本章では、モバイルエージェントを中心とするネットワークエージェント技術に焦点をあてる。ネットワークの急速な普及により、情報サービスの内容は今後大きな広がりをみせるものと予想される。しかし、現状のような、もしくは現状の延長線上にある支援ツールのサポートのみでは、ネットワークを介してアクセス可能な膨大な量の情報やサービスの活用が困難となる恐れがある。こういった問題に対して、ネットワークエージェント技術が有効であると考えられる。ネットワークエージェントとは、人間の代理人としてネットワーク上で機能するプログラムの総称で、人間に代わって必要な情報やサービスをさがしまわったり、状況に合わせて行動を柔軟に修正するなどの機能を有することから、ネットワーク活用の有効な手段として期待できる。
ユーザがネットワークを活用して行う仕事は、多くの場合、各所に配置された情報の収集と、それらの情報を活用して行う何らかの作業である。現状において手作業でこれを行うためには、まず必要な情報が何であり、それはどこにあって、どうすれば入手でき、情報を活用するためのサービスはどこで受けることができ、それを受ける資格条件は何であり、いかにすればその条件を満足でき、どういった手順で実際にサービスを受けることができるか、などについて知った上で作業を行う必要がある。エージェント技術は、このような煩わしい手続きからユーザを開放する技術として期待できる。知的なエージェントは、ユーザの要求に応じて必要となる情報の収集方法やネットワーク上のサービスの活用方法を自分で見いだし(もしくは仲間から教わって)実行することができる。移動性を持ったエージェント(モバイルエージェント)の典型的な動きは以下のようになる。
このようにユーザのネットワーク活用を支援するエージェントが移動型であると、以下のような利点が生じる。
(1) 通信コストの削減
モバイルエージェントの利用においては、エージェントを送り出した後、結果が戻ってくるまでの間に通信回線を切断しておくことができる。他の多くのネットワーク利用法が通信回線を接続したままで作業を行うのに対し、この方法はエージェントが移動する短い時間の回線接続ですむため、通信コストを抑えることができる。これは、携帯電話などの通信コストの高い機器を使用する場合に特に大きな利点となる。
(2) ネットワークの利用性/信頼性向上
上記と類似の利点として、接続している通信回線の伝送速度が遅い場合などにも、中間的な情報はエージェントが処理し、結果のみを持って帰るモバイルエージェントの方式が有利となる。また、通信路が不安定な場合でも、エージェントが通信状態を確認しながら移動したり、場合によっては他の通信経路を用いて移動するなどして、ネットワーク全体としての信頼性を高めることができる。
(3) ネットワーク上の計算資源の活用
モバイルエージェントは資源の限られた計算機や過負荷状態の計算機上での作業を避けて、資源に余裕のある計算機へ移動して作業を行うことができる。これによって、ネットワークで接続された計算資源を有効かつ効率的に活用することが可能となる。
モバイルエージェントの問題点としては以下のものが挙げられる。
(1) 知性の実現
人間の代理人としての役割を果たすのに必要な知性をいかに実装するかは大きな課題である。モバイルエージェントに求められる知性を整理すると以下のようになる。
(2) セキュリティ
モバイルエージェントが開放型ネットワークの上で作業する場合には、さまざまな面でのセキュリティを考慮しなければならない。セキュリティの保証が不十分であると、モバイルエージェントが訪問先の計算機に被害をもたらしたり、エージェントが持ち歩く情報が盗まれて不正に利用される恐れが生じる。モバイルエージェントのセキュリティをいかに保証するかは難しい問題であるが、以下の観点から議論されている。
(3) プラットフォームの普及
いくらネットワーク環境が広まっていっても、モバイルエージェントは移動や作業を行うための基盤環境(プラットフォーム)が設置された計算機の間でしか行動できない。豊富な情報やサービスの活用はエージェントを有効なものにするための絶対条件であり、いかにプラットフォームを普及させるかはエージェント技術が成功するための重要なポイントとなる。これには、後述する標準化動向も大きくかかわってくる。
以下で日米の研究開発事例を紹介する。
(1) Flage (Field oriented Language for AGEnts)
