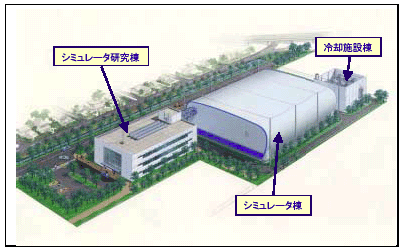
図1 地球シミュレータ施設
第3章 ハイエンドコンピューティング研究開発の動向
3.4.2 地球シミュレータ開発を終えて
横川 三津夫 委員、 妹尾 義樹 委員
1. はじめに
平成9年度から開始した地球シミュレータ開発は、平成14年2月末にピーク性能40テラフロップスの世界最高速を達成し、成功裡にその開発が終了した。Linpackベンチマーク性能では、638台の計算ノード、5104プロセッサにて35.61テラフロップス(ピーク性能比87.2%)という驚異的な実効性能を達成した。これは、米国ASCI
Whiteシステムが持っていた世界一の記録(7.22テラフロップス)の約5倍にあたり、ピーク性能、実効性能ともに世界一と認められたわけである。
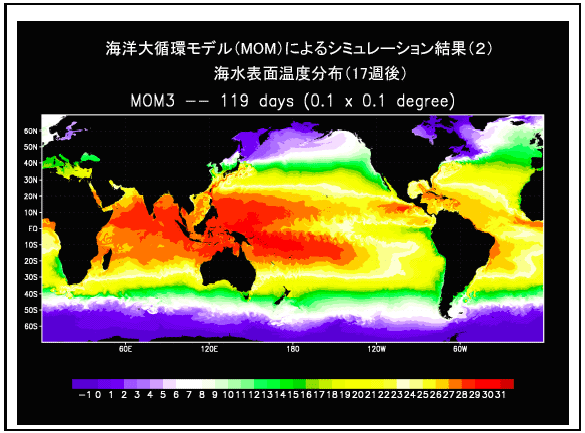
実際の応用プログラムにおいても、大気大循環モデルのT1279L96(格子点数3840×1920×96)において、計算ノード320台を用いて14.5テラフロップス(ピーク性能比70.8%)の高い実効性能を達成しており、地球シミュレータを利用した今後の数値シミュレーションの成果に大きな期待がかかっている。(末尾に付録として大気大循環と海洋大循環の計算結果例を添付しておく。海洋の方では、黒潮が見えていることに注目。)
当初から開発に携わってきた我々としては、たった5年間の開発期間ではあったが、さまざま出来事が思い浮かび感無量の気持ちで一杯である。本稿では、開発の経緯を振り返るとともに、完成した地球シミュレータのハードウェア及びソフトウェアの概要、並列プログラミングインタフェース、及び応用プログラムの性能などについて述べる。
2. 地球シミュレータ開発の始まり
地球シミュレータ開発が決定された平成8年頃は、地球温暖化やエルニーニョ現象等の地球規模の現象が注目されていた。温室効果ガス等の排出は、地球温暖化に甚大な影響を及ぼしていると言われており、排出削減目標が設定されるなど我々の日常生活にも大きな影響を与えると考えられた。また、エルニーニョ現象は局所的な集中豪雨や干ばつなどの被害をもたらすものとの推測がなされていた。
旧科学技術庁航空・電子等技術審議会地球科学技術部会は、平成8年7月に取りまとめた報告書「地球変動予測の実現に向けて」において、地球変動予測研究の推進にあたっては、地球変動プロセス研究、地球観測及び数値シミュレーションを三位一体として、総合的かつ計画的に研究開発を推進すべきであるとの提言を行った。これを受けて、旧科学技術庁計算科学技術推進会議地球シミュレータ部会は、平成9年7月に報告書「『地球シミュレータ』計画の推進について」をまとめ、数値シミュレーション分野の推進について、地球規模の複雑な諸現象をシミュレートできる超高速並列計算機システム「地球シミュレータ」の開発と、地球シミュレータ上で動作する高度な応用ソフトウェアの開発を目標とする計画を策定した。この報告書では、近年の科学技術分野に特化したスーパーコンピュータのめざましい発展とそれに基づく計算科学の進展について述べられ、観測困難な現象や実験不可能な現象を解明するための強力なツールとして、数値シミュレーションによる方法が非常に重要であるとされている。これに基づき、気象・気候分野の代表的な数値シミュレーションにおいて、約5テラフロップス(TFLOPS:1秒あたり1兆回の浮動小数演算を実行できる計算処理速度を表わす単位)の実効処理性能を有する大規模並列計算機システム「地球シミュレータ」の開発が開始された訳である。
