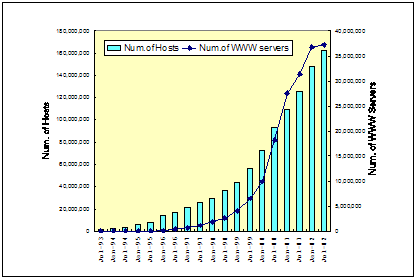
図1 インターネットに接続するコンピュータ台数とWebサーバ数の推移[5]
山名 早人 委員
インターネットの普及により、WWW上に蓄積される情報が急増している。このように急増する多種多様な情報を検索するためにGoogle(http://www.google.com/)やFAST(http://www.alltheweb.com/)など数々のWWWサーチエンジンが存在する。2002年末時点で世界中に存在する総Webページ数は、約70億ページと推定[1]され、年率100%の勢いで増加を続けている。
Webページの中から自分が必要とする情報を見つけ出すためには、Googleに代表されるWWWサーチエンジンが必要不可欠となっている。しかし、Googleが検索対象とするWebページ数は、2002年末時点で約31億ページ、世界第2位のFASTは約21億ページであり、これらの現存するWWWサーチエンジンを用いても世界中の全Webページを対象にした検索はできない。また、WWWサーチエンジンに入力されるキーワードは平均2語であり、2語という限られた情報を用いて、ユーザが欲するWebページを見つけ出すことは、一般的に困難である[2]。このような問題に対して、WWWサーチエンジンは、①膨大なWebページの効率的な収集とインデックス化、②検索結果のランキング、という2つの重要な技術を利用している。
以下では、まず、インターネットの発展に関わる統計データを紹介した後、これらの技術についての最新技術を紹介する。
図1、図2に示すようにインターネットに接続するコンピュータ台数は毎年増加を続けている。1998年から3年間の平均でみるとコンピュータ台数、Webサーバ数は、それぞれ年率約1.5倍、2倍で増加を続けている。ただし、2002年1月までと2002年1月以降での傾向に変化が見られ、図3に示すようにインターネットに接続するコンピュータ台数の増加率とWebサーバ台数の増加率が逆転し、2002年1月以降、Webサーバ台数の増加率が鈍化してきていることが分かる。
3.4.2.1 Webページの特徴
2000年のIBM, SUN, Compaqの研究者らの調査[2]によれば、Webページは、図4に示すような構造(蝶ネクタイ構造)をしている。相互にリンクを張り合うWebページ(図4中のSCC)は、全体の28%であり、outlink[3]のみを持つページ(図中IN)とinlink[4]のみを持つWebページ(図中OUT)がそれぞれ22%、22%であり、その他のリンク的には中心部分(図中のSCC,
IN, OUT)と関連がないページが全体の28%である。
したがって、単純にリンクのみを辿ることでは、全てのWebページを収集することはできない。これに対して、一つの解決手段は、Netcraft社(http://www.netcraft.co.uk/)がWebサーバ数を調査する手法として採用しているように、「IPアドレスを順番に直接指定しhttpプロトコルの標準ポートである80番ポートをアクセスする手法」であるが、Webサーバが80番ポート以外で立ち上がっている場合や、Webサーバのトップディレクトリからのリンクが存在しない場合等は、やはり、収集できないページが発生する。
図1 インターネットに接続するコンピュータ台数とWebサーバ数の推移[5]
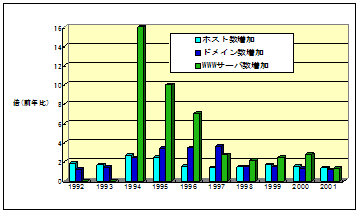
図2 インターネットに接続するコンピュータ台数、ドメイン数、Webサーバ数の増加率[5]
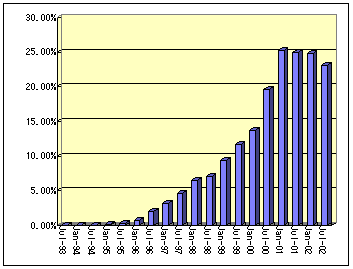
図3 インターネットに接続するコンピュータ台数に占めるWWWサーバ台数[5]
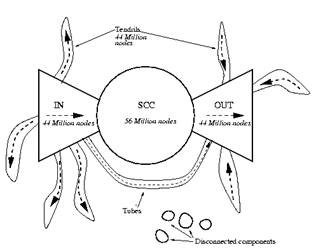
図4 Webページの特徴[2]
3.4.2.2 世界と日本のWebページ数推計
2002年7月時点でのドメイン毎のWebページ数(URL数)の推計を表1に示す。各ドメインの割合はNetwork Wizards社(http://www.nw.com/)のデータに基づいている。また、Lawrence氏が提案した手法[1]に基づき、2002年7月現在での全世界のWebページ数を約70億URLと仮定し、各ドメイン数の比率から各ドメインのURL数を算出した。また、1ページのバイト数を10KBと仮定し、各ドメインにおける総バイト数を算出した。
ドメイン名 |
全ドメイン中の割合 |
総ページ数(億URL) |
サイズ(GB) |
|
| net | Networks | 32.4% | 22.68 | 22,680 |
| com | Commercial | 30.0% |
21.00 |
21,000 |
| edu | Educational | 5.0% | 3.50 | 3,500 |
