図 3.12-1 toto(サッカーくじ)ホームページの人気度推移
3. 研究開発の新しい展開と内外の動向
報告者: 津田宏講師
3.12.1 はじめに
Webは、1989年に当時CERN(Conseil European pour la Recherche Nucleaire、欧州合同素粒子原子核研究機構)に勤務していたTim Berners-Leeが情報共有のために発明し、1990年から実験的にサーバが稼働していたとされる。しかし、その後の伸びが目覚ましいのは周知の通りである。ページ数も、次のように天文学的な数字になりつつある(ただし、Webは総ページ数をどこかで管理しているわけでなく、動的なページをどう扱うかで数値も変わり、これらは推計方法もまちまちであるため、一列に並べるのに問題はある。ただし、このようなオーダーのページ数があるというのは、ほぼ正しいだろうと思われる)。
これだけの量の文書があり、なおかつGoogleをはじめとする優秀な検索エンジンのおかげで、さすがに体系的な知識の入手という点では書籍に劣るものの、特定のトピックやちょっとした情報であれば、最も簡単に素早く入手できる環境ができている。
こうした膨大なWebを単に調べるだけでなく、その中から必要な知識をうまく取り出し、研究やビジネスに活用していこうという流れが「Webマイニング」(Webからの知識発掘)である。データマイニング(大量生データからの知識発掘)やテキストマイニング(大量文書からの知識発掘)と違い、Webには文書だけでなく、リンクやログといった色々なデータがある。そのため、Webマイニングに有用性はあるものの、固有技術はあまりなく、従来技術をWebに活用していったという研究が多く、全体としての体系化は遅れている。
以下、3.12.2節では、Webマイニングの概要を実例も含めて紹介する。3.12.3節では、Webマイニング技術の限界と次世代Webにおける展開を述べる。
| 対象 | 抽出する知識例 | 技術 | コミュ ニティ |
応用 | |
| データ マイニング |
生データ (POSデータ など)、 VLDB |
アイテム間の 相関ルール、 予測 |
相関ルール抽出、 クラスタリング、 分類、視覚化 |
DB | 意思 決定、 効率 向上 |
| テキスト マイニング |
テキスト(mail、 新聞、論文、 コールセンター ログなど) |
単語間関係、 文書間関係 (分類) |
テキストからの データ化 (形態素解析、 情報抽出) |
DB、 NL、 IR、 AI |
CRM、 KM |
| Web マイニング |
Web (HTML: テキスト + URL + タグ + ハイパーリンク + レイアウト、 アクセスログ) |
ページメタデータ (人気度、分類 など)、 ページ集合 (コミュニティ) 発見、 DB知識 (XML化) |
タグ構造からの 情報抽出 (wrapper)、 リンク解析、 効率的収集 (アクティブ マイニング) |
DB、 NL、 IR、 AI、 KA、 Web系、 …… |
CRM、 KM、 …… |
3.12.2 Webマイニングとその概要
3.12.2.1 データマイニングからWebマイニングへ
表 3.12-1に、データマイニング技術、テキストマイニング技術、およびWebマイニング技術の関係の概要をまとめた。「対象」の列は、何から知識を取り出すかを示す。「抽出する知識例」の列は、対象から取り出される知識を示す。「技術」の列は、そこで必要となる技術の例を示す。「コミュニティ」の列は、その技術が発表される領域を示す。Web系には、WWW
Conferenceなどがある。「応用」の列は、ビジネス上の用途を示す。
こうして見るとわかるように、Webマイニングは、とりわけ多くのコミュニティにまたがっている。これは、対象とするWeb情報が、文書(テキスト)、データ(ログ、リンク)など、さまざまな側面を持っていることに由来する。
3.12.2.2 Kosalaによる分類
Kosalaらは、Webマイニングを、次のように処理対象データの側面から分類している[9]。
(1) Web Content Mining
Webページの文書としてのコンテンツから知識を取り出す。
(1a) IR(information retrieval、情報検索)的観点
Webページを構造化されていないテキストと見る。
IRや自然言語処理技術を利用。
応用としては、ページ分類やテキスト中のパターン情報抽出など。
(1b) DB(database、データベース)的観点