平成9年度の開発開始時点では、宇宙開発事業団及び旧動力炉・核燃料開発事業団の共同プロジェクトとしてスタートしたが、平成10年度からは宇宙開発事業団、日本原子力研究所及び海洋科学技術センターの3者により開発が実施されることとなり、共同プロジェクトチーム「地球シミュレータ研究開発センター」を組織し、完成までの研究開発を行った。平成14年2月の地球シミュレータ完成を以って、このチームは解散した。
3. 地球シミュレータ施設
海洋科学技術センター横浜研究所(横浜市金沢区)に建設された地球シミュレータ施設は、図1に示すように、シミュレータ研究棟、シミュレータ棟、冷却施設棟から構成されている。
図1 地球シミュレータ施設
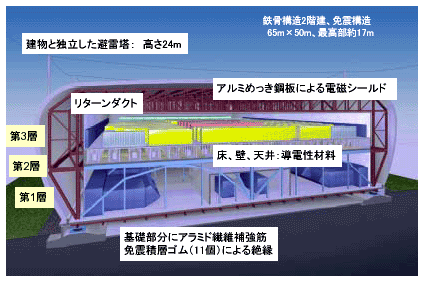
図2 シミュレータ棟の構造
地球シミュレータが設置されるシミュレータ棟(図2)は、幅50m、奥行き65m、高さ17mの鉄骨2階建て、免震構造をしている。3層構造をしており、第1層は計算機システムを冷却するための空調機器などが設置される。高さ約170cmの第2層のフリーアクセスフロアは、計算ノード(PN)と結合ネットワーク(IN)を繋ぐ83200本の電気ケーブル(全長約2800km)を収納する他、冷気を計算機システム全体に分配する空調ダクトスペースとして利用している。第3層は、地球シミュレータ本体及び周辺機器が設置されるスペースである。
また、この施設の特徴として、地球シミュレータの誤動作の原因となる外部からの電磁波を完全にシールドしており、また設置スペースではライトガイド式照明システムを採用し、蛍光灯による照明システムで発生する電磁ノイズを除去した。ライトガイド式照明システムとは、計算機室外部に設置された光源部(マルチハロゲン灯)からの光だけを特殊フィルムに反射させて照明するものである。これにより、電磁ノイズを軽減するばかりか、ランプ交換等の保守性向上、天井の空気排出面積の増大による冷却効果の増加などの効果がもたらされた。
4. 地球シミュレータのハードウェア
地球シミュレータのハードウェアが達成すべき計算性能は気象・気候分野の数値シミュレーションで5テラフロップス以上の実効処理速度である。ハードウェアの設計指針については既にいろいろなところで述べているのでそちらを参照されたい[1,
2]。
地球シミュレータは、図3に示すように、640台の計算ノードをクロスバネットワークで結合させた分散メモリ型並列計算機である。各計算ノード(PN: Processor
Node)は、ピーク性能8Gflopsのベクトル型計算プロセッサ(AP: Arithmetic Processor)8台が主記憶装置16GBを共有する共有メモリ型並列計算機となっている。したがって、全体ではAPが5120台、ピーク性能は40Tflops、主記憶容量10TBとなる。各PNは、8台のAP、32台の主記憶ユニット(MMU:
Main Memory Unit)、リモートアクセス制御装置(RCU: Remote Access Control Unit)及び入出力プロセッサ(IOP:I/O
Processor)から構成されている[3, 4]。 外部磁気ディスク装置は全部で600TB、カートリッジライブラリシステムは1.5PBの容量を持っている。
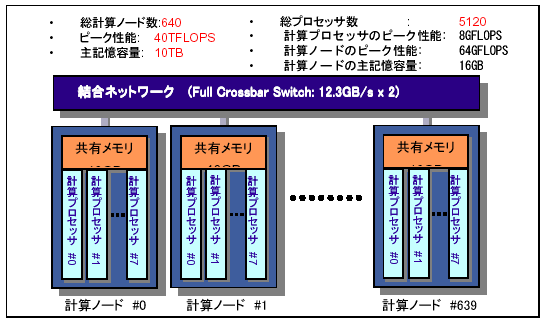
図3 地球シミュレータのハードウェア構成
APは、ベクトル処理部(VU: Vector Unit)、スカラ処理部(SU: Scalar Unit)、プロセッサネットワークユニット(PNU:
Processor Network Unit)及びアドレス制御部(ACU: Address Control Unit)から構成され、1つのLSI上に実装される。AP用LSIのクロック周波数は500MHz(一部1GHz)である。SUは、4ウェイのスーパースカラであり、128個の汎用レジスタ、2ウェイセットアソシアティブ方式の命令キャッシュとデータキャッシュをそれぞれ64KBづつ実装している。また分岐予測や投機実行の機能を持つ。VUは、6種類(加算、乗算、除算、論理、ビット列論理、ロード/ストア)のベクトル演算器と72個のベクトルレジスタからなるベクトル演算器セット8個で構成され、最大8Gflopsの性能を有している。32台のMMUには、主記憶素子としてDRAMベースの128Mbitの高速RAMを採用し、2048バンク構成とした。各々のAPは、主記憶システムとの間に32GB/sのバンド幅を持っており、1PNで256GB/sを確保している。
RCUは、クロスバネットワークと直接接続され、クロスバを介した送信、受信をAPと独立に動作させることができる。クロスバネットワーク(IN: Interconnection
Network)は、128台のクロスバスイッチを実装したデータパス部(XSW: Internodes Crossbar Switch)と2台の制御部(XCT:
Internodes Crossbar Control Unit)から構成されている。XCTは、PN間の転送経路の予約、競合調停等を行い、128台のXSWを介して実際のデータが転送される。IN及びRCUは、PN間データ転送機能、PN間同期等の機能を持つ。データ転送機能では、同期型転送と非同期型転送がサポートされており、主記憶上の連続した領域のデータを転送するブロック転送の他に、非同期型転送としてストライド付きベクトル転送、リストベクトル転送が可能である。
地球シミュレータでは、省スペース及び省電力を図るために、半導体技術、パッケージング技術、実装技術、冷却及び電源技術等に21世紀初頭の技術を大胆に取り入れた。LSI加工技術では、0.15μmのCMOSテクノロジーと銅配線技術を用いた。これによって、CMOSによるベクトルプロセッサで500MHz(一部1GHz)の高速動作を可能にした。また、1チップ・ベクトルプロセッサを達成するためにLSIの大型化を追求し、約20mm×20mmのダイに約6000万トランジスタ、約5000ピンを実装した。パッケージング技術では、微細配線加工技術を駆使した大型ビルドアップ基板上に、LSIをベア実装する技術を用いた。さらに、冷却技術ではヒートパイプによる冷却方法を採用し、約140Wにも達するAP用LSIの発熱に対処した。図4に計算プロセッサ(AP)のパッケージ図(左)と写真(右)を示す。
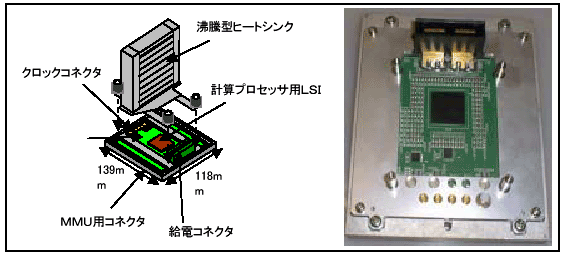
図4 計算プロセッサ(AP)パッケージ
5. 地球シミュレータのシステムソフトウェア
本節では、地球シミュレータのシステムソフトウェアについて、特に高並列処理とこれを支えるプログラミングインタフェースを中心に解説する。
5.1 地球シミュレータシステムソフトウェアの概要