| jp | 日本 | 5.0% | 3.50 | 3,500 |
| au | オーストラリア | 2.0% | 1.40 | 1,400 |
| ca | カナダ | 2.0% | 1.40 | 1,400 |
| de | ドイツ | 2.0% | 1.40 | 1,400 |
| it | イタリア | 2.0% | 1.40 | 1,400 |
| uk | イギリス | 2.0% | 1.40 | 1,400 |
| er | ブラジル | 1.0% |
0.70 |
700 |
| es | スペイン | 1.0%
|
0.70
|
700
|
| fi | フィンランド | 1.0%
|
0.70
|
700
|
| fr | フランス | 1.0%
|
0.70
|
700
|
| nl | スイス | 1.0%
|
0.70
|
700
|
| org | Organizations | 1.0%
|
0.70
|
700
|
| se | スウェーデン | 1.0%
|
0.70
|
700
|
| tw | 台湾 | 1.0%
|
0.70
|
700
|
| us | アメリカ | 1.0%
|
0.70
|
700
|
さらに、表2に2001年末時点でのjpドメインの第二レベルドメイン毎のWebページ数の推計を示す。これは、第二レベルドメイン毎に約50のWebサーバにランダムにアクセスし、各サーバが持つWebページ数を求め、JPNIC(http://www.nic.ad.jp/)が公開しているドメイン数との積をとることで求めた。なお、表1ではjpドメイン内のWebページ数は約3.5億と算出されている。これに対し、西村、山名らが2001年に行ったjpドメイン内のWebページ数は推計[3][6]でも、表2に示すように、約3.1億ページであり、表1の推計がほぼ実態に即していると判断できる。
表2 日本のWebページ数(2001年12月現在)[3]
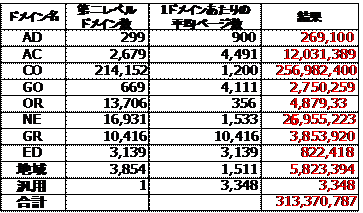
3.4.2.3 推定Webページ数に対する商用検索システムのカバー率の推移
推定Webページ数を元に、1998年1月以降の商用検索システムが全Webページ数(推定)に対してカバーする率を求め、図5に示した。2000年からカバー率が上昇に転じているのは、Googleが検索対象Webページ数を増加させてきたことに起因する。
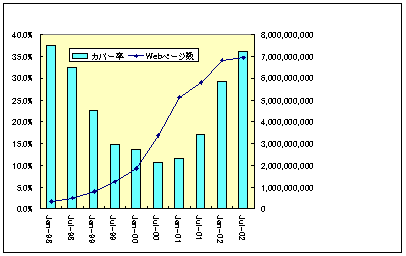
図5 推定Webページ数に対するサーチエンジンのデータカバー率の推移[7]
本節では、膨大なWebページの効率的な収集手法とインデックス化の高速化手法について紹介する。
3.4.3.1 効率的なWebページ収集手法
Webページ収集には、収集ロボット(あるいはクラウラー(Crawler))と呼ばれるソフトウェアを用いる[8]。しかし、収集ロボットの収集能力に物理的な限界がある以上、何らかの方法で「効率的」な収集を実現する必要がある。
効率的な収集を実現する手法としては、全てのWebページを集めることは元々不可能だという前提に立ち、①決められた時間内で重要と判断されるWebページ[9]から優先的に収集する方法と、②収集ロボット自体を分散化し高速に収集をする方法、さらに、③Webページの更新差分のみを収集できるようにWWWサーバ自体を専用化する方法、の3つに分類することができる。
3.4.3.1.1 Webページの重要度に基づいて効率的な情報収集を行う方法
Webページの重要度として、①Webページの更新頻度を用いる方法[4][5]、②Webページのスコア[10](3.4.4で詳述)を用いる方法[6][7]がある。
(1)Webページの更新頻度を用いる手法
Webページの更新頻度を用いてデータの鮮度を保つ手法に関する研究を示す。
① Stanford大学のChoらは、2000年に「Webページの実際の更新頻度を調べると共に、それを基にした収集方法」を提案した[5]。まず、PageRank[11]を元に選ばれた重要なサイトを対象として、更新頻度の調査を行い、得られた結果からポアソン分布に基づいて更新頻度のモデル化を行う。更新頻度の分布を図6に示す。X軸は更新の間隔、y軸は該当するWebページの全対象Webページに対する割合を示す。ポアソン分布は、ランダムに起こる事象の確率分布を求めるのに適しており、Webページの更新頻度の確率分布を求める場合にもよく用いられる。Choらは収集したWebページの更新頻度の分布が、ポアソン分布に従うことを確認し、その前提に基づいて、収集されたWebページの新鮮さを最大に保つ収集方法を考案している。新鮮さとは、収集されたWebページが最新のものと同一である割合のことを指す。