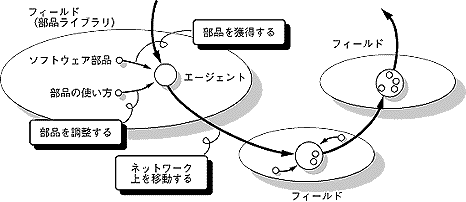
Flageは、通産省産技室の産業科学技術研究開発制度による新ソフトウェア構造化モデル研究プロジェクトの活動の一環として、情報処理振興事業協会(IPA)によって開発がすすめられているエージェント言語とその処理系である。システムは、ソフトウェアの部品やその使用方法/使用条件などを蓄積したフィールドと、ネットワーク上を移動して部品の獲得・調整を行う実行主体であるエージェントから構成される。フィールドは一種のソフトウェア部品ライブラリィと見ることができ、エージェントはこのフィールドの間を移動しながら、目的に合ったソフトウェア部品をさがしまわる。適切なソフトウェア部品を見つけると、必要に応じて部品の調整を行い、その部品を獲得することで、自ら成長していく(図3.3-1)。このようなコンセプトに基づくエージェントシステムはまったく新しいもので、ネットワーク上に配置されたソフトウェア部品を組み合わせて目的のソフトウェアを合成する開発法や、運用中の予期せぬ事態や仕様の変更要求に柔軟に対処し得るシステムの構築などへの応用が期待されている[5]。
(2) Plangent (PLANning aGENT)
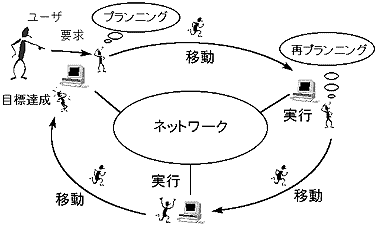
東芝が研究開発中のエージェントシステムPlangentでは、プランニング機能を有する知的なエージェントがネットワーク上を自律的に移動し、必要な情報を収集しながらユーザの作業を代行することができる。Plangentにおけるエージェントは、ユーザの要求を受けとると、それを満たすためにどこで何をすればよいかの計画(プラン)を立て、この計画に基づいて実際にネットワーク上を移動して作業を行う。何らかの事情によって当初のプラン通りの作業が行えない場合は、移動先の情報を用いて再プランニングを行い、ユーザの介入がなくても自らプランを修正して移動/実行を繰り返すことができる。これによってユーザの目的に合った結果が得られると、ユーザの元へ戻って結果を報告する(図3.3-2)。この種のエージェントシステムがネットワーク上に分散された情報の活用に有効であることが実験的に確認されている[4、10]。
(3) Aglets Workbench
Aglets WorkbenchはIBMが研究開発を続けているモバイルエージェントのためのフレームワークである。プログラマはJavaのクラスライブラリィとして提供される抽象クラスを継承することにより、プラットフォーム独立で、ネットワーク上を移動しながら実行されるエージェントプログラ厶を容易に作成することができる。AgletsのエージェントはAgletContextという環境上で実行される。また、エージェントの生成、削除、その他の制御のためのビジュアルな環境としてTahitiも用意されており、インターネット上を動き回るエージェントの制御を比較的簡単に行うことができる[7、16]。
(4) Telescript
TelescriptはGeneral Magic社が開発したモバイルエージェント記述のための専用言語である。Telescriptでは、プレースと呼ばれる非移動プロセスがネットワークの各所に分散しており、エージェントはgo命令によってこのプレース間を移動する。移動の際にはエージェントの実行コードと実行状態とが送られ、移動先では実行状態を復元してからコードが実行されるので、ネットワーク上を移動しながらの継続的な処理が実現できる。言語の実行環境であるTelescript Engineの他にTabrizと呼ばれる開発環境があり、WebからTelescriptを操作するための機能やTelescriptプロセスからHTTPリクエストを行うための機能がライブラリとして提供される[11、12、15]。
(5) OAA (Open Agent Architecture)
SRIインタナーショナルが研究開発をすすめているOAAは、モバイルエージェントシステムではないが、オープン・エージェント・アーキテクチャとしての優れた機能を持っている。基本機能としては、黒板モデルに基づくエージェント間通信、実行委託、データ指示実行、推論、プランニング(プロトタイプにおいては実装されていない)などを持つ。特に、エージェント間通信言語(ICL)と分散型黒板モデルに基づくエージェント間通信での高い透過性は大きな特徴となる。また、マルチモーダルなユーザインタフェースによるタスク委託の円滑化もOAAの特徴と言える[1、18]。
