれる。例えば、明日の天気や、今日のニュースや、スポーツの結果など、Webコンテンツから必要な情報を探し出して音声で伝達することができる。また、QBには人のような顔があり、その表情は会話に臨場感や親近感を与えてくれる。そして、頭や手を触ると、QBはときに喜び、ときに嫌がったりもする。これは、感情表現によって、ユーザの注意をひきつけるためである。
図 3.7-9は、QBと報告者との対話風景である。QBは、Pongと違って自律的に移動できるので、人間はQBに話しかけるのにワイヤレスマイクの機能を持つPDA(携帯情報端末)を用いる。ユーザはこのPDAを使って、認証に必要なユーザIDやユーザの現在位置を伝達することもできる。
また、QBは自らの判断で場所を移動し、離れている人とも会話しようと試みる。例えば、遠くにいるQBを声で呼ぶと、近くまで寄ってきて話を始める。つまり、QBには自らの位置と人間の位置を認識して、自律的に移動する能力がある。
QBには自分の家があり、バッテリーのチャージをするスペースが用意されている。そのため、QBは自分のエネルギーが少なくなると、家に帰っていく。QBの家は、インターネットから得られた情報を個人ごとの要求に合わせて加工する機能が組み込まれていて、QBとは無線で通信し情報交換することができる。
さらに、QBは、複数の人の声を聞いて、それぞれの人に合った答え方をする。生きた掲示板のように、多くの人の意見を収集して、個別に取り次いだりするメッセンジャーとしての働きもすることができる。将来は、QBのようなロボットが多くの人々の間に浸透していき、コミュニケーションを活発化させる役割を果たすようになると思われる。そして、人間の質問に気軽に答えてくれるような知的なパートナーになってくれることだろう。
QBの主な目的は次の通りである。
3.7.6 おわりに
PongやQBを通じて、会話ロボットのコンセプトはかなり明確になったものと思われる。また、これらのプロトタイプシステムを開発して実験した経験から、新しいユーザインタフェースとしての会話ロボットが、PCに代わって一般家庭に普及する可能性が大いにあることを実感している。
また、ユーザに提示されるコンテンツは、高度に個人化されたものになるだろう。本報告で紹介したセマンティックトランスコーディングが、そのための重要な技術の1つになるものと確信している。
謝辞
セマンティックトランスコーディングとインタフェースロボットは報告者と学生研究員(細谷真吾、白井良成、大平茂輝、東中竜一郎、米岡充裕、伊藤大輔、Kevin Squire、梅澤猛、福岡俊樹、片桐由希子、斉藤美紀、小熊崇)との共同研究である。諸氏に感謝する。言語的アノテーションに関しては、GDAプロジェクトと連携して行われている。プロジェクトリーダーの産業技術総合研究所サイバーアシスト研究センターの橋田浩一氏には、常に議論の相手をしていただいている。ここに記して感謝する。
参考文献
| [1] | Koiti Hasida: Global Document Annotation, http://www.i-content.org/GDA/. |
| [2] | 東中竜一郎, 長尾確: アノテーションを用いてWebドキュメントを分かりやすく提示する方法, 第3回インターネットテクノロジーワークショップ(WIT2000)論文集 (2000). |
| [3] | Masahiro Hori, et al: Annotation-based Web Content Transcoding, Proceedings of the Ninth International WWW Conference, pp. 197-211 (2000). |
| [4] | IBM Almaden Research Center: BlueEyes Project Web Page, http://www.almaden.ibm.com/cs/blueeyes/. |
| [5] | Japan Electoronic Dictionary Research Institute: Electoronic Dictionary, http://www.iijnet.or.jp/edr/J index.html. |
| [6] | Hiroshi Maruyama, Kent Tamura, and Naohiko Uramoto: XML and Java: Developing Web applications, Addison-Wesley (1999). |
| [7] | Moving Picture Experts Group (MPEG): MPEG-7 Context and Objectives, http://drogo.cselt.stet.it/mpeg/standards/mpeg-7/mpeg-7.htm. |
| [8] | Katashi Nagao, Yoshinari Shirai, and Kevin Squire: Semantic Annotation and Transcoding: Making Web Content More Accessible, IEEE MultiMedia, Vol. 8, No. 2, pp. 69-81 (2001). |
| [9] | Katashi Nagao and Koiti Hasida: Automatic Text Summarization Based on the Global Document Annotation, Proceedings of COLING-ACL ユ98, Vol. 2, pp. 917-921 (1998). |
| [10] | Martin Roscheisen, Christian Mogensen, and Terry Winograd: Shared Web Annotations as a Platform for Third-party Value-added Information Providers: Architecture, Protocols, and Usage Examples, Technical Report CSDTR/DLTR, Computer Science Department, Stanford University (1995). |
| [11] | Matthew A. Schickler, Murray S. Mazer, and Charles Brooks: Pan-browser Support for Aannotations and Other Meta-information on the World Wide Web, Computer Networks and ISDN Systems, Vol. 28 (1996). |
| [12] | 浦本直彦: Semantic Web - 機械のためのWeb -,人工知能学会誌, Vol. 16, No. 3, pp. 412-419 (2001). |
| [13] | Hideo Watanabe, Katashi Nagao, Michael C. McCord, and Arendse Bernth: Improving Natural Language Processing by Linguistic Document Annotation, Proceedings of COLING 2000 Workshop on Semantic Annotation and Intelligent Content, pp. 20-27 (2000). |
| [14] | World Wide Web Consortium: Extensible Markup Language (XML), http://www.w3.org/XML/. |
[1]ユーザがトランスコーディングを要求したWebコンテンツが更新されたかどうかを知るために、DOM(Document Object Model)ハッシュと呼ばれる手法を利用する[6]。DOM ハッシュでは、Webコンテンツの内部構造に関してハッシュ値の演算を行う。どのHTMLエレメントが更新されたかを知ることができる。