 |
機械が人間なみに言語の「意味」を理解するという自然言語処理の主要な目標を達成するにはあと1世紀以上かかるだろう。この長期目標に関する基礎研究への投資に根拠を与えるためには、未熟な技術を有用なものにするような新たな応用を見出す必要がある。それらの応用は、同時に、こうした基礎研究の推進に貢献するようなものであることが望ましい。特に、人間の知識の使用に関する巨大かつ良質のデータを集成することが上記の目標の達成に不可欠であるが、それを研究目的のためだけに行なうことは経済的に困難と考えられるので、そうしたデータベースが応用の副産物として自動的に生成されるような枠組を考えたい。
大域文書修飾(GDA)[5、4]は、文書の意味的・語用論的な構造を明示するSGML (XML)のタグ集合を策定、公開し、そのタグを含むテキストを入出力するツールや応用プログラムの開発と普及を推進することにより、インターネット等でこのタグ集合を広めることを目指すプロジェクトであり、未熟な技術の実用化と基礎研究用のデータという、上記の二重の目的を持っている。GDAタグは現在の技術で機械が文書の意味的・語用論的な構造を理解することを可能にするので、タグの情報を利用することにより、機械翻訳、情報検索、情報抽出、要約、質問応答、事例に基づく推論、データマイニングなど、自然言語処理や人工知能のさまざまな応用の品質が飛躍的に向上する。したがって、こうした技術が安価に利用できるとすれば、自分の文書にタグ付けして公開することを多くのユーザに動機付けることになり、巨大なタグ付きコーパスがインターネットを中心として自動的に生成・成長するだろう。このコーパスは、意味やコミュニケーションの構造を明示しているので、事例に基づく知識ベースとなる。
GDAタグ集合は、章、節、段落、タイトルなどの文章の構成を表わすタグ、統語範疇を表わすタグ、曖昧性を表わす選言的タグ(alternate tag)に加えて、主題役割(thematic role)や修辞関係(rhetorical relation)などの意味関係、照応、言語行為、テンス、アスペクト、量化や否定や様相演算子の作用域、語義などを表わす属性からなる。タグの多くと属性の一部はTEI(注1)やEAGLES(注2)などの既存のガイドラインに基づいている。GDAでは多くのタグは任意的である。また、意味関係についてはEDRコーパスやGeneralized Upper Model(注3)など、照応についてはMUC(注4)のコーパスやLancasterコーパス[3]の仕様も参考にして設計している。GDAタグ集合の仕様書のドラフトを昨年の夏から公開している(注5)。コメントをいただければ幸いである。
GDAタグ付きテキストの例を図3.11-1に示す。
------------------------------
注1)http://www.uic.edu:80/orgs/tei/
注2)http://www.ilc.pi.cnr.it/EAGLES/home.html
注3)http://www.darmstadt.gmd.de/publish/komet/gen-um/newUM.html
注4)http://cs.nyu.edu/cs/faculty/grishman/muc6.html
注5)http://www.etl.go.jp/etl/nl/GDA/tagset.html
|
<v>エレメントは動詞または動詞句、<n>エレメントは名詞または名詞句、<ad>エレメントは副詞や後置詞句や連体詞などある。ctyp属性は統語的構造、obj属性は目的語を表わす。 fxは交差を含む前向きの依存関係である。日本語では、省略されたctypの値は fd(前向きの依存関係)と解釈される。
GDAタグ付きコーパスを作成中だが、そこではGDAタグの仕様全体を使うのではなく、さしあたりは統語構造と意味関係と照応だけに関するタグ付けを行なっている。後述のように、そのような単純な部分集合でも自然言語処理の応用の精度を高めることができる。
人手によるGDAのタグ付け作業を支援するソフトウェア・ツールをタギングエディタと呼ぶ。現在のタギングエィタはGNU Emacsのモードのひとつとして実現されている。そのウィンドウ表示の例を図3.11-2に示す。
 |
ウインドウは左右に分かれ、左側にタグの入れ子構造を、右側にその構造の各部に対応する文字列を表示している。実線の枝はエレメントでない文字列を、点線の枝はエレメントになっている文字列を示す。タギングエディタは、タグの範囲の指定、タグと属性の編集、id属性の自動設定などの機能を持つ。タギングエディタも公開中(注)である。GDAタグ集合以外でもSGMLであれば比較的簡単にカスタマイズできる。
------------------------------