通常の収集ロボットは全てのページを一定の周期で収集する。しかし、更新頻度が高いページは、索引付けがなされて検索システムで検索可能になったときには、既に最新の情報ではなくなっているという問題を持つ。しかし、Choの提案する収集方法では、ページ毎に収集頻度を変えることにより、検索システム内のデータの新鮮さを常に一定に保つことができる。
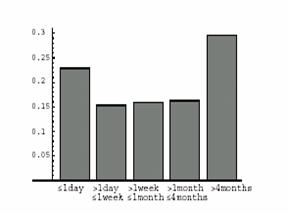
図6 更新頻度の分布([5]より引用)
また、新鮮度について、Choらは2つの指標を定義している:
これらの指標に基づき、freshnessを上げageを下げる手法、あるいは、freshnessのみを上げる手法が考えられている。
② オーストラリア・シドニー大学のEdwardsらは2001年、Choの研究[5]を踏まえた上で、更に一般的なモデル化を提案[4]した。Choの研究では、PageRankを基準として重要なページを選び、それらのページからモデル化を行っていたが、Edwardsらの研究では収集時に同時に更新頻度の調査を行うことで、収集対象となる全てのページのモデル化を行う。最初は全てのページを1ヶ月周期で収集し、更新されていたページに対しては、設定されている更新間隔の半分、すなわち2週間周期で収集を行う。さらに、2週間後に更新されていたページに対しては1週間周期で収集を行うにより、全てのページの更新頻度をモデル化する方法を提案している[12]。
また、収集ロボットの能力を考慮し、どのページを優先して収集を行えば、システム内のデータの全体的な鮮度が最も高くなるかを考察し、全体のデータの新鮮さをもっとも高く保つ為のスケジューリングのモデル化を行っている。図7に示すように収集対象のWebページを以前に収集した時(t0)からの間隔で分類し、各Webページの優先度を決定している。一度収集したWebページ全体をbと定義し、ある時点(t0+Δt)において更新が発生したWebページをyとする。また、Δtの間に再収集されたWebページの数をxとする。また、aをΔtの間にWebページが更新される確率とする。そして、実際に各ページを収集したときに更新間隔を測定することにより、各ページのaを求め、収集されたWebページの新鮮さを最大に保つようにスケジューリングする手法を提案している。
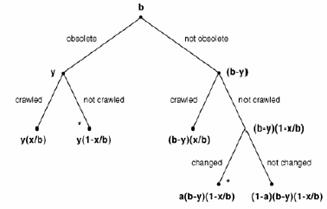
図7 収集対象となるWebページの分類([4]より引用)
(2)Webページのスコアを用いる手法
各Webページのスコア(重要度)を定義し、重要だと思われるページを優先的に収集することにより、効率的に収集を行う手法を紹介する。
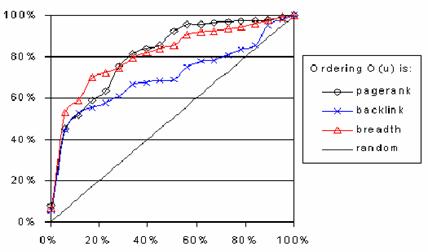
① Stanford大学のChoらは、1998年に、(1)Webページへのリンクを見つけた順番に収集していく収集ロボット、(2)バックリンク(あるいはinlinkと呼ぶ)の多いWebページへのリンクを優先して収集を行う収集ロボット、(3)PageRankが高いWebページへのリンクを優先して収集するロボットの3つを用いて、どの方法が最も効率よく収集できるかを比較した[6]。実験は、Stanford大学内のWebページを用い、重要なページを、「コンピュータという単語を含み、バックリンクが多いページ」と定義し、実験を行った。その結果、PageRankに基づいて収集を行う方法[13]は安定して高い成果を得られることがわかった。図9に示す通り、全体の80%のページを収集した時点で、収集対象のページ(重要ページ)のほぼ全てを収集し終えている。図中、x軸が全対象Webページに対する収集率、y軸が全需要Webページに対する収集率を示す。幅優先の収集方法は、PageRankを基にした方法には及ばないものの全体の80%を収集し終えた時点で、対象のページの約90%を収集しており、バックリンクを基にした収集方法では、対象のページの約80%しか収集されていなかった。
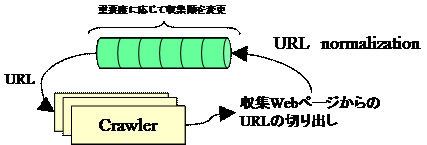
図8 収集順の変更方法
 |
| 全Webページに対する収集率 |
② Compaq System Research CenterのNajorkらは、2001年に、一般的に用いられている幅優先の収集方法で、十分に効率的な収集ができることを示した[9]。通常の収集ロボットでは、リンクが見つかった順に収集を行うが、幅優先の収集方法では、違うサーバに交互にアクセスするように収集を行う。幅優先に基づく収集方法により、同一Webサーバへの連続的なアクセスを減らすことができる。また、リンクを順に辿っていく収集方法では、同じサイト内のページを連続して収集してしまうが、幅優先の収集方法では、違うサイトに同時にアクセスすることから、幅広いトピックを効率的に収集することが可能であるという利点も持つ。