地球シミュレータのシステムソフトウェアは、図5に示すとおりである。地球シミュレータは、640ノード5120プロセッサという世界最大の計算リソースが結合されたシステムである。スケーラビリティー拡大は、この大規模な計算リソースが効率よく動作させるための機能拡張である。地球シミュレータ特有機能には、専用ジョブスケジューラ、並列ファイルシステムPFS、バッチデバッグ機能、地球シミュレータ専用ハードウェア制御機能、HPF地球専用機能などが含まれる。ジョブスケジューラは、5120のプロセッサ、メモリ、I/Oなどの巨大リソースをスケジュールするためのソフトウェアで、ジョブの効率よいスケジューリングやステージング・デステージングによるI/O処理と計算処理のオーバラップなどにより、システム全体の稼働率を高め、しかも投入されたジョブのターンアラウンド時間を最小化するように設計されている。
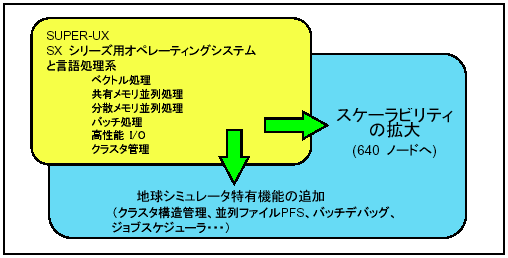
図5 地球シミュレータのソフトウェア構成
図6に、地球シミュレータ上で巨大ジョブが実行される様子とこれを支えるシステムソフトウェアの特徴を示す。地球シミュレータの複数ノードを用いる計算は分散メモリ上のプログラミングが必要になるため、MPI(Message Passing Interface)またはHPF(High Performance Fortran)のいずれかでプログラムが作成される。コンパイル、リンク処理を経て生成された実行形式プログラムは、基本的にバッチ処理としてジョブスケジューラに投入される。プログラムは、ハードウェアとMPIによって実現された高性能のノード間通信を用いて実行され、また、複数ジョブは効率よくジョブスケジューラにより計算リソースが割り当てられる。ファイルシステムは、ノードごとにバラバラに扱うこともできるが、並列I/Oが必要なプログラムは、並列ファイルシステムPFSをFortranやCでサポートされる通常のファイルアクセスで利用可能である。またMPI-IOを用いてPFSを用いることも可能である。大量のデータは最終的には磁気テープライブラリに格納されることになるが、このライブラリと磁気ディスクとの間のステージング・デステージングは自動化が可能である。また、高並列マシンで重要となる、プログラムのデバッグ、チューニング作業をサポートする種々のツール群も用意されている。
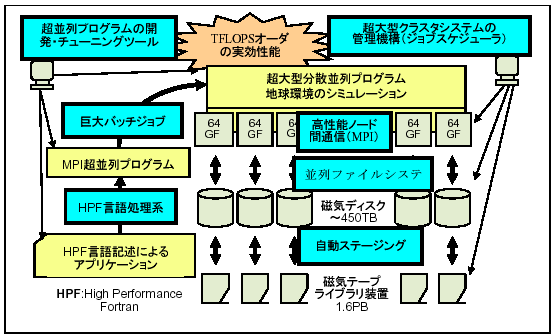
図6 地球シミュレータソフトウェアの特徴
5.2 地球シミュレータのオペレーティングシステム
地球シミュレータのOSは、640ノードという多数の計算リソースを管理するために、クラスタ構造を導入して制御している。クラスタとは、16ノードをまとめたものであり、OSによるシステム管理の単位である。また、大規模分散並列処理に対応するために、高速ファイルアクセスが可能なファイルシステムを導入するとともに、並列ファイル入出力機能を提供している。運用におけるジョブ配置では、1つのクラスタ(Sクラスタ)を会話型処理、小規模バッチ処理用とし、その他の39個のクラスタ(Lクラスタ)を大規模バッチ処理用に割り当てることを想定した機能を充実させた。
地球シミュレータ研究開発センターが独自に開発した運用・管理ソフトウェアは、ジョブスケジューラ、大容量テープライブラリシステム上のファイル管理システムなどから構成されている。Lクラスタ群では、単一ジョブ環境を提供しているが、そのためのジョブ配置は使用するファイル等の配置を含めて非常に複雑である。ジョブスケジューラは、ジョブが実行されるべき計算ノード予約やそのノードにローカル接続されている磁気ディスクへのファイル配置、ジョブのアロケーション等複雑な制御を行い、地球シミュレータ利用効率の向上を目指している。