Webページを(タグにより)半構造化されたデータとして見る。
タグを利用した情報抽出(wrapper)などの技術を利用。
応用としては、ページの繰り返しパターンの発見など。
(2) Web Structure Mining
ページ間のリンク関係から情報を取り出す。
応用としては、分類(コミュニティ発見)や、人気度の獲得などがある。
(3) Web Usage Mining
Webの利用ログの分析である。サーバのアクセスログや、検索エンジンのログなどがある。
応用としては、Webサイトの構築/改築支援、マーケティングなどがある。ただし、ログ分析単体では、どちらかというと単なるデータマイニングの範ちゅうに入ると思われる。
(1)と(2)の実例については後述する。
3.12.2.3 山西による事例紹介
山西は、Webマイニングを、表 3.12-2のように事例の側面から分類している[17]。
「意見分析」は、Content Miningの例であり、Webページや掲示板の情報から、利用者が製品についてどのような意見(好意的とか、けなしているとかなど)を持っているかを弁別するもので、Webを使ったマーケティング支援の例である。
「コミュニティ発見」は、Structure Miningの例であり、リンク関係を利用して類似したページを集めるというものである。
「最適広告配信」以下の4つは、いずれもUsage Miningの例である。さまざまな技術がWebのログに適用されている。
| Function | Input | Output | Model + Algorithm |
| 意見分析 | コンテンツ | 特徴語リスト | 情報抽出、テキスト分類、 確率的コンプレキシティ |
| Webコミュニティ 発見 |
リンク | コミュニティ ページリスト |
グラフ理論、平均場理論、 ベイジアンネット |
| 最適広告配信 | ログ (クリック履歴) |
バナー広告 | ニューラルネット、情報量基準、 Hitchcock型輸送問題 |
| リコメンデーション | ログ、クッキー、 コンテンツ |
推薦コンテンツ | 相関係数法、 逐次型2項関係学習法 |
| アクセスパタン 分析 |
アクセスログ | アクセスパタン (クラスタ) |
マルコフモデル、 有限混合モデル |
| 異常ログ検出 | アクセスログ | 異常ログリスト | 統計的外れ値検出、 オンライン忘却型アルゴリズム |
3.12.2.4 Webマイニングのプロセス
Kosalaによると、Webマイニングは以下のプロセスから成る[9]。
| (1) | Resource Finding 対象とするリソースの同定、収集。 |
| (2) | Information Selection, pre-processing データのクレンジング(ゴミデータの除去)、形態素解析などのテキスト処理、情報抽出などの特定パターン取り出しなど、対象を処理できる情報に変換したり、データをきれいにしたりするプロセスである。 |
| (3) | Generalization マイニングプロセス。ルールやパターンの取り出し、分類などマイニングの本体である。 |
| (4) | Analysis 得られた結果を人手でチェックする。 |
KDD(knowledge discovery in database、データベースからの知識発見)、いわゆるデータマイニングでも、同様のプロセスが必要とされている[Usama 1996]。ただし、データマイニングやテキストマイニングではあまり重要ではなかったが、Webマイニングで重要となるプロセスが(1)のResource Findingである。というのも、3.12.1節で述べたように、Webは膨大で常に拡大しているため、そのすべてをWebロボット(自動収集プログラム、Webクローラとも言う)で集めるのは膨大な時間がかかり、また集めたときには対象となるWebは変化してしまっている。このように、対象が常に変化する膨大なデータから、当面必要となる情報をいかにうまく取り出すかということが、Webマイニングでは必要になる(このような性質のデータからの知識発掘は、「アクティブマイニング」と呼ばれはじめている[11])。
3.12.2.5 Resource Finding
Webロボットは1995年くらいから行われてきており、Webの収集においては、深さ限定で幅優先探索が有効とされている。ただし、そのような固定した収集方略では、まんべんなく大量にとる場合は良いが、特定のページを収集するということはできない。そのため、目的に応じて必要なページを選択的に収集する技術が提案されている。Webの拡大と共に、そのように効率的に収集する手法への期待は大きい。
