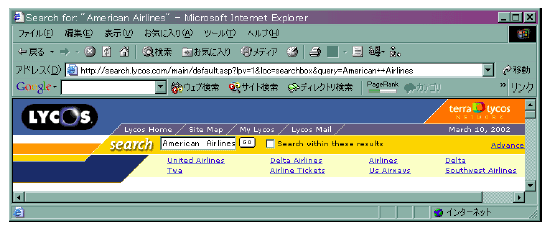
図 3.11-1 Lycosでの検索語クラスタリング
3. 研究開発の新しい展開と内外の動向
報告者: 山名早人委員
3.11.1 はじめに
インターネットの普及により、WWW上に蓄積される情報が急増している。このように急増する多種多様な情報を検索するためにYahoo![1]やGoogle[2]など数々の情報検索システムが存在する。
情報検索システム(サーチエンジン)とは、検索語をユーザに入力してもらい、あらかじめ生成しておいたインデックスに基づいて検索を実行し、結果をユーザに返すシステムである。しかし、その検索精度[1]や再現率[2]には問題があることが指摘されており、品質向上のためにさまざまな工夫が試みられている。その1つとして、GoogleではHTMLのリンク構造をランキング[3]に利用するPageRank法[3][4][5]を提案し利用している。PageRank法は、「重要なサイトからの被リンク数[4]が多いほど重要な情報である」という経験則に基づき検索結果をランキングする手法である。すなわち、多くの人がよいWebページであると評価しているページを検索結果の上位にランキングする。Web上には膨大な情報があるため、このようなリンク構造を用いたランキングは、膨大な情報の中から有用な情報を上位にランキングするための1つの有効な手段となっている。
しかし、すばらしいランキング手法を用いたとしても、ユーザが的確な検索語を入力しなくては、情報検索システムも的確な検索結果を返すことができない。一般に、情報検索システムに入力される検索語は1〜2語であるため、的確な検索結果を返すことが非常に困難となっている。例えば、検索語として「コンピュータ」が入力されたとする。この場合、ユーザが「コンピュータの機種一覧を知りたい」のか、「コンピュータの操作方法を知りたい」のか、情報検索システムにはわからない。従って、「コンピュータ」という検索語で的確な検索結果を返すことは、一般的には不可能である。
上記のような問題に対する解決策として、いわゆるポータルサイトなどでは、ユーザに嗜好などの情報を登録させ、ユーザの嗜好情報に合致した情報を提供する仕組みを提供している。このような仕組みは、一般的に情報フィルタリングと呼ばれる。例えば、Yahoo!は、1996年7月からWeb上で初めての大規模なパーソナライズを開始した[6]。Yahoo!では、My
Yahoo!と呼ばれるページでユーザの嗜好に合わせて自分専用のWebページを構築できる。例えば、ユーザがパーソナライズしたショータイムのWebページを閲覧していて、直後の検索で郵便番号を検索語として入力した場合は、映画館を検索結果として出力する[6]。
情報フィルタリングの手法は、情報検索においては、query clustering[7][8]として応用されている。query clusteringでは、同一の検索結果にたどりついた検索語群を同一のクラスタに属するとみなして、検索語と検索結果を対応づけておく。そして、ユーザが分類済のクラスタに属する検索語を入力した場合、入力された検索語に対応づけられた検索結果を返すことにより、ユーザが入力する検索語の情報不足を補う。
情報検索においては、ほかに、query transformation、query routingなどの手法が提案されている。これらは、広義の意味においてユーザの検索意図を判断する手法に分類できる。
以下では、ユーザの意図を判断するための手法として、これまで提案されている情報フィルタリング、query clustering、query transformation、query
routingの手法を概説するとともに、新しい手法として、同一ユーザが検索を行う際の連続する検索語の出現パターンから、ユーザの検索意図を発見する手法について紹介する。
3.11.2 情報フィルタリング
情報フィルタリングは、大きく2つに分類することができる。1つは、content-based filteringであり、もう1つは、collaborative
filtering[9][10]である。
content-based filteringでは、ユーザのプロファイル(嗜好情報)と、コンテンツとの情報とのマッチング[5]を行い、ユーザに合ったコンテンツを推薦する。しかし、最初に登録したプロファイルが正確でなかったり、情報提供者がプロファイル上で想定している分類とユーザが考える分類とが異なっていたりした場合は、うまく機能しない。
collaborative filteringは、content-based filteringが、該当するユーザの情報のみを用いてコンテンツの推薦を行うのに対し、他の同じ嗜好を持つユーザの情報を使って、コンテンツの推薦を行う仕組みである。つまり、あるユーザAとユーザBの嗜好が同じであれば、ユーザAが高い評価を下したコンテンツは、ユーザBも高い評価を下すと仮定する。例えば、A〜E君までの5人がそれぞれ好きな映画タイトル情報があったとする。[6]