(6) その他の事例
その他の研究開発事例としては、プランニング機構を有するSoftbotを用いてインターネットの利用を支援するInternet Softbot[2]や、ネットワーク上のメッセージパッシングやマルチプロセス、リモート・エバリュエーションなどの機能を有する記号処理言語April[8]、また製品レベルでは、モバイルコンピューティングを支援するOracle Mobile Agentsや、Javaによるモバイルエージェント開発を支援するCyberAgentなどがある。
以下で、わが国として取り組むべき課題について考察する。
(1) 技術標準化の推進
広域なネットワークを活動の場とするモバイルエージェントシステムにおいては、移動可能な範囲の拡大、利用可能な情報やサービスの確保が重要であることは既に述べた。種々のシステムにおけるエージェントの動作メカニズムや外部とのインタフェースが標準化されると、AシステムのエージェントがBシステムのプラットフォームへ移動して情報/サービスを利用したり、その逆が行われたり、相互の乗り入れが可能となってエージェントの利便性が大きく向上する。この種の標準化作業は、ネットワーク環境が急速に変化している中で、将来の方向性を見定めた強いリーダシップの下ですすめるべきものである。標準化の対象としては、エージェントの生成、移動、実行、削除、位置管理、セキュリティなどといったエージェントの管理方式や、エージェント同士もしくはエージェントと人間のコミュニケーション方式、エージェントと既存ソフトウェアとのインタフェースなどが挙げられる。海外では以下のような標準化団体が既に活動を始めている。
(2) 大規模アプリケーション構築実験の実施
将来の高度情報化社会におけるエージェント技術の有効性を実証するためには、比較的大規模なアプリケーションを開発し、実験評価を行うプロジェクトが有効と思われる。全国(もしくは海外を含む)規模での実験環境を構築し、大学企業を問わず有志が参加して種々のエージェントの構築、情報/サービスの提供などをこの環境の上に展開する。このための通信インフラの整備、プラットフォームの設置、参加ルールの制定などはトップダウンに行うべきものであるが、それ以降の運用・展開・拡張などについては参加側が主体となってボトムアップにすすめていくことが望ましい。種々のアプリケーションに対しては、情報やサービスを提供する立場、エージェントを利用する立場、エージェントの管理的側面やセキュリティ、性能、効率など、さまざまな観点での公平な評価を運用中から行う。評価結果がおもわしくないものは淘汰するなどのフィードバックを設け、技術の進展を促進するのも一案である。
(3) 基礎研究の推進
アプリケーション構築の実験などにより、エージェントシステムの特徴的な機能に関する研究開発はすすんでいくものと思われる。しかし、通信インフラ技術、セキュリティ技術、エージェントの知性に関する研究、エージェントを前提とするソフトウェアのアーキテクチャの研究といった重要な項目に関する基礎研究は、公的な機関が中心となって着実にすすめるべきものであると考えられる。
<参考文献>
ネットワーク環境におけるデータベース技術は分散データベースやオンラインデータベースなど長い歴史がある。分散データベースはコンピュータネットワークに接続された複数のサイトにデータベースを分散配置し、処理効率の向上や障害対策などを図ったシステムである。分散データベース機能はすでに多くの商用データベース管理システムで実装されている。分散データベースを発展させたシステムとしては複数の異なったデータベースを管理するマルチデータベース、異機種分散データベース、連邦データベースなどとよばれるシステムがあり技術的には一定の水準に達している。オンラインデータベースはネットワークを利用した情報検索システムであり、文献情報検索や各種の情報提供サービスとして利用されている。データベース管理と情報検索の両分野は共通事項も多いが、利用形態が異なるため別々の研究分野と考えられる場合が多かった。また、データベースの更新を高速で行う必要がある応用に向けたシステムはオンライントランザクション処理システムと呼ばれ別の分野として扱われることも多い。また、電子図書館はデータベースと密接に関連しているが、これについては別項で詳説される予定である。