注)http://www.etl.go.jp/etl/nl/gda/TE/
言語の主も重要な目的は意味内容を伝達することだから、タギングによって意味を明示した言語データは言語研究において有用な資料となる。また、意味に関しては形態論や統語論ほどには研究が進んでいないので、意味タギングの必要性はきわめて高い。一方、自然言語解析においては、文章の意味的・語用論的構造を検出できる程度に応じて、翻訳、検索、質問応答など、多くの技術の精度を高めることができる。また、意味的・語用論的構造は自然言語生成への入力でもある。したがって、意味タギングを施されたテキストや音声は、自然言語の解析と生成の両面にわたり、研究用の資料として貴重である。
しかし、意味に関する研究が未熟であるということは、意味タグの仕様を定めるのが難しいということでもある。そもそも意味とは何かが明らかでないので、文章の意味を十分に明示するようなタギングの方法はない。意味タグの目的は、理想的には知識表現言語(knowledge representation language)や機械翻訳用の中間言語(interlingua)のそれと同様だが、言語の意味を完全にとらえられるような知識表現言語・中間言語はさしあたり作れないと考えられる。現実問題としては、意味タグを無闇に詳細化して知識表現言語を目指すよりは、目的に応じた粒度の意味タグを設計する方が有益だろう。
言語学や自然言語処理における研究開発の現状に照らすと、意味タグによって明示すべき情報としては、深層格、修辞関係、照応、否定や量化の作用域、テンス、アスペクトなどがある。以下ではこれらのうち、GDAで実際にタギングを行なっているものを中心に述べる。
意味タグのうちで最も広く用いられているのは、深層格(deep case)─またはθ役割(theta role)あるいは主題役割(thematic role)─に関するタグである。表層格─または文法機能(grammatical function)─が統語的な依存関係(dependency; いわゆる係り受け)にある2つの統語的構成素のうち、依存する側がされる側に対して持つ統語的な関係(主語、目的語など)を示すのに対し、深層格は意味的な関係を示す。たとえば「扉が開く」においては、「扉が」の表層格はSUBJECT(主語)で深層格はTHEME(主題)である。一方、「健が扉を開く」においては、「健が」の表層格はSUBJECTで深層格はAGENT(動作主)、「扉を」の表層格はOBJECT(目的語)で深層格はTHEMEということになるだろう。つまり、2つの文が「扉」と「開く」の間の共通の関係を述べていることを、深層格によって捉えることができる。
また、文と文の間の意味的な関係を示す修辞関係(rhetorical relation)に関しても試験的にタギングが行なわれている。修辞関係とは、修辞構造理論(rhetorical structure theory; RST)[7]で提案されたもので、CAUSE(原因)とかCONCESSION(逆接)などがある。たとえば、「雪が降った。電車が遅れた。」の第1文は第2文に対してCAUSEという修辞関係に立つ。
深層格と修辞関係は、いずれも基本的には表層の形を捨象して意味的な関係を捉えるために考えられたものである。前者は主として文内の関係、後者は文間または節間の関係ということになっているが、文や節という表層の形にこだわらなければ、両者を区別する必要はないだろう。また実際、深層格と修辞関係の間の区別は明確ではない。たとえばCAUSEは、「癌で死ぬ」の「癌で」の深層格にもなっていると考えられる。これが深層格か修辞関係かという判断を意味タギングに持ち込むのはタギングのコストを増すことになり望ましくない。そこで、以下では深層格と修辞関係をまとめて意味関係(semantic relation)と呼ぶ。
意味関係のタギングには形態論や統語論のタギングよりも常識的な知識が大きく関わるので、機械化も難しい。助詞の「で」のような曖昧な手掛りしかない場合や、「雪が降った。電車が遅れた。」のように明示的な手掛りがない場合のタギングには人間の手が必要である。しかも、人間にとっても意味関係の決定は難しいことが多い。
たとえば、Generalized Upper Model(注)などの言語オントロジーでは、意味関係を概念体系の中に位置付けている。これは、意味関係とは意味的な2項関係であり、一般的な語彙的意味に対して開かれているということである。したがって、意味関係の種類には際限がない。何種類のどのような深層格があればよいかに関して永年にわたり議論されてきたが、万人が満足するような決着を見ていない。
------------------------------
注)http://www.darmstadt.gmd.de/publish/komet/gen-um/newUM.html