Najorkの研究では、重要なページの評価基準としてPageRankを用い、1日ごとに収集されたページを用いてPageRankを更新し、各日に収集した全ページのPageRankの平均を求めた。60日間収集を行った結果、幅優先の収集方法で集めたページでは、1日目に集めたページのPageRankが2日目以降に収集したページに比較し高いという結果が得られた(図10)。また、2日目以降に収集されたページのPageRankは平均して、1日目の4分の1以下だった。この結果から、幅優先の収集方法では、収集の初期の段階で、重要だと考えられるページを多く収集できることを示す。
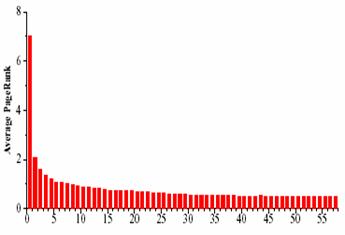
図10 収集を開始した時からの経過時間(hour)ごとのPageRankの分布
(x軸は一日単位)([9]より引用)
3.4.3.1.2 収集ロボットを分散化させる手法
本項では、収集ロボットを分散させることにより収集速度を向上させる研究を紹介する。
① Transarc社のBowmanらが1994年に提案したHarvest[10]では、収集と検索を共に分散して行うことにより、システムへの負荷を分散させる方法を提案している。Harvestのシステム構成を図11に示す。Harvestでは、Gathererと呼ぶ収集ロボットをネットワーク上に分散配置し、収集を行う。しかし、Gathererが収集するURLは事前に静的に決められており、スケジューリング方法については特に考慮されていない。ただし、分散して収集を行うという世界で初めての提案となった。
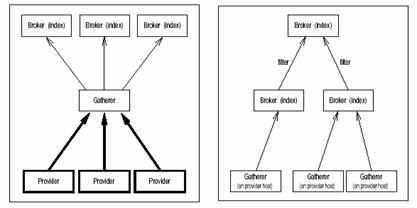
図11 Harvestの構成([10]より引用)
② 東工大の内藤らが2000年に提案した超分散サーチエンジン[11]では、各Webサーバに各Webサーバが持つページをインデックス化する機能を持たせ、Webサーバ自体がクエリーを受け付けることのできる機能を実装している。つまり、Webサーバ自体が小規模の検索システムとして動作する。さらに、サーバのハードウェアスペックに余裕がある時には、自Webサーバ内のページからリンクが張られているページを収集し、検索できるデータを増やす手法も提案している。超分散サーチエンジンを用いた情報検索は、リンクを辿ることによって実現される。論文では6つのモデルが提案されているが、いずれも、クエリーをあるWebサーバに送り、検索結果として得られたページが存在するサーバに順次クエリーを伝えて探索する手法をとる。このため、検索のターンアラウンド時間は長くなる。
③ 早稲田大学の村岡らが1998年に提案した分散型ロボット[12]は、地理的に分散して設置した各ロボットの負荷を均等化することにより、Webページの収集時間を短縮しようとする方法である。各収集ロボットにランダムにWebサーバを割り当てた場合に比較して、ネットワーク及びWebサーバの負荷を均衡化することによって、数倍高速に収集を行えることを示している。村岡らの方法では、同じWebサーバに対するアクセスでも、収集ロボットのネットワーク環境の違いにより、負荷を均等化することにより高速化できることを示している。また、各収集ロボットの制御用に管理用サーバを置き、動的に各収集ロボットが収集するURLを動的に決定している。管理用サーバには、各収集ロボットとサーバの距離や新規に発見されたサーバの情報が送られ、その情報を基に各収集ロボットの負荷を均等化する。収集ロボットとサーバの距離(データ転送速度)の計測は、サーバのトップから50URLを収集し、収集にかかった時間から判断している。また、JPドメインからランダムに抽出した6,500サーバを、国内17箇所に配置した収集ロボットで、負荷を均等化して収集を行った結果を示している。実験の結果は図12に示す通りであり、ランダムに収集を行った場合の予測値より、約11倍の速度で収集が行えたとしている。
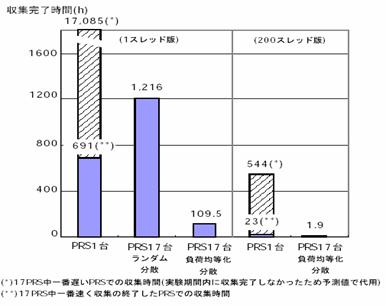
図12 実験結果([12]より引用)
3.4.3.1.3 Webサーバを専用化する手法
本項では、物理的な収集時間を短縮させるためにWebサーバを専用化する手法についての研究を紹介する。専用化する手法は大きく2つに分類される。一つはWebページ更新時に変更された部分の元のページに対する差分を収集ロボットに収集させる(送る)ことができる機能をWebサーバに持たせる方法であり、もう一つは、いつ更新されたかをWebサーバ側が収集ロボットに対して通知するようにWebサーバに機能を持たせる方法である。これらの手法は、一旦、対象となるWebページを収集完了後に更新を効率的に行うために用いられる。