最近のインターネットの普及に伴い、データベース管理技術と情報検索技術の両分野にまたがるような研究や、新しいメディアを扱うための研究が盛んになっている。新しい分野としてはさまざまな情報源を統一的に扱ったり、大量のデータから知識を発見したりする研究などAI技術と関連の深いものが多い。一般の情報処理技術者や利用者の間で話題となった分野としてはマルチメディアデータベース、データウェアハウス、データマイニングなどがある。また、ウェブデータベースという呼び方をする場合が有るように WWW も広い意味でのデータベースと考えることができる。従って、最近は WWW やそのブラウザなどの関連ツールを踏まえた研究開発が盛んになっている。ネットワークとデータベースに関連する最近の話題には以下のものがある。
これら以外ではマルチメディアデータの扱いが引き続きデータベース分野の重要課題となっているので、ネットワーク関連の研究でも重要である。
上記のテーマの最初の2つ、すなわちインターネットまたはイントラネットとデータベースに関してはWWWブラウザからのデータベース検索やウェッブ検索サーバなどがすでに実用化されている。しかし、これらの機能は比較的単純なレベルにとどまっており、各種情報資源の有効利用や、データベース機能をインターネット環境で十分に発揮するような形態とはなっていない。これらの問題は次の2項目、すなわち異種情報資源の統合利用と開放系での問合せ機能の研究開発課題となっている。異種情報資源の統合利用ではDBMSで管理される構造化データや、ウェブやSGML文書などの非構造データを統合的なインタフェース、例えば問合せ言語で利用可能とすることが主な課題である。このテーマはさまざまな角度から研究されているが、インターネット環境での種々の情報の有効利用を行うためには不可欠な課題である。開放系での問合せ機能では従来のマルチデータベースのようにあらかじめ定められたサイトだけでなく、任意のサイトへの自由な問合せを実現することを課題としている。問合せ機能では属性などの構造情報が利用でき必要情報だけを送ることを指示できるので、 WWWでのキーワード検索より精度の高い検索が可能である。
情報源の交渉/協調機能は各種の高度なデータベース応用のためにデータベースなどの情報源に知的な処理を導入するアプローチである。データマイニング/知識発見では大量のデータの中から意味のある情報をどのようにして得るかが課題である。汎用的な方法も各種研究されているが、ドメインによって方法を使い分けたり、ドメイン知識を用いる方法が有効である。重要なデータほど企業秘密とされる傾向があるため、重要な研究内容が必ずしも発表されない場合が有る。CSCWのためのデータベースは重要なテーマであるが、CSCW研究の一環として作業環境や作業手順との関連を重視する必要があり、リポジトリのように独自の領域として成長していくと思われる。
米国の情報技術に関しては本研究所で昨年度調査を行った[1]。研究開発分野は5つに大分類され情報管理はその1つとなっている。情報管理分野には情報管理システム、データベース設計と管理、検索言語、等が含まれる。この分野では90年代に入って、政府の出資を受けることが難しくなっている(本調査によれば情報技術分野の資金の内情報管理分野の割合はあまり大きくなく減少傾向にあると推測されている)。その中で比較的ホットなのはインターネットとの関連の部分である。具体的には「分散マルチメディアデータベース」と「マルチメディア情報検索」がある。
分散マルチメディアデータベースはHPCCのデジタル・ライブラリ・プログラムの中で取り上げられている。このプログラムでは分散した各種の情報をネットワークでどこからでもアクセス可能とすることが課題であり、あらゆる情報が対象となる[1]。これは前節で異種情報資源の統合利用と述べたテーマに対応している。従って、図書館の電子化を主な課題とする日本の電子図書館プロジェクトと比較して対象領域が広いように思われる。ただし、個々のテーマでは図書館への応用を意識したものが多い。また、米国ではもう一つの流れとして公共/大学図書館を中心に行われているデジタルライブラリ研究があり日本のものに近い。
マルチメディア情報検索ではマルチメディア情報の検索や表示が主な課題である。マルチメディア情報の扱いは以前から情報管理/データベースの重要な課題であるが、最近のマルチメディア技術の発達によりますます重要になってきた。本委員会でも電子美術館やヒューマンメディア技術などでマルチメディア情報の検索の重要性が議論された。