A君: 王様と私、スターウォーズ
B君: 王様と私、スターウォーズ、風の谷のナウシカ
C君: バットマン、スターウォーズ
D君: バットマン、スターウィーズ、ランボー
E君: 風の谷のナウシカ、ウィスパーズ
今、F君が「王様と私」が好きだったとすると、F君はほかに何が好きであろうか。「王様と私」が好きなA君とB君は「スターウォーズ」が好きなので、F君も「スターウォーズ」が好きであると判断できる。しかし、一方で「スターウォーズ」はほとんどの人が好きな映画であるので、推薦はできるがあまり有効な情報は言えない。そこで、「王様と私」が好きなB君が好きな「風の谷のナウシカ」を推薦することもできる。さらに、もう1段推論を進めるとE君の情報から、「風の谷のナウシカ」が好きであれば「ウィスパーズ」も好きであると推測できる。このような手法をcollaborative
filteringと言う。
しかし、collaborative filteringにも問題がある。例えば、新規にコンテンツが登録されても、新規コンテンツがユーザに推薦されにくいといった問題がある。さらに、ユーザが興味を持つコンテンツであったとしても、実際に、そのコンテンツにアクセスする機会がなければ推薦できない[7]。このような問題を解決する手法として、content-based
filteringとcollaborative filteringを組み合わせたハイブリッドな手法が提案されている[11]。文献[11]では、コンテンツ提供者によって静的に定義されたカテゴリに加えて、動的に類似コンテンツ集合からなるカテゴリを作成し、動的カテゴリを導出している。これによって、ユーザの興味や関心を動的に反映したカテゴリ作成が可能となる。
3.11.3 ユーザごとの情報検索サポート
本節では、従来提案されているユーザごとの情報検索サポート手法について概説する。
3.11.3.1 Query Clustering
3.11.2節で紹介した情報フィルタリングの手法は、情報検索においては、query clustering[7][8]として応用されている。
クラスタリングにおいては、2つの検索語(各検索語は複数の語で構成されているとする)があった時、これらの検索語の間に類似性[8]があれば、同一もしくは類似した情報を検索していると判断する。しかし、情報検索システムに入力される検索語は一般的に1〜2語であり、検索語間の類似性を検索語のみから判断することは難しい。そこで、情報検索分野で使われているクラスタリング手法が用いられる。情報検索においては、伝統的に「類似した文書は同じ検索語により検索される傾向がある」ことがわかっているため、この関係を逆に利用し、「検索履歴を用いて、最終的に同一の検索結果にたどりつく検索語群」を同一のクラスタに分類している。
そして、ユーザが分類済のクラスタに属する検索語を入力した場合、入力された検索語に対応づけられた検索結果を返すことにより、ユーザがあいまいな検索語を入力した場合でも的確な検索結果を返すことを可能にする。ただし、必ずしも1つの検索語が1つのクラスタに属するとは限らないため、入力された検索語が複数のクラスタに属する場合は、検索結果の上位に異なるクラスタの検索結果を表示するという手法がとられる。この場合、ユーザが、「similar」[9]などのボタンをクリックすることによって、情報検索システムは、クラスタを特定することができ、最終的にユーザが望んでいる検索結果を返すことが可能になる。
図 3.11-1 Lycosでの検索語クラスタリング
一方、検索語のみのクラスタリングも可能であり、Lycos[12]では、検索語と同一のクラスタに属する語をユーザに提示する仕組みを持つ。例えば、American Airlinesで検索するとUnited AirlinesやDeltaなどを表示する(図 3.11-1)。さらに、文献[13]では、同一のユーザの連続する検索履歴をもとに、同一ユーザが入力した検索語群に対してクラスタリングを行う仕組みを提案している。例えば、「ホームセンター」で検索した場合に、同一のクラスタに属する「ディスカウントショップ」での検索を並行して行う仕組みを提案している。
3.11.3.2 Query Transformation
Query Transformationは、検索語とインデックス化されたWebページとの間の語句のミスマッチングをなくすための変換手法であり、検索語として自由文が入力された際に効果を発揮する。例えば、「ハードディスクって何?」と言う検索語が入力された場合、形態素解析[10]によって検索語を分割すると「ハードディスク」「って」「何」「?」となる。一般的に、「って」「?」はstop