東芝で(現在は独立した会社で)サービスが行われている、フレッシュアイという検索エンジンサービスでは、ページの更新頻度を学習し、良く更新されるページを優先的に収集することが特徴である。
Focused Crawling[2]は、ハイパーリンク関係にある文書は内容的にも近いので、文書のコンテンツ類似度から見て、離れそうになったら探索を打ち切るという考え方である。
Efficient Crawling[3]は、リンク先を表している表現(HTMLであればアンカータグの内容)から、次にそのリンク先の文書を収集するかどうか決定するという考え方を使っている。リンク関係を利用し、次に可能性がありそうなものを予想することも行っている。つまり、収集済みページからの
ものは関連度が高いというヒューリスティックスを利用し、次に集めるのが有効そうなページを判定する。例えば、被リンク数の多い文書は人気度が高いと考えられる。収集済み文書群から被リンク数の多い順に文書を収集することで、重要度の高い文書を優先して収集できる。
津田らは、特定ジャンルの少数のページから、リンク関係および共参照関係にあるページをブートストラッピングにより順次集めることで、意味的に近いページを効率良く集める手法を提案している[14]。
ただし、検索や分類と違い、このような収集系に関しては、決まった正解セットに対して精度を競うというレベルにまでまだ成熟した学問領域ではなく、個々の論文で独自に効果を測定している段階である。各論文では良いとは言っているが、それらは基本的には追試不可能である。単純な幅優先の方がかえって良かったという論文も出ており[12]、公平な測定手法が求められている。
3.12.2.6 Web Content Mining
Web Content Miningの例として、Webページからの情報抽出の実例を紹介しよう。Webに公開されている分散したカタログ情報から、製品名、価格などのレコード情報を自動で取り出し、横断検索を行うというアイディアはWebの初期のころから提案されていた。例えば、ShopBot[5]などがある。また、Webを知識ベースとして扱おうというWebKB[4]も、同様の試みである。
こうしたWebからの情報抽出では、従来のテキストからの情報抽出のようにテキスト中の文字パターンからの取り出しも可能である。坂元らは、Webからの近接語相関パターンの高速発見の手法を述べている[13]。また、Webならではといえる技術として、HTMLのタグ情報を利用した、Wrapper
Induction[10]が有名である。HTMLソースと、取り出したいレコードの対データ(正解セット)を与えると、値を取り出すようなタグのパターンを学習する機械学習手法を提案している。表形式など、個々の値が<b>タグなどでくくられているようなケースには、有効である。
3.12.2.7 Web Structure Mining
Webのハイパーリンクを解析することで、ページの人気度を算出したり、特定
コミュニティを取り出したりする研究は、97年くらいから数多く行われている。
Brinらは、検索エンジンGoogleの元となったPageRankアルゴリズムを提案している[1]。これは、ページを見ている人々の推移確率をモデル化した人気度算出手法で、
という再帰的な計算を行い、不動点としてページの人気度(重み)を決定している。
Kleinbergは、HITS(Hyperlink-Induced Topic Search)アルゴリズムを提案している[8]。これは、特定ジャンルの、ハブページ(優良リンク集)とオーソリティページ(優良コンテンツ)を取り出すものである。オーソリティページは、有用な情報を多く含み、ハブページから良くリンクされる。ハブページは、オーソリティページを良くリンクする。このアルゴリズムでは、検索エンジンの結果からリンク、被リンクを1または2レベルたどった探索空間を設定し、繰り返し計算による不動点を求める。
Gibsonらは、HITSアルゴリズムを応用して、コミュニティを、オーソリティページを中心にハブページが取り囲む構造として、取り出している[7]。
津田らは、YahooのようなWebディレクトリを自動構築する際の、リンク解析技術について述べている[14][15]。Webディレクトリでは、新鮮で、人気度が高く、情報の入り口となるページが望ましい。[14]では、リンク解析による人気度付与と、ページタイプ(メニュー、リンク集、コンテンツ)付与を行っている。