欧州の研究開発プログラムの代表である ESPRIT では情報技術分野はソフトウェア技術、部品とサブシステム技術、マルチメディアシステムの3つに大分類されている[2、3]。ソフトウェア技術は4つのテーマに分類され小分類として34のタスクがあるが、10のタスクがテーマ3の「分散システムとデータベース技術」に属している。これらのタスクを以下にあげる。
なお、上記の内 Information infrastructure は Work Programme-1994にはなく、1996の改版でタスク34として追加されたものである。また、大分類のマルチメディアシステムには12のタスクがあり、Multimedia storage and retrieval のようにデータベースと関連の深いタスクが含まれている。このようにEspritではデータベースは分散システムやマルチメディアシステムと密接に関連する分野と位置づけられ研究が行われている。
日本ではかつてインターオペラブル・データベースの研究開発プロジェクトがあったが、これは技術的には分散/マルチデータベースに対応するテーマであった。また、第5世代コンピュータプロジェクトにおける知識ベースの研究開発は知識処理とデータベースの統合を目指すアプローチを取っていた。最近ではいくつかの電子図書館プロジェクトがある。しかし、電子図書館プロジェクトには大学のデータベース研究者はあまり参加していない。
大学関連では平成8年度から科学技術研究費重点領域研究として「メディア統合及び環境統合のための高機能データベースシステムの研究開発」(略称:高度データベース)が開始された。ここでは「高度応用のための情報ベースモデルとその実現技術」、「マルチメディア情報ベース技術」、「分散発展型データベースシステム技術」、「協調能動型データベースシステム技術」の4班で研究が行われており、前節で述べた研究テーマの大部分に関連する研究開発が行われている。これらの研究の中には電子図書館に有用な技術もかなりあると思われるが、図書館への応用を目指した研究は明示的には行われていない。
ネットワークとデータベースに関連するわが国の研究開発は産業界を含んだものとしては電子図書館プロジェクトが関連するが、それ以外にはいくつかのプロジェクトで副次的に取り上げられている程度である。それに対し米国ではディジタル・ライブラリ・プログラムが日本の電子図書館プロジェクトと比較し広い視野で情報資源の問題を捉えているのをはじめ、情報管理が情報関連の5大分野の1つに位置づけられるなどかなりの政府資金が投入されている。また、欧州のEspritでもデータベース技術が情報技術の中でも重要な技術の1つとして位置づけられている。情報管理/データベース技術は情報インフラの重要な構成要素であり、情報産業の振興のためにより積極的な取り組みが望ましい。
本分野のプログラムを新たに考える場合、情報管理やデータベース一般をテーマとする案ともう少し焦点を絞った形にする案の両者が考えられる。一般的なテーマでのプログラムとする場合はEspritと同様に主な技術課題といくつかの応用をあげ総合的な研究開発を行う。しかし、このようなプログラムは情報技術一般に関するプログラムができてその一環として実施するのでなければ困難かもしれない。これに対しより明確な目標を掲げたプログラムの方が実現が容易な可能性がある。このようなプログラムの候補としては「情報資源統合」があげられる。
情報資源統合では国内外のさまざまな情報資源をネットワークを利用して統一的に利用する環境を実現することを目標とする。ここで情報資源統合は前記の「異種情報資源の統合利用」であげた課題だけでなく、関連の課題も含むより広い意味で使用する。また、各種情報資源の管理技術も対象とする。さらに電子図書館とは別のテーマではあるが、電子図書館もその応用の一部と位置づけることにより、シーズとニーズのバランスの取れた研究開発を行う。電子図書館は技術的には(分散)マルチメディアデータベースの一種と考えることができる。従来の電子図書館プロジェクトではデータベース研究開発との連携があまりとられていない(参加企業内では連携が取られている場合がある)。情報資源統合というより広い視点のテーマの一部に位置づけることにより、電子図書館に関しても新しい観点の導入などが期待でき、データベース研究者にも大きな応用分野に取り組むモチベーションを与えることができると思われる。なお、日本語の図書館という用語と比較し英語のLibraryはsubroutine library などより広い意味で使うことができるので、図書館というよりカタカナでライブラリと書いた方が良いかもしれない。また、情報資源統合というテーマの応用は電子図書館に限定されず、より広く産業への適用が期待できる。