タギングのコストを軽減するには、意味関係の分類を大雑把にするとともに、人間が判断しやすい規準を用いることが重要である。たとえば、‘The door opened.’の主語‘the door’はTHEME、‘Tom opened the door.’の主語‘Tom’はAGENTを表わすが、この区別は英語の場合には表層の文型からわかるので、わざわざタギングによって表示する必要はない。また日本語でも、「席を離れる」の「席を」は通常の目的語と違ってTHEMEやPATIENT(被動作対象)ではなくSOURCE(起点)を表わすが、「離れる」の項目を含む辞書の存在を前提すれば、その旨のタギングは不要である。たとえばPenTreebankでは、応々にして判断が難しいAGENTやTHEMEなどの深層格を避け、SBJ(主語)などの表層格と、LOC(場所)やDIR(方向)などの判断しやすい意味関係を用いて部分的に意味タギングを行なっている。これに対し、EDRコーパスでは27個の意味関係(EDRの用語では「関係子」)によるもう少し詳細なタギングを用いている。
意味関係の種類を際限なく増殖させる主な原因のひとつは、意味関係が一般の語の意味と同じく、プロトタイプ的な構造を持ち[2]、合成や重ね合わせが可能だという点にある。たとえば、「卵を手で温める」の「手で」は「温める」に対してLOCATION(場所)とINSTRUMENT(道具)という意味関係を両方とも持っているように思われる。このような場合を扱うために、ひとつの要素(統語的構成素または文の集まり)が複数個の意味関係を持てるようにしておくことが望ましい。
意味関係を複雑化する別の要因として、比較や共参加者(joint participant)など、単なる2項関係に留まらない意味関係がある。たとえば「健は浩より太郎を気に入っている」という比較を含む文は、「浩が太郎を気に入っているよりも健は太郎を気に入っている」および「健は浩を気に入っているよりも太郎を気に入っている」という2つの解釈を持つが、いずれの解釈であるかを特定するには、何と何が比較されているのかをタギングによって明示す必要がある。GDAタグ集合(注)では、前者の解釈を明示するために、
------------------------------
注)http://www.etl.go.jp/etl/nl/GDA/tagset.html
![]()
のようなタギングを用いる。これは、「浩より」が比較(cmp)の意味関係を持つことに加えて、「健は太郎を気に入っている」と比較すべき内容の中で「浩」が主語(sbj)になっている、つまり、「健が太郎を気に入っている」と「浩が太郎を気に入っている」とが比較されていることを意味する。
一般に、単語(や句)の語義を特定する手段としては以下のようなものがある。
意味素性(semantic feature)はIPAL辞書(注1)など、概念識別子(concept identifier)はEDR辞書[17]など、同義語の集合はWordNet[10](WordNetでは同義語の集合をsynsetと呼ぶ)などで用いられている。これらについては徳永[14]の解説に譲るが、そこに述べられていない最近の話題として、CoreLex(注2)を挙げておく。これは、生成辞書(generative lexicon)[12]の考え方に基づく電子化辞書であり、これまでにWordNetの中の約40,000個の名詞を126個の意味タイプ(semantic type)に分類している。各意味タイプは、より基本的な意味素性の集合によって表現され、生成辞書で言う体系的多義(systematic polysemy)のパターンに対応する。
------------------------------
注1)ftp://ftp.mgt.ipa.go.jp/pub/ipal/
注2)http://www.cs.brandeis.edu/‾paulb/CoreLex/corelex.html
意味領野(semanic field)は、意味素性に似ているが、語句の意味そのものではなく、その意味に関連する文脈をとらえる。たとえば、「バット」の意味領野としては「野球」などが考えられる。つまり、意味領野だけでは語の意味を特定することはできないが、語句に意味領野のタグを付けることによって多義性を解消することができる。意味領野を用いて語義タギングを施したコーパスの例に関しては、Wilson and Thomas[16]を参照されたい。
語義のタギングを施した大規模な日本語のコーパスはなかったが、岩波国語辞典に基づいて毎日新聞の記事に対する語義タギングの作業がRWC知的資源ワークショップで進行中である。これは基本的に人手によるタギングを想定しているが、自動的なタギングに関しては、たとえばLDOCET(注)の語義に基づいて多義語の86%が正しく語義タギングできるという報告[15]があるので、機械による補助を取り入れるのはかなり有効であろう。