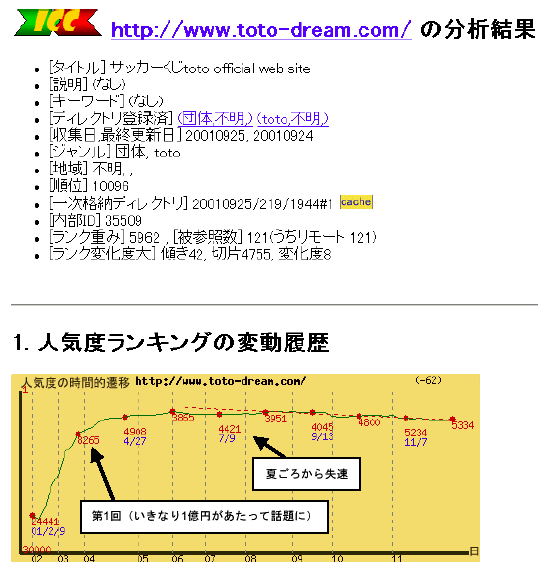
津田らは、リンク解析による人気度付与の時系列解析により、最近人気が出ているページなど、Webの動きを視覚化する研究を行っている[15]。図 3.12-1は、toto(サッカーくじ)のホームページの人気度(重みでソートした順位)の2000年2月から12月までの時系列的動きをプロットしたものである。3月の開始時点では、マスコミで取り上げられたこともあり、(ニュースサイトなどから)同サイトへのリンクも増え人気度が上昇している。しかし、夏くらいから頭打ちになり、段々人気度が降下していることがわかる。これは、人気度を順位でプロットしており、Webの拡大速度についていけなくなると、徐々に順位は落ちていくためである。
図 3.12-1 toto(サッカーくじ)ホームページの人気度推移
図 3.12-2は、2000年10月くらいから人気度が伸びている、厚生労働省の狂牛病(牛海綿状脳症、BSE: bovine spongiform encephalopathy)関係ページの人気度推移の例である。世間で問題になったのとほぼ時期を同じくして、同サイトへのリンクが増えていることがわかる。
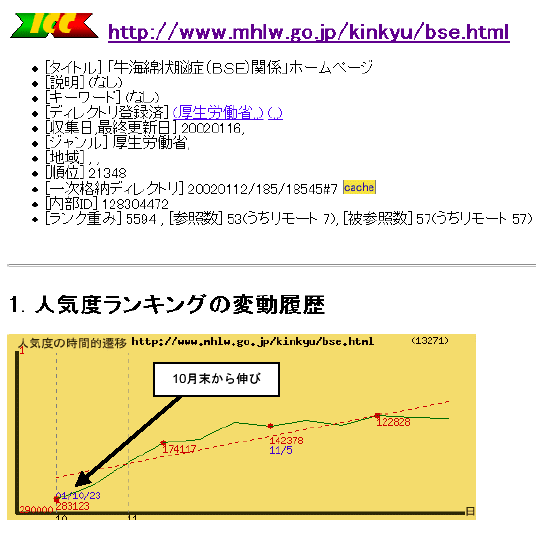
図 3.12-2 厚生労働省狂牛病関係ページの人気度推移
3.12.3 おわりに〜次世代Webに向けて
3.12.3.1 Webマイニングの限界
3.12.1節でも述べたように、このままWebが拡大していくことで、人類は有史以来最も充実した知識の宝庫を持つ可能性があるが、それには次の問題点がある。
Webマイニングのこれまでの事例で見たように、Webマイニング自体は完ぺきな技術ではない。他の(データ、テキスト)マイニングがそうであるように、知識の素となるような情報を取り出し、最終的には人間がチェックして、本当に役立つ知識として活用される。
Web Content Miningにおいては、HTMLにおける記述の自由度(HTMLは基本的には文書の意味的構造はあまり制限せず、表示主体である)や、多様な著者による多様な表現があるため、情報抽出や自動分類といった技術で精度を上げるのは一般に難しい。
Web Structure Miningでは、Webのリンク解析は検索においてはそこそこ有効であると考えられるが、どういう意図でリンクしているかの情報がないため、必ずしも、リンクベースで人気度のあるページが正しいことを言っているページであるという保証はない。例えば、ある病院が事故を起こして、さまざまなニュースページからのリンクが増えると、その病院のページの人気度重みは高くなるものの、それは必ずしもその病院が良い病院ということにはならない。Web
Usage Miningでも同様のことが言える。多くの人が見るからと言って、それは内容が正しいことを意味するわけではない。
3.12.3.2 次世代Web
こうした背景のもと、次世代Webとして、SemanticWeb[21]やWebサービス(Web Services)が提案されている。これらは、メタデータやメタ的な情報を決まった形式で記述し、機械処理による流通・交換・処理を可能とするものである。SemanticWebとWebサービスの特徴を、表 3.12-3にまとめる
| Web | 次世代Web | ||
| SemanticWeb | Webサービス | ||
| 目的 | 人が見るため | ソフトウェアが 意味的な処理をするため |
Web上の アプリケーション連携 |
| 記述方法 | HTML、画像、動画、flash、xhtml、…… | RDF/XML (メタデータ: URIで指される リソースについてのデータ)、 DAML |
XML(データ)、 DAML-s (サービスメタデータ) |
| オントロジー・構造定義 | 自由(SHOE、お酒の箪笥など、独自の試みはある) | RDF Schema/XML、 DAML + OIL |
DTD |
| 利用手段 | ブラウザ | エージェント(http?) | 統合サービス(SOAP、WSDL、UDDI) |
| 認証、 セキュリティ |
独自 | Dsig(電子署名) | Passport (Microsoft)など |
| 主な活動 | W3C、IETF、MS、Netscapeほか多数 | W3C、DAML(米国DARPA)、 OIL(欧州) |