<参考文献>
本稿では、マルチモーダル対話システムの研究状況について、最近のものを中心に紹介する。これまでに行われてきたさまざまな試みとともに、その技術的な課題や実現にあたっての問題点などについて述べたい。本稿では、人間と多様な情報のやりとりを対話的に行う人工的なシステムを「マルチモーダル対話システム」と呼ぶが、人間とコンピュータとのインタフェースとしての視点から、「マルチモーダルインタフェース」と呼ばれることも多い。
マルチモーダルインタフェースの定義として、[長尾96]では次のように述べられている。
「モダリティ」というのは、情報伝達において用いる認知的手法あるいは様式のことである。この場合に、単にコンピュータとのインタラクションの手段として複数のメディアやチャンネルが利用できるというだけでなく、有機的に統合されることが重要である。
少しわかりやすい例としては、音声、身振り、表情などの複数の情報伝達様式を組み合わせて、人間との情報のやりとりを対話的に行うものがあるが、概念としては、かなり幅広いものである。
これまで、マルチモーダル対話システムに関するさまざまな提案や研究開発が行われてきた[長尾 96, 田村 95, 黒川 94]。具体的には、
などが主として取り上げられてきた。多様な情報伝達様式を有機的に統合した対話システムが理想的なものであるが、多くのものは、アイデア段階、研究開発の初歩的段階にとどまっている。
マルチモーダル対話システムの研究にはさまざまな要素がある。紙面がある程度限られているので、いくつかの研究の事例を以下に紹介するが、これ以外にもさまざまな研究が行われている。
まずあげられるのは、音声認識と磁気センサーによる指さしを組み合わせた “ Put That There” である[Bolt 80]。これは巨大なスクリーンに向かってすわり、ある対象物を指さして“Put That”と言い、次に別の点を指さして、“There”と言うと、その対象物が移動するというものである。
Human Reader[末永 92]は、視覚による頭部と手指の検出を行って、人間の状況を理解し、音声認識との統合を行うものである。スクリーンの前に座った利用者の顔および手指の動作を正面、側面および上面に設置した3台の小型テレビカメラでとらえ、実時間画像処理を行うとともに音声コマンドの認識も行う。また CG による顔画像の合成と音声合成との統合も行っている。
TOSBURG II[竹林 94]は、ハンバーガーショップでの注文システムを想定して、ワードスポッティングをベースとする音声認識によって自由な話し言葉による音声対話を目指すものである。アニメーション、合成音、応答文テキストによる応答生成を行っている。音声応答キャンセル機能を組み込み、システムからの音声応答をさえぎった音声入力を可能としている。
Talkman[Nagao94]は、人間と自然なインタラクションを行うエージェントを目指して試作された、人間的な顔と表情を持ち、音声言語で対話するシステムである。連続音声認識技術による音声対話と、3次元的な顔のグラフィックスによる多様な表情のリアルタイム生成を行う擬人化エージェントのプロトタイプである。
電総研では、システムに、人間の行動や発話を見聞きし、また自らも発話や行動によって人間に情報を伝える能力を持たせることを目指して、音声認識、音声合成、画像認識、画像合成を統合したマルチモーダル対話システムの研究開発を進めている[Hasegawa 95]。このシステムの特徴は、第一に、画像による人物識別と音声対話を組み合わせることで、識別された人物の名前を、システム側から呼んで話しかけるという「自発性」を実現したことである。また複数の人物を識別することで、第三者への伝言機能を実現している。さらに3次元的な顔のグラフィックスにおいて、ユーザとの視線の一致を行うようになっている。