word[11]として無視されるため、最終的には、「ハードディスク」AND「何」で検索が実行される。ところが、Webページとして探し出したいページに「何」という語句が存在するかどうかは疑問である。例えば、このような例の場合、「ハードディスクとは」で始まる文章[12]を持つWebページを検索することにより、ユーザの検索意図にあったWebページを見つけ出すことができる。すなわち、「ハードディスクって何?」という検索語を「ハードディスクとは」に変換し検索を行うことをQuery
Transformationと呼ぶ。
Query Transformationに関連する研究は、TREC[14](Text Retrieval Evaluation Conference)のQuestion-Answering
Trackにおいて多くの研究が実施されている。TRECにおいては、50〜250バイトの解答文書(英文)をあらかじめ用意されたquestionセットにより検索する課題が出されるが、実際のWeb上で適用する場合には、さらに一般化が必要となる。例えば、AskJeeves[15](図
3.11-2)では、これらの変換に対してあらかじめ変換テーブルを用意し、ユーザが入力した質問形式の検索語を回答の書き方に合わせて変換する。
図 3.11-2では、「Who is the president of USA?」に対してホワイトハウスのWebページが検索結果として出力されている。
文献[16]では、「what is ×」のような質問に対して「× is」「× refers to」という解答を含む文で現れる語句に変換する仕組みを利用して複数の情報検索システムにQuery
Transformation語の検索語を送り検索させるシステムを提案している。さらに、文献[17]では、これらの変換テーブルをタグつきの音声データから自動取得する方式を提案している。
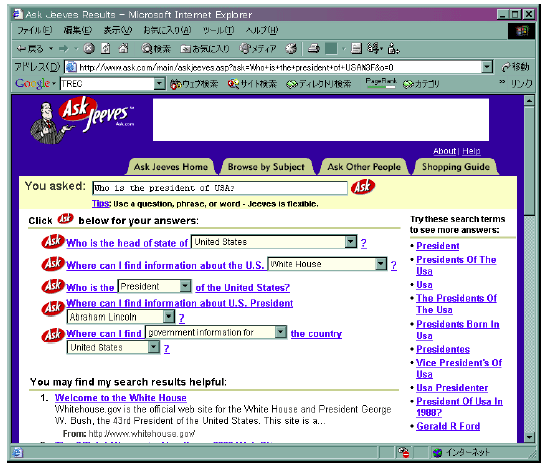
図 3.11-2 AskJeeves
3.11.3.3 Query Routing
複数の情報検索システムの中から、入力された検索語のトピックに適した情報検索システムを探し出すことをquery routingと呼ぶ。近年、さまざまな専用化された情報検索システムが登場してきており、query
routingの役割は今後ますます重要となると考えられる。
Query Routingは、その手法を3つに分類することができる[18]。
(1) 手動ルーティング。
(2) 各データベースが持つコンテンツ情報に基づいて自動ルーティングする手法。
(3) 各データベースのコンテンツ情報を使用せずに自動ルーティングする手法。
手動ルーティングは、AllSearchEngines.comのようにあらかじめ各情報検索システムをカテゴライズしておき、検索時にユーザに使用する情報検索システムを選択させる手法である。各データベースのコンテンツ情報に基づいて自動ルーティングする手法は、各データベースがコンテンツとして持つ情報からキーワードを作成し、検索語とのマッチングをとることにより、入力された検索語に適した情報検索システムを選択する手法である。しかし、Webを対象とした場合、内部のデータベースにアクセスすることは困難であるため、Webを対象としたQuery
Routingでは、3番目の手法が一般的に用いられる。
3.11.4 連続するクエリの出現パターンの分類とユーザの検索意図の推定
本節では、従来の検索語の内容に依存した情報検索サポートではなく、検索語の出現パターンのみからユーザの検索意図の一部が解析可能であることを示すために行った実験[19]について紹介する。実験では、同一ユーザの連続する検索語の時系列をモデル化し、各モデルに対して検索意図の推定を行った。
3.11.4.1 実験手法
実験にあたってはMicrosoft Accessibility[20]およびMicrosoft Product Support Serviceのサポート技術情報検索[21]に入力された検索履歴を使用した。使用する検索履歴は個人情報を含んでおらず、検索語と検索が行われたタイムスタンプのみである。このため、まず、同一ユーザの連続する検索を同定する必要がある。以下に解析手順を示す。
(1) 同一ユーザによる連続する検索の同定
入力された各々の検索語は独立の検索としてログ上に記録されているため、まず、同一ユーザによる一連の検索を同定する必要がある。本報告では、10分以内の連続する検索であり、かつ、複数の検索語を用いて検索している場合は1番目に入力されている検索語が同一である場合、同一ユーザによる検索であると判断した。したがって、同一ユーザによる検索であっても、1番目の検索語を変更した場合は、本実験では同一ユーザとして判断できていない[13]。
(2) 検索のパターン分類
(1)によって得られた同一ユーザによる連続する検索語入力について、検索語の増減、変化を分類する。各分類(パターン)の発生頻度を求める。
3.11.4.2 解析結果
A-ABは最初の検索で「A」を、2回目の検索で 「A and B」を検索語として入力したことを示す。 |