IBM、MS .Net、 Sun ONE |
3.12.3.3 Webサービス
Webサービスは、現在まちまちな形式で行われているWeb上のアプリケーション(ショッピングなど)を、統合的に連携するためのモデルである[16]。以下のような規格が提案されており、多くのメーカがコミットしている。
このような共通基盤で記述されたWebサービスは、複数のものを連携することが可能であり、例えば出張に合わせて鉄道、ホテル、会議の予約を連携して行うなどのワンストップサービスが可能になる。Webサービスの具体例として、Microsoftによる.NETなどが有名である。
3.12.3.4 SemanticWeb
Webサービスがアプリケーションの統一を目指したのに対して、SemanticWebは、Webページなどのリソースへのメタデータ付与を提案している。SemanticWebは、Webの発明者であるTim
Berners-Leeによるコンセプトであり、人間向けで雑多になってきたWebに対して、ソフトウェアが意味的に処理できるWeb世界も加えていこうということを、長期目標としている。現在のWebを補完する考えで、WebがSemanticWebに取って代わられるものではない。基本的には、Webリソース(URLなど)に統一的なメタデータを付与することで実現する。
SemanticWebに関連する規格の階層を図 3.12-3に示す。現在、次のような状況にある。
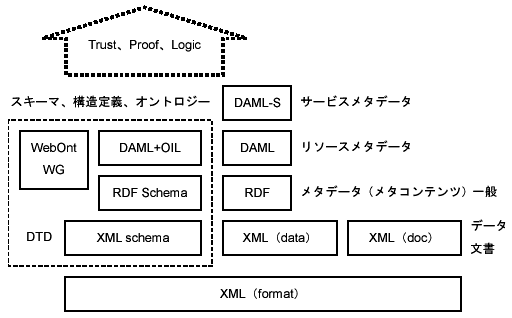
図 3.12-3 SemanticWebの規格の階層
また、SemanticWebを利用したプロジェクトとしては、次のようなものがある。
3.12.3.5 おわりに、提言
こうした次世代Webに関しては、残念ながら日本では、INTAP(Interoperability Technology Association for
Information Processing、情報処理相互運用技術協会)がタスクフォースやワーキンググループを立ち上げてSemanticWebに関する調査を行っている程度である。ただし、まだ具体的なプロジェクトは立ち上がっておらず、欧米に比べて遅れているのが実状である。
本報告で述べたようなWebマイニング技術は、このようなSemanticWebやWebサービスの世界では、メタデータやオントロジーの構築を補助し、人手コストを減らす技術として今後は有効に活用されると考えられる。
SemanticWebのようにリソースにメタデータを付与するアプローチは、海外では電子政府系の公開情報を中心にすでに行われつつある。わが国もこうした次世代Webに遅れをとらないように、早期に研究プロジェクトを立ち上げ、研究者の裾野を広げるとともに、積極的にこのような規格にも絡んでいく必要があるだろう。さもないと、日本の社会事情に則したようなメタデータやオントロジーの記述で、制限を受けるなどの問題も起こりかねない。
参考文献
| [1] | Sergey Brin and Lawrence Page: The Anatomy of a Large-Scale Hypertextual Web Search Engine, WWW7 Conference (1998). |
| [2] | Soumen Chakrabarti, Martin van den Berg, and Byron Dom: Focused Crawling: A New Approach to Topic-specific Web Resource Discovery, WWW8 Conference (1999). |
| [3] | Junghoo Cho, Hector Garcia-Molina, and Lawrence Page, Efficient Crawling Through URL Ordering, WWW7 Conference (1998). |
| [4] | Mark Craven, Dan Dipasquo, Dayne Freitag, Andrew McCallum, Tom Mitchell, Kamal Nigam, and Sean Slattery: Learning to Construct Knowledge Bases from the World Wide Web, Artificial Intelligence, Vol. 118, pp. 69-113 (Apr. 2000). |