また Mr. Bengo[新田 96]は論争を支援する知識ベースシステムに、顔認識、表情合成、音声認識、音声合成、WWWブラウザなどのモジュールを統合したマルチモーダル実験システムである。
身振りや表情の認識については、昨年には、顔とジェスチャーの自動認識について、第2回の国際会議[FG 96]が開催されており、近年、研究が活発化している。たとえば RWC つくば研究センターでは、人間の身振りに対して連続 DP 法を用いたスポッティング認識を行い、ジェスチャー認識を行っている[高橋 94]。
画像認識による読唇と音声認識の統合については、音声認識にとって典型的な情報統合の例である。画像認識手法には、モデルを設定して特徴量を求めるもの、主成分分析などによって画像の全体から特徴をもとめるものなど、さまざまなものがある。目標の設定は、例えば騒音中の音声認識性能を向上させるという比較的わかりやすいものである。人間と機械によるspeechreadingについては、一昨年、NATOのワークショップが開催されている[Stork 96]。
こうした研究の背景としては、現在、普通に使われているコンピュータシステムのインタフェースを超えて、実世界と相互作用できるような人工物やその人工物のためのインタフェースの実現を目指そうという流れがある。アプリケーションとしてのイメージも、これまでのいわゆる計算機ソフトというイメージから、電子秘書や情報執事といった、自律的な実体のイメージをもったものが指向されるようになってきている。
人間の行動や発話を見聞きし、また自らも発話や行動によって人間に情報を伝える能力をシステムに持たせたいと考えると、そこで対象としなければならない情報の内容や、情報を伝えるためのメディアや伝達様式は、従来のものとは、大きく異なってくることが予想される。
対象となる情報の内容は、より日常的で、生活に密着し、より人間的なものとなるだろう。ちょっとした情報を相互に伝えあい、共有しあうことになるだろう。数値やテキストから音声や動画像の連続的なメディアに伝達媒体が変化するのも、そこで伝えたい内容が、文字で表わされるようなものだけから、たとえば、微妙なニュアンスや感情といったものにまで広がる可能性があるからであると考えられる。
マルチモーダル対話システムの研究にはさまざまな要素がある。大きく分類すると、情報統合、ノンバーバルコミュニケーション、対話性の 3 つの側面がある。
これらは相互に関係もしているが、技術的にはそれぞれがある種の研究領域を形成しており、それぞれに固有の題材、問題意識、方法論の元に研究が行われてきているように思われる。
(1)情報統合
情報統合というのは、音声や画像などの種々の情報を統合的に処理することである。組み合わせる情報の種類や、統合の仕方によって、さまざまな情報統合が考えられる。たとえば、音声認識と画像認識を統合することで、これまで単独では得られなかった認識性能を達成するというのは、わかりやすい例である。画像認識による読唇との統合によって、騒音中の音声認識性能を向上させるというのは、情報統合によってある特定の情報伝達機能の性能を向上させることの例である。
また“Put That There”の場合には、指示語のさす対象物は、音声だけでは特定できず、指示動作との統合によってはじめて曖昧性を解消することができる。
複数の情報伝達様式の統合による新しい機能の実現というのも、その技術的な特徴である。たとえば、画像認識による人物識別と音声合成の統合によって、システムから話しかけるという「自発性」を実現したり、人物識別と音声対話の統合によって、第三者への伝言機能を実現したりするというのが、この例である。
ここで注意すべきことは、入力(認識)の統合だけでなく、出力(合成)についても情報統合の対象であることである。たとえば音声認識を行う際に、擬人化エージェントによる表情の表出によって、認識結果についてのシステムの状態(認識結果についての確信の程度など)を示すということも、情報統合の一例である。
(2)ノンバーバルコミュニケーション
ノンバーバルコミュニケーション(あるいはノンバーバルインタフェース)というのは、言葉によらない対話という意味で、身振り、表情、視線、韻律などを用いた情報伝達のことである。
コニュニケーションに用いられる音声と画像情報は、まず、その多様性に特徴がある。人間が、人間同士のコミュニケーションにおいて、自らの体を用いて生成でき、また認識(理解)できるものは、発話であり、身振りや表情である。