------------------------------
注)http://www.awl-elt.com/dictionaries/dictres.html
照応に関するタギングは文章の意味構造を決定するのに必須だから、意味に関するタギングの中でも重要性が高い。照応のタギングを大規模に行なった例としては、ランカスター大学のコーパス[3]の他、MUCの情報抽出課題のためのシステム開発および評価用に作られたコーパスなどがある。ランラスター大学でもMUCでも、代名詞による直接照応に限らずさまざまな現象を扱っているが、それらの範囲はかなり異なる。GDAでは、これらの成果を踏まえ、照応に関するタグの設計を進めている。
量化や否定や様相演算子の作用域(scope)、事象様相と言表様相、テンス、アスペクト、名詞句の数や定・不定などに関しても意味的な曖昧性が生ずる。GDAタグ集合は仕様の上ではこれらに対応しているが、そのようなタグを用いた大規模なタギングは実際にはまだ行なわれていない。こうした側面に関するタギングの可能性と有用性に関する研究は今後の課題である。
GDAは自然言語処理のさまざまなツールの入出力形式をタグ付きテキストとして標準化することを含意する。これは、図3.11-3に示したような統合的なアーキテクチャを意味する。このようなツールは、実際にはゼロから作るのではなく、たいていは既存のツールにwrapperをかけるだけで安価に作ることができる。このアーキテクチャにより、(データへのアクセスを含む)多様なソフトウェアツールを再利用し、統合(プラグアンドプレイ)することが可能となり、自然言語処理システムの開発と管理が簡単になる。この方式によってタギングエディタにパーサや意味タガーをプラグインすれば、機械による解析の結果を用いて人間の負荷を軽減することができる。
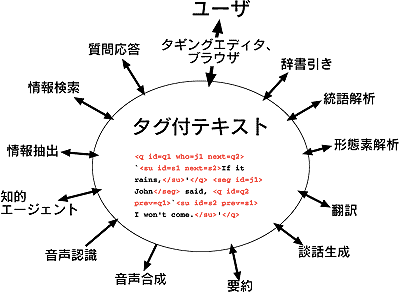
同様の統合アーキテクチャはすでに最近いくつか提案されている。LT-NSL[9]はTEI[13]に基づくSGML形式の標準フォーマットを用いた統合アーキテクチャである。TIPSTERアーキテクチャ(注1)では、タグを元のテキストに埋め込むのではなく、元のテキストとそれに対するタグを別のファイルとして扱うデータベース管理システムを核としてさまざまなツールを結合する。GATE(注2)[1]およびCorelli[18]はTIPSTERアーキテクチャを実装・拡張したものである。TIPSTERアーキテクチャはもともと情報検索と情報抽出の統合開発環境として考えられたものだが、GATEとCorellyでは機械翻訳などにも及ぶ。
------------------------------
注1)http://www.tipster.org/arch.htm
注2)http://www.dcs.shef.ac.uk/research/groups/nlp/gate/
GDAは、一般ユーザをタグ付けデータの提供者としてこうした統合環境に組み入れることにより、これを単なる開発環境ではなく利用環境へ広げようという試みである。TIPSTERなどはインターネットにおける分散サービスも視野に置いているが、GDAの文脈ではこれはたとえば辞書の分散管理などに有用なので、これらのアーキテクチャとの連携を考えたい。
GDAタグは自然言語処理のさまざまな応用の品質を劇的に向上させる。たとえば、タグの情報を用いることによって機械翻訳の精度の大幅な向上が期待される。ヨーロッパ語の間での機械翻訳は、文章の種類によってはかなり理解可能であり、ブラウジングのための翻訳としては何とか使えるレベルに達している。しかし、情報発信のための翻訳としてはまだ不十分であり、タグの利用によって情報発信のためのこなれた翻訳の可能性を視野に入れることができる。系統の異なる言語の間での翻訳はブラウジングに使えるレベルにも達していないが、タグの利用によって理解可能な翻訳にすることは可能であろう。
[19]は日本の主要メーカが開発した商用の8つの日英翻訳システムの性能を調査しているが、GDAタグの設計に当たっては、そこで指摘されているような問題を含むさまざまな問題の解決を意図した。たとえば、「何でも、ワームホールという現象を利用すれば、遠く離れた世界に瞬時に行けるのだそうだ」の英訳はかなり難しく、8つのシステムによる翻訳のうちで最もまともなものは
It is possible to go to the world away instantaneously far if the phenomenon such as anything and wormhole is used.