| [5] | Robert B. Doorenbos, Oren Etzioni, and D. S. Weld: A Scalable Comparison-shopping
Agent for the World-Wide Web, Autonomous Agents (1997). (http://www.cs.washington.edu/homes/etzioni/) |
| [6] | Usama M. Fayyad, etc.: Advances in Knowledge Discovery and Data Mining, MIT Press (1996) |
| [7] | David Gibson, Jon Kleinberg, and Prabhakar Raghavan: Inferring Web Communities from Link Topology, Proceedings of the 9th ACM Conference on Hypertext and Hypermedia (1998). |
| [8] | J. M. Kleinberg: Authoritative Sources in a Hyperlinked Environment, Proceedings of 9th ACM-SIAM Symposium on Discrete Algorithms (1998). |
| [9] | R. Kosala and H. Blockee: Web Mining Research: A Survey, ACM SIGKDD Exploration,
Issue 2 (June 2000). (http://www.acm.org/sigs/sigkdd/explorations/issue2-1/contents.htm) |
| [10] | Nicholas Kushmerick: Wrapper Induction: Efficiency and Expressiveness,
Artificial Intelligence, Vol. 118, pp. 15-68 (Apr. 2000). (同アイディアはIJICAI97で最初に発表されている) |
| [11] | 元田浩: 情報洪水時代におけるアクティブマイニングの実現, 科学研究補助金「特定領域研究(B)」. (http://www.ar.sanken.osaka-u.ac.jp/activemining/) |
| [12] | Marc Najork and Janet L. Wiener: Breadth-first Search Crawling Yields High-quality Pages, WWW10 Conference (2001). |
| [13] | 坂元, 有村: Webマイニング, 人工知能学会論文誌, Vol. 16, No. 2, pp. 233-238. |
| [14] | Hiroshi Tsuda, Takanori Ugai, and Kazuo Misue: Link-based Acquisition of Web Metadata for Domain-specific Directories, PKAW2000, pp. 317-324 (2000). |
| [15] | 津田, 鵜飼, 三末: Webディレクトリのためのページメタデータの自動付与の試み, 情報学シンポジウム2002, pp. 17-24 (2002). |
| [16] | 浦本: Semantic Web − 機械のためのWeb −, 人工知能学会, Vol. 16, No. 3, pp. 412-419 (2001). |
| [17] | 山西: Webマイニングと情報論的学習理論, 情報学シンポジウム2002, pp. 9-16 (2002). |
| [18] | DARPA Agent Markup Language, http://www.daml.org/ |
| [19] | Ontology Inference Layer/Language, http://www.ontoknowledge.org/oil/index.shtml |
| [20] | Open Directory Project, http://dmoz.org/ |
| [21] | W3C, Semantic Web, http://www.w3.org/2001/sw/ |