① Western Research Lab.のMogulらが1997年に提案したDelta-Encoding[13][14][15][16]では、キャッシュを有効に行う為にHTTPプロトコルへの改良を提案している。Delta-Encodingでは、Webサーバ内の各ページに対し、UNIXのdiffコマンドを用いて求めた変更の履歴を保存する。クライアント(収集ロボット)からリクエストがあった時には、Etagからクライアントが保持しているページのバージョンを判断し、クライアントが保持しているページと最新のページとの差分を送信する。クライアントでは、送信された差分とキャッシュされているページから最新のページを作成する。従来の一般的なキャッシュでは、ページが更新されていると判断した場合には、そのページの全てを取得し直している。しかし、Douglisの調査[8]で示されているように、HTMLファイルは更新頻度が高く、全体の50%程度は一ヶ月以内に更新されるため、従来のキャッシュでは、大きな効果を上げることはできない。これに対してDelta-encodingでは、HTMLファイル内の、更新された部分だけをサーバから取得し直し、クライアント側で保存されているページと更新された部分から動的にページを生成することにより、更新頻度が高いページに対しても効率的に収集することを可能とした。
② Stanford大学のBrandmanらの2000年の研究[17]では、先にChoが行ったWebページの更新頻度の調査[5]から、通常の収集頻度ではサーバに対して無意味なリクエストが行われてしまうことを示している。例えば、1ヶ月に1回収集を行ったとすると、全体の5割のページは更新されておらず、無駄な収集を行ってしまうことになる。その解決策として、サーバ側がサーバ内の各ページの更新情報をまとめ、収集ロボットは定期的にサーバの更新情報を取得し、更新があったページだけを収集する方法を提案した。Brandmanの方法により、無駄なアクセスが無くなり、また、Webページの更新間隔に見合った収集が可能になり、収集データの新鮮さを保つことが可能になる。
③ Illinois大学のGuptaらは2000年、Brandmanの提案した方法[17]をベースに、更新するのに最適な時期がきたらWebサーバ側から収集ロボットに通知するというシステムを提案している[18]。更新時期(Webサーバが収集ロボットに通知する時期)は、収集にかかるコスト(ページのサイズ)やページの重要度、ページが更新されてからの経過時間から総合的に判断する。
④ 筑波大学の加藤らが1998年に提案したPlanet[19]は、分散環境の為のミドルウェアである。Planetを導入しているWebサーバ群内では、対象のWebサーバにエージェントプログラムを送り込むことによって、当該Webサーバと同一LANのWebサーバ上のデータ収集を行う。収集したデータは、いくつかのファイルにまとめると共に、圧縮して送り返す。これにより、ネットワーク負荷を減らして収集を行うことが可能になる。
⑤ ブラジルのMinas Gerais連邦大学のSilvaらが1999年に提案したCoBWeb[20]は、既存のプロキシを用いた手法を提案している。検索システム内のデータの更新を、プロキシを用いて行うCache parasiteという方法を提案している。提案されているキャッシュ機能を持ったプロキシでは、キャッシュされているWebページにユーザからリクエストがあると、リクエストされたWebサーバから当該Webページのヘッダ情報を取得し、更新されていると判別された場合には、新しくページを取得する。また、更新されていないと判別されたときには、キャッシュされているページをユーザに送信する機能を持つ。Cache parasiteでは、このようなキャッシュ機能を持ったプロキシと連動し、プロキシで更新を感知したページを検索システムに送信することで、収集を行うことなく検索システム内のデータの鮮度を保つ事を可能にしている。
3.4.3.2 インデックス化の高速化
収集したWebページを検索可能にするためには、インデキシングを行う必要がある。このインデキシングには膨大な時間がかかることが知られており、例えば、2001年3月時点で、Googleはインデキシングに1~2ヶ月をかけていた[14]。このようなインデキシングを高速化する手法として、Stanford大学のMelnikらは、2001年にパイプライン化する手法を提案している。図13に示すように、インデキシングの行程を、「loading」「processing」「flushing」の3つに分割し、図14に示すようにこれらの行程が3並列で動作するようにスケジューリングを行う。これによって、図15に示すように3割程度の高速化が達成できることを示した。
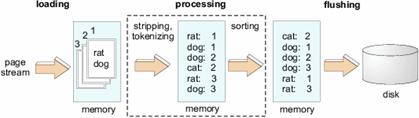
図13 インデキシングのパイプライン化1([21]より引用)
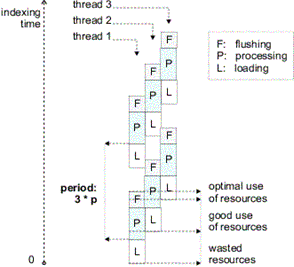
図14 インデキシングのパイプライン化2([21]より引用)