複数回(2回以上)検索しているユーザの検索回数を表 3.11-1に示す。この表より4回以上の検索を行っているユーザは全体の5%であり、残り95%の検索は3回以内の検索で完了していることがわかる。以上から、連続する3回までの検索について頻出する検索パターンを分類した。検索パターンの分類とその割合を表 3.11-2に示す。各検索パターンの説明を表 3.11-3に、各検索パターンにおける再検索の推測理由を表 3.11-4に示す。
| No. | パターン | 説明 | 例 |
| 1 | A-AB | 最初の検索語から検索語の数を増やす場合。 | 1回目: "excel" 2回目: "excel"、"ダウンロード" |
| 2 | AB-AC | 先頭の検索語は変えずに後ろの検索語を他の検索語に変える場合。 | 1回目: "IPアドレス"、"プリンタ" 2回目: "IPアドレス"、"プリントサーバー" |
| 3 | AB-A | 1回目に複数個の検索語で検索を行ったが、2回目で検索語を減らす場合 | 1回目: "windows2000"、"ファイルキャッシュ" 2回目: "windows2000" |
| 4 | A-AB-AC | 2回目の検索で検索語を増やし、3回目の検索語で後ろの検索語を変えている場合。 | 1回目: "フォント" 2回目: "フォント"、"追加" 3回目: "フォント"、"ダウンロード" |
| 5 | A-AB-A | 2回目の検索で検索語の数を増やし、3回目の検索で再び検索語を減らし元に戻す場合。 | 1回目: "キーボード" 2回目: "キーボード"、"OSK" 3回目: "キーボード" |
| 6 | A-ABC-AB | 2回目の検索で2個増やしたが、3個目で再び1個減らす場合。 | 1回目: "ユーザインターフェイス" 2回目: "ユーザインターフェイス"、"ガイドライン"、"Windows" 3回目: "ユーザインターフェイス"、 "Windows" |
| 7 | AB-A-AC | 1回目の検索で複数の検索語を入れて検索し、2回目で検索語を増やし、3回目で再び検索語を増やす場合。 | 1回目: "ProxyServer"、"フィルタ" 2回目: "ProxyServer" 3回目: "ProxyServer"、"設定" |
| 8 | AB-A-AB | 検索語を減らしたあと、再び同じ検索語を増やす場合 | 1回目: "ユーザー"、"切り替え" 2回目: "ユーザー" 3回目: "ユーザー"、"切り替え" |
| 9 | AB-AC-AB | 検索語を変えた後、再び同じ検索語に戻す場合 | 1回目: "ユーザー"、"切り替え" 2回目: "ユーザー"、"切替" 3回目: "ユーザー"、"切り替え" |
表 3.11-2より、2回の検索(パターン1〜3)が約80%を占め、3回までの検索を含めると全検索の91%を占めることがわかる。なお、表 3.11-1では3回までの検索回数が全体の約95%を占めているのに対し、表 3.11-2では91%となっているのは、表 3.11-2のパターン分類に分類されない3回以内の検索が含まれているからである。
| No. | パターン | 検索結果が多すぎた場合 | 検索結果が少なすぎた場合(0の場合も含む) | 検索結果を見たが、欲しい情報がなかった場合 | 実際にページを閲覧した結果、欲しい情報がなかった場合 | 1回目の検索結果の方がふさわしいと判断した場合 | 表記のゆれを訂正 |
| 1 | A-AB | ○ | ○ | ○ | |||
| 2 | AB-AC | ○ | ○ | ○ | ○ | ○ | |
| 3 | AB-A | ○ | ○ | ○ | |||
| 4-a | A-AB | ○ | ○ | ○ | |||
| 4-b | AB-AC | ○ | ○ | ○ | ○ | ○ | |
| 5-a | A-AB | ○ | ○ | ○ | |||
| 5-b | AB-A | ○ | |||||
| 6-a | A-ABC | ○ | ○ | ○ | |||
| 6-b | ABC-AB | ○ | |||||
| 7-a | AB-A | ○ | ○ | ○ | |||
| 7-b | A-AC | ○ | ○ | ○ | |||
| 8-a | AB-A | ○ | ○ | ○ | |||
| 8-b | A-AB | ○ | |||||
| 9-a | AB-AC | ○ | ○ | ○ | ○ | ○ | |
| 9-b | AC-AB | ○ |
3.11.4.3 検索パターンに基づいた情報検索サポート
| No. | パターン | 検索語入力の意図(推定) | 情報検索システムでの検索サポート(例) |
| 1 | A→AB | (1) Aの検索において、検索結果上位に求める結果が存在しない。 | 特になし。 |
| 2 | AB→AC | (2) Bでの絞り込みに失敗。 | (2') ACの検索において、Bを含まないものを上位にランキング。 |