であった。ここでは「何でも」の係り先と意味が正しく解析できていないが、明らかにこの問題は統語構造と語義のタグによって解決できる。統語構造と言ってもさほど詳細なものである必要はない。「何でも」が文副詞であることがわかる程度の大雑把なもので十分である。また、語義タグを用いるには共有可能な語義の体系(ontology)を整備する必要があるが、語義タグを用いなくても、パターンに基づく翻訳[8]と統語構造のタグを組み合わせることによって多くの場合に対処可能である。たとえば下記のような翻訳パターンを用いることが考えられる。
*Xと *Yは変項である。A→ B は「A は B に翻訳できる」と読む。変項と→の両辺はSGMLのエレメントと単一化可能とする。活用や語順に関する詳細は割愛した。
統語解析や照応解析などの言語的な解析は、情報検索や要約などではこれまではあまり用いられていなかったが、これはこうした解析に手間がかかる割には得られる結果の信頼性が低いためである。しかし、GDAのタグを用いれば、言語的な解析の手間を軽減し、かつその結果の信頼性を格段に高めることができるので、これまでそうした解析を使っていなかった応用においても高度な自然言語処理の手法が有用となる可能性が高い。情報検索は質問応答に近いものになるだろう。データマイニング、ネットワークエージェント、事例に基づく推論などに関しても同様の可能性が考えられる。
要約もそのような応用のひとつである。英語と日本語の文書に関して実験したところ、統語構造、意味関係および照応に関するタグがあれば、言語に依存しない非常に簡単なプログラムでも要約が十分に可能である[11]。意味関係のタグ付けにはかなりの揺れがあるが、この揺れは要約の結果にはほとんど影響しない。
この要約プログラムは、意味的・語用論的な依存関係のネットワークをタグ付き文書から構成し、このネットワークの上で活性拡散[6]によって各語句の重要度を評価し、この重要度と照応や統語論にまつわる制約に従って(必ずしも文全体ではない)語句を抽出する。また、意味表現から文章を生成する一般的な技術を用いれば、単なる語句の抽出にとどまらず、さらに柔軟な要約が可能だろう。
現在、GDAタグ集合仕様書の英語版と日本語用のタギングマニュアルを作成中であるが、タギングマニュアルは各言語用に必要である。フランス語、中国語、ドイツ語、インドネシア語、およびタイ語のタギングマニュアルの作成は今年度中に着手したい。
3.11.4節で述べたように、GDAは他のいくつかのプロジェクトと部分的に重なっているので、標準化と共有を目指す(GDAを含む)これらのプロジェクトの性質により、プロジェクトの間での連携が重要である。特に、UNLはタグ付きテキストではなく中間言語に基づく統合的自然言語処理のプロジェクトであるが、GDAのタグ付きテキストとUNLの中間言語との間での自動変換を可能にすれば、両プロジェクトの成果の普及する範囲を足し合わせて拡大することができる。タグ付きデータによる統合という構想は、自然言語処理のみならずさまざまな領域で実現が試みられている。たとえば音声認識と音声合成のための標準タグを策定しようという動き(注)もある。動画像などにも及ぶマルチモーダルなデータの統合的な処理についてもタグ付きデータによるアプローチが有効であろう。
------------------------------
注)http://www.cstr.ed.ac.uk/projects/ssml.html
言うまでもなく、GDAの最大の課題は、いかにしてタグを普及させるかという点にある。タグの普及は、タグ付けのメリットとそのコストとの関係にかかっている。GDAタグの最大のメリットは、タグ付けされた文書が機械翻訳(特に多言語翻訳)や情報検索や質問応答などの多くの用途に再利用できることである。こうした多種の応用技術を統合する文書処理環境は、特に、多量の文書処理の需要をかかえ、また専門のタグ付け作業者を養成したりタグ付けを外注したりできる大手の機関ユーザにとってきわめて有用かつ現実的な技術であろう。
しかし、教育を含めてこうしたインフラを整えるには手間と時間がかかる上に、オペレーティングシステム等の場合と違って、タグ付けのメリットはタグの仕様や技術内容の公開と共有を前提としており、また、タグの応用に関してはいわゆるキラーアプリケーションのようなものもさしあたりは存在しない。したがって、特定の企業がデファクト標準を握って独占的な利益を上げるなどということは考えにくいので、企業が独自にタグの普及を推進することはないだろう。しかし、タグ付けが普及すればユーザはより高度なサービスを享受でき、情報処理産業全体の市場規模も拡大するはずである。インターネットが研究者のツールとして始まったのと同様に、GDAタグも研究コミュニティを出発点として普及させるのがよいだろう。さしあたっては、タグに関連するさまざまなツールや応用技術を開発しながら、タグの普及を図る必要がある。
<参考文献>