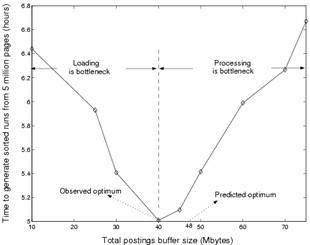
図15 パイプラインの各行程の調整による処理時間の変化([21]より引用)
検索結果のランキング手法としては、従来のIR[15]研究で用いられているベクトル空間モデル等、各Webページの内容に基づいた手法に加えて、WWWサーチエンジンでは、リンク情報を用いてランキングを行っている。本節は、リンクを用いた主要なランキング手法について紹介する。
① HITS[22][23]
HITSは、1997年にIBMのKleinbergらにより提案されたコミュニティ発見のためのアルゴリズムであり、その中でWebページの重要度を表すAuthority度(スコア)とHub度(スコア)が定義された。これらの値は、Webページの重要度を表す指標である。
HITSでは、ハイパーリンクをリンク元からリンク先への推薦行為と考え、多くのページからリンクされているページを有用なページとして、Authorityページと定義し、また、多くのAuthorityページにリンクしているページを良質なHubページと定義した。
Authorityスコア・Hubスコアの計算
まず、計算対象となる全てのページpに対して、Authorityスコア(Authority(p))とHubスコア(Hub(p))を与え、まず、1で初期化する。次に、以下の計算をAuthority(p)及びHub(p)の値が収束するまで繰り返す(p→qはページpがページqに対してリンクしていることを示す)。概念図を図16に示す。図中の○がページを表し、aがAuthorityスコアを、hがHubスコアを表す。
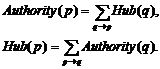
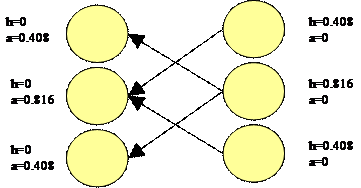
図16 HITSの概念図
(hがHub(p)を、aがAuthority(p)を表す)
② PageRank[24][25]
PageRankは、1998年にStanford大学のPageとBrinが提案したWebページの重要度を表す指標である。PageRankの基本的な考え方は、ネットサーフィンをする人のモデル化(ランダムウォーク)に基づく。ネットサーフィンをする人は、Web上の各ページのリンクをランダムに辿ると仮定し、各ページに辿りつく確率から各ページのランキングを行う。ランキングに用いられるスコアの計算を(式1)に示す。イメージとしては図17のようになる。
![]()
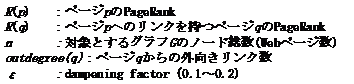
R(p)をページpの持つPageRank、R(q)はページpへのリンクを持つページqのPageRankを示す。Nは対象とするグラフG(Webページをノードとし、Webページ間のリンクをエッジとしたグラフ)のノード総数(Webページ数)、outdegree(q)はページqからの外向きリンク数である。また、グラフG内の全てのWebページのPageRankの合計は1であり、εは通常0.1~0.2の間に設定される。
モデルとしては、グラフGのノードpから(1-ε)の確率でp上のリンクを辿り、ノードqに進むが、εの確率でリンクとは関係なくノードrに 進むランダムウォークのモデルである。つまり、ユーザは(1-ε)の確率で現在のWebページからのリンクを辿り、εの確率で全く無関係なWebぺージへジャンプするとの仮定の元でネットサーフィンのモデル化を行っている。他にもリンク構造をランキングに応用している検索システムは多数あるが、PageRankの特徴としてはScamWebに強いという点が挙げられる。Scam
Webとは、あるページのランキングを上げるために、複数のダミーサイトからのリンクを張っているページのことである。PageRankでは、このようなダミーサイトのスコアを小さくすることが可能である。
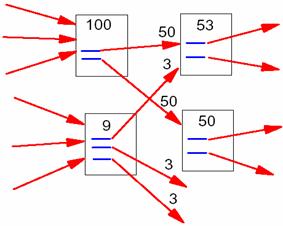
図17 PageRankのイメージ図([24]より引用)
WWWサーチエンジン構築上重要となる、①膨大なWebページの効率的な収集とインデックス化、②検索結果のランキング、という2つの技術について紹介した。なお、紙面の都合上紹介できなかったが、WWWサーチエンジンのランキングを評価する指標としてDCG(Discounted Cumulative Gain)[26]、MRR(Mean Reciprocal Rank)[27]等が提案されている。また、国立情報学研究所(NII)が主催した第3回NTCIR Web Task[16]の評価として文献[28]でこれらの値が紹介されているので、利用者の立場としての評価指標として参考にされることをお勧めする。
| [1] | Steve Lawrence and Lee Giles:” Accessibility and Distribution of Information on the Web”, Nature, vol. 400, pp. 107-109 (1999) |