| 3 | AB→A | (3) ABでは検索結果が絞り込まれすぎたが、Bはまったく関係ない語ではない。 | (3') Aの検索において、BおよびBに関連する語を含むページを上位にランキング。 |
| 4-a | A→AB | (1)と同様。 | 特になし。 |
| 4-b | AB→AC | (2)と同様。 | (2')と同様。 |
| 5-a | A→AB | (1)と同様。 | 特になし。 |
| 5-b | AB→A | (3)と同様。 | (3')と同様。 |
| 6-a | A→ABC | (1)と同様。 | 特になし。 |
| 6-b | ABC→AB | (4) ABCでは検索結果が絞り込まれすぎたが、Cはまったく関係ない語ではない。 | (4') ABの検索において、CおよびCに関連する語を含むページを上位にランキング。 |
| 7-a | AB→A | (3)と同様。 | (3')と同様。 |
| 7-b | A→AC | (5) ABでは絞り込まれすぎ、Aでは検索結果上位に求める結果が存在しない。 | (5') ACの検索において、BおよびBに関連する後を上位にランキング。 |
| 8-a | AB→A | (3)と同様。 | (3')と同様。 |
| 8-b | A→AB | (6) AよりもABの検索結果の方がよい。しかし、ABでは絞り込まれすぎる。 | (6') ABの検索においてBをBの関連語に拡張して検索。 |
| 9-a | AB→AC | (2)と同様。 | (2')と同様。 |
| 9-b | AC→AB | (7) ACよりもABの検索結果の方がよい。 | (7') ABの検索において、Cを含む語を上位にランキング。 |
各検索パターンに対する再検索理由(表 3.11-4)をもとに、各検索パターンに対して表 3.11-5に示すような情報検索サポートが可能であると考えられる。現時点では、これらの情報を用いた実験は未実施であるが、3.11.3で示したような既存の手法とあわせて用いることで個人の検索意図にあった検索サポートが期待できると考えられる。
3.11.5 おわりに
本節では、情報検索において、ユーザの検索意図を検索結果に反映させるための仕組みについて、従来の研究を概説するとともに、新しい手法として、同一ユーザが検索を行う際の連続する検索語の出現パターンから、ユーザの検索意図を発見する手法を紹介した。
世界中のコンピュータがインターネットにより接続される現在、ネットワークにより接続された各種情報は、Knowledge Gridと呼ぶべきものであり、膨大なインターネット上の情報の中から必要な情報を効率よく取り出し活用する仕組みが今後ますます重要になっていくものと考えられる。
参考文献
| [1] | Yahoo!: http://www.yahoo.com/ |
| [2] | Google: http://www.google.com/ |
| [3] | L. Page, S. Brin, R. Motwani, and T. Winograd: The PageRank Citation Ranking: Bringing Order to the Web, Stanford Digital Library Technologies, Working Paper SIDL-WP-1999-0120 (1998). |
| [4] | M. Henzinger: Link Analysis in Web Information Retrieval, IEEE Bull. of the Tech. Committee on Data Engineering, Vol. 23, No. 3, pp. 3-8 (2000). |
| [5] | T. H. Haveliwala: Efficient Computation of PageRank, Stanford Digital Library Technologies, Technical Rep. 1999-31 (1999). |
| [6] | [6] U. Manber,, A. Patel and J. Robison: Experience with Personalization on Yahoo!, Communications of the ACM, Vol. 43, No. 8, pp. 35-39 (2000). |
| [7] | [7] D. Beeferman and A. Berger: Agglomerative Clustering of a Search Engine Query Log, KDD2000, pp. 407-416 (2000). |
| [8] | J. R. Wen, J. Y. Nie, and H. J. Zhang: Clustering User Queries of a Search Engine, Proc. of 10th World Wide Web Conference, Hong Kong (2001). |