身振りと言っても、さまざまな動作がある。表情についても、幸福、悲しみ、恐怖、嫌悪、怒り、驚きの基本6表情だけでなく、対話において出現するものには実にさまざまなものがある[Ekman 75、黒川 94]。例えば、CG (擬人化) エージェントが顔だけを持つ場合と、腕と体を持って仮想空間内で行動する場合では、伝達の対象となる情報の内容の種類は、後者の場合が、格段に多いことが予想される。
またこれらの情報は、それ自身がある種の意味内容を伝達するだけでなく、しばしば、対話の制御に使用される。音声対話において、韻律は、発話権の授受やタイミングを制御するという役割を持っている。身振りや表情にも、対話において同様の役割がある。
韻律や身振りなどは、対話の制御という点では、対話の意味内容や特徴的な表層の言語表現に対して補助的に働く。したがって、対話の制御のための情報伝達としては、その現象が必ず起こるわけではない。また、非常に微妙なものであり、パターン認識の対象として難しいという性質がある。この性質は、認識を難しくするだけでなく、その前段階の学習も難しくするという点に注意が必要である。
(3)対話性
自然言語(テキスト)による対話システムや音声による対話システムには、それぞれ固有の技術的特徴と研究課題があるが、マルチモーダル対話システムにおける対話性というのは、情報統合やノンバーバルコミュニケーションの両方にも関係する技術的特徴である。
たとえば、マウスなどのポインティングデバイスと音声認識の統合を行うような場合、マウスで指示された項目に音声認識の対象となる語彙を絞って音声認識を行うことによって、音声認識性能を向上させることが考えられる。これは対話の文脈を特定する手段として、情報統合を利用するものである。
また、あいづちやうなずきなどを利用して、対話の時間的な側面を制御する新しい情報伝達様式によって、より生き生きとした、円滑な対話を実現することが考えられる。人間にとって、多様な内容を扱える対話や、自由なタイミングの対話が可能となることは、重要である。
これらの技術的特徴をもったマルチモーダル対話システムの実現に向けて、わが国としても関連する領域における研究開発を支援する必要があるものと考えられる。
このうち研究開発課題として、とくに重要、かつ緊急性が高いものは、「情報統合技術」と、「学習・自己組織化技術」である。
情報統合技術は、マルチモーダル対話システムにおいて、音声や画像などを用いた多様な情報伝達様式を統合する技術である。情報統合によって、ある特定の情報伝達機能の性能を向上させたり、統合による新しい機能の実現を目指すものである。
このために、音声認識、音声合成、画像認識、画像合成などの個別的なパターン処理技術の向上も必要であるが、情報統合技術はこれら個別的な技術の融合領域、あるいは境界領域であり、個別の技術に対しても情報統合のわく組みからの新しい視点や価値観の導入がより重要である。
さらに、現在のコンピュータシステムを超えて、実世界と相互作用できるようなより高度なマルチモーダル対話システムを実現するためには、学習・自己組織化技術がより重要となる。
ノンバーバルコミュニケーションや対話性についての技術的特徴のところでも述べたように、実世界と相互作用できるような人工物や、そのインタフェースの実現のためには、その対象の多様性が大きいということが問題である。カテゴリーが決まっていても、多様性が大きいために、その認識や合成を行うことが難しい。また、明確なカテゴリーが存在しなかったり、その役割が明確でなかったりするという点が、重要なポイントである。
たとえば、音声認識においては、話者変動、語彙の増加、環境音などによる認識性能の低下というよく知られた問題以外にも、自由なタイミングでの音声対話が難しいことや、1つのタスクで動作するシステムを他のタスクに移植することが難しいといった問題がある。また身振りなどの動画像認識においては、認識実験の対象とされているカテゴリー数がまだ少ないということの他に、カテゴリーの決定自身が難しい。
こうした多様性が大きく、明確なカテゴリーが存在せず、また役割が明確でないような性質の現象を扱っていくためには、カテゴリー間の識別性能を高めるという、通常のパターン認識手法の高度化だけでなく、学習・自己組織化という側面で、教える手間を減らし、言葉では教えにくいことを教えられるようにし、また、対話における状況と内容の関係を教えられるようにすることが求められる。
<参考文献>