| [2] | A. Broder, R.Kumar et.al. :"Graph structure in the Web : experiments and models", Proc. of the 9th WWW Conf. (2000) |
| [3] | 西村真幸, 山名早人:”ドメイン毎のWebページ数の偏りを考慮した日本のWebページ数推定調査”, 第64回情処全大,2X-6 (2002.3) |
| [4] | Jenny Edwards, Kevin McCurley, John Tomlin: “An Adaptive Model for Optimizing Performance of an Incremental Web Crawler”, Proc. of the 10th WWW Conf., http://www10.org/ (2001) |
| [5] | Junghoo Cho, Hector Garcia-Molina: “The Evolution of the Web and Implications for an Incremental Crawler”, Proc. of the Conf. on Very Large Databases (2000.9) |
| [6] | Junghoo Cho, Hector Garcia-Molina, Lawrence Page :“Efficient crawling through URL ordering”, Proc. of the 7th WWW Conf., pp. 161-172 (1998) |
| [7] | Marc Najork, Janet L.Wiener :“Breadth-first search crawling yields high-quality pages”, Proc. of the 10th WWW Conf., http://www10.org/ (2001) |
| [8] | Fred Dougilis, Anja Feldmann, Bachander Krishnamurthy : “Rate of Change and other Metrics: a Live Study of the World Wide Web”, Proc. of the USENIX Symp. on Internet Technologies and Systems (1997.12) |
| [9] | Marc Najork,Janet L.Wiener:“Breadth-first search crawling yields high-quality pages”, Proc. of the 10th WWW Conf., http://www10.org/ (2001) |
| [10] | C.Mic Bowman, Peter B.Danzig, Darren R.Hardy :“Harvest: “A Scalable, Customizable Discovery and Access System”, Technical Report CU-CS732-94, University of Colorado-Boulder (1994) |
| [11] | 内藤清一郎,小林亜樹,山岡克式,酒井善則:“超分散サーチエンジンを用いた効率的情報探索について”, 信学技報, SSE99-200, pp.123-128 (2000.3) |
| [12] | 村岡洋一,山名早人、田村健人、河野浩之,森英雄,浅井勇夫,西村英樹,楠本博之,篠田洋一:“ Internet広域分散サーチロボットの研究開発”,第20回IPA技術発表会論文, http://www.yama.info.waseda.ac.jp/~yamana/IPA/ (2001.10) |
| [13] | Jeffrey C. Mogul, Fred Douglis, Anja Feldmann, Balachander Krishnamurthy :“Potential Benefits of Delta Encoding and Data Compression for HTTP”, Proc. of SIGCOMM, pp. 181-194 (1997.9) |
| [14] | - :”What is HTTP Delta Encoding”, http://www.webreference.com/internet/software/servers/http/deltaencoding/intro/ |