| [9] | U. Shardanand and P. Maes: Social Information Filtering: Algorithms for Automating 'word of mouth.ユ, Proc. of the ACM CHI Conf. (CHI95) (1995). |
| [10] | L. H. Ungar and D .P. Foster: Clustering Methods for Collaborative Filtering, Proc. of the Workshop on Recommendation System, AAAI Press, Menlo Park California (1998). |
| [11] | M. Okamoto, J. Kamahara, S. Shimojo, and H. Miyahara: Automatic Production of Personalized Contents with Dynamic Scenario, Proc. of 2001 IEEE Pacific Rim Conf. on Communications, Computers and Signal Processing (PACRIM01), Vol. 1, pp. 91-94 (2001). |
| [12] | 大浦, 喜連川: Webアクセスログのクラスタリングによる問い合わせ拡張に関する検討: iタウンページ上での実験, 第13回データ工学研究会 (DEWS2002) (2002). |
| [13] | Lycos: http://www.lycos.com/ |
| [14] | TREC: http://trec.nist.gov/ |
| [15] | AskJeeves: http://www.ask.com/ |
| [16] | S. Lawrence and C. L. Giles: Context and Page Analysis for Improved Web Search, IEEE Internet Computing, Vol. 2, No. 4, pp. 38-46 (1998). |
| [17] | E. Agichtein, S. Lawrence and L. Gravano: Learning Search Engine Specific Query Transformations for Question Answering, Proc. of 10th World Wide Conference, Hong Kong (2002). |
| [18] | A. Sugiura and O. Etzioni: Query Routing for Web Search Engines: Architecture and Experiments, Proc. of 8th World Wide Web Conference (1999). |
| [19] | 鈴木俊輔, 山名早人: 時間間隔を用いた検索履歴のモデル化, 情報処理学会ディジタルドキュメント研究会 (Mar. 2002). |
| [20] | Microsoft Accessibility: http://www.microsoft.com/japan/enable/ |
| [21] | Microsoft Product Support Service: http://support.microsoft.com/ |
--------------
[1] 検索結果の内、何%が検索語に対する検索結果として正しいかを示す割合。
[2] 本来検索結果として出力すべきWebページの内、何%を出力できたかを示す割合。一般にWebを対象とした検索システムでは、全Web空間を定義できないため、再現率を正確に算出できない。
[3] 順位づけすること。
[4] リンクされている数。
[5] 一般には、キーワードマッチングを行う。
[6] 文献[8]を参考に例を作成した。
[7] 映画の例では、観れば好きな映画と判断できても、実際に観なければ推薦されないことを意味する。
[8] 同一のキーワードを含んでいるなど。
[9] 検索結果の各Webページに付加的につけられたボタンで、「similar」をクリックすると該当のWebページに類似する検索結果のみが表示される。
[10] 形態素(動詞、名詞、……)に分割すること。
[11] 検索語として適さない語であり、検索の際に無視される語句。
[12] 一般的に語句を説明する文章は「○○とは」で始まることが多いため。
[13] 同一ユーザによる連続する検索を同定するためには、Cookieを用いるのが一般的である。しかし、Cookieの利用は個人情報取得に関係するため、今回の実験ではタイムスタンプと検索語のみを用いて同一ユーザの同定を行った。同定においては、検索語の最初の語が等しいことを前提としたが、これは、「一般的に最初の語は変更しない場合が多い」という経験則に基づいたものである。