| [15] | James J.Hunt, Kiem-Phong Vo, Walter F.Tichy : “An Empirical Study of Delta Algorithms”, IEEE Software Configuration and Maintenance Wks., (1996) |
| [16] | Fink Dmitry, Sloutsky Alexander : “Delta Encoding Extension for HTTP/1.1”, http://www-comnet.technion.ac.il/~cn33s00/ |
| [17] | O,.Brandman,Junghoo Cho,Hector Garcia-Molina,Narayanan Shivakumar: “Crawler-Friendly WebServers”, Proc. of the Workshop on Performance and Architecture of Web Servers (2000.6) |
| [18] | Vijay Gupta,Roy Campbell :“Internet Search Engine Freshness by Web Server Help”,UIUCDCS-R-2000-2153 (2000.1) |
| [19] | 加藤和彦:“モーバイルオブジェクトシステムPlanet: ネットワークコンピューティングのためのソフトウェア基盤”, テレコムフロンティア (1998) |
| [20] | Altigran S.da Silva, Eveline A. Veloso, Paulo B.Golgher: “CoBWeb-A Crawler for the Brazilian Web”, Proc. of the Sixth Symp. on String Processing and Information Retrieval (SPIRE'99), Cancun, Mexico, pp.184-191(1999.9) |
| [21] | S.Melnik, S.Raghavan et.al.:"Building a Distributed Full-Text Index for the Web", Proc. of the 10th WWW Conf. (2001) |
| [22] | David Gibson, Jon M. Kleinberg, and Prabhakar Raghavan: "Inferring Web Communities from Link Topology", Proc. of the 9th ACM Conf. on Hypertext and Hypermedia (Hypertext'98), (1998) |
| [23] | J. M. Kleinberg: "Authoritative sources in a hyperlinked environment", In Proceedings of the Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 668-677 (1998) |
| [24] | Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd, “The PageRank Citation Ranking: Bringing Order to the Web” , Stanford Digital Libraries Working Paper (1998) |
| [25] | S. Brin, L. Page, “The Anatomy of a Large-Scale Hypertextual Web Search Engine”, http://www-db.stanford.edu/~backrub/google.html |
| [26] | K.Jarvelin and J.Kekalainen: “ IR Evaluation Methods for Retrieving Highly Relevant Documents”, Proc. of ACM SIGIR 2000, pp.41-48 (2000) |
| [27] | E.Voorhees: “The TREC-8 Question Answering Track Report”, Proc. of TREC-8, NIST Special Publication 500-246, pp.77-82 (1999) |
| [28] | J.Eguchi, K.Oyama, E.Ishida, N.Kando and K.Kuriyama :” Evaluation Methods for Web Retrieval Tasks”, Proc. of the Third NTCIR Workshop, pp.415-422 (2002.12) |