地球シミュレータのOS開発でジョブスケジューラの開発とともに、最も苦労した点は、5120という膨大な数のプロセッサが結合された巨大システム上でスケーラビリティーを確保することである。スケーラビリティーについては、地球シミュレータの開発スタートから、OSのすべての部分について詳細な検討が行われた。解決したスケーラビリティーの問題は大きく分けて、次のものがある。
| (1) | 性能的問題 逐次的にすべてのノードに渡って処理を行うことを避ける必要がある。たとえば、マルチノードジョブの開始にあたり、マスターノードがすべてのノードに順次必要なリソースをコピーするような、ノード数nとしてnに比例する時間を要する処理は徹底的に排除する必要がある。バイナリーツリーなどの方式で、すべてlognの処理に置き換えられている。集中制御を分散制御に置き換えて、1個所へのアクセス集中を避けることも重要である。 また、マルチノード間のリソースの排他制御などのためのノード間ロック制御の高速化も重要である。単に、ロック取得開放処理の高速化だけではなく、ロック取得要求がスピンウェイトを構成するなどして、ノード間の通信機構に負荷をかけないようにすることが肝要である。数百台のノードが取得失敗を繰り返すとシステム全体に非常な負荷をかけることになる。 |
| (2) | 容量的問題 リソースの管理などで、オーダnの記憶容量を要する管理を徹底的に排除する。通信バッファとして用いる領域も、通信相手ごとに確保するような方式が採用できない。また、リソースにより、トータルの容量諸元が膨大となるため、これら諸元を管理するビット幅にも注意を払う必要がある。 |
| (3) | タイムアウト関連 ノードの故障検出など種々の異常の判断にタイムアウト(一定間隔の無応答)が用いられるが、これらの値の最大システムでの最悪値を厳密に推定し、設定することが重要である。OS処理で高速性が必要でノード間高速通信装置(IN)を用いるものがあるが、MPIが大容量のブロック通信を処理していると、これらが待たされるケースがある。MPIの高速通信を妨げないようにしつつ、OS処理でタイムアウトを発生させないために種々の工夫が必要であった。 |
| (4) | 故障対策 640ノード5120プロセッサがあると、いくらそれぞれの構成要素の信頼性が高くとも、一定以上の故障率を覚悟する必要がある。このためには、1構成要素のエラーでシステム全体がストップすることのないシステム管理方法が重要となる。また、システムを落とさずに構成要素の交換や復旧処理が行えることも重要である。 |
5.3 並列ファイルシステム
640ノードをすべて使うような巨大なジョブが1ノードに接続されたディスクを共有して大量のI/Oを行うと、大きくスケーラビリティーを損なう。また、それぞれのノードがローカルI/Oを明示的に記述することで高性能I/Oを実現できるが、プログラミングが大変であり、また生成された数百個のファイルの管理も大変となる。これらの問題を解決するために、ファイルシステムとしてはユーザからはグローバルに唯一のものとして扱え、しかも各ノードからの並列I/O処理を実現したのが、並列ファイルシステムPFSである。PFSの構成を図7に示す。
PFS上のファイルは、ストライピングされ、指定されたブロック単位でサイクリックにそれぞれのノードに接続されたファイルシステムに格納される。このファイルにプログラムからアクセス要求が出ると、FALと呼ばれるライブラリがアクセス対象となるデータの位置を同定し、INネットワークを用いて対応するノードのFile
Serverに要求を出す仕組みになっている。各ノードから特定のノードに接続された物理ディスクにアクセスが集中すると性能は出ないが、そうでなければ、並列I/Oによる性能向上が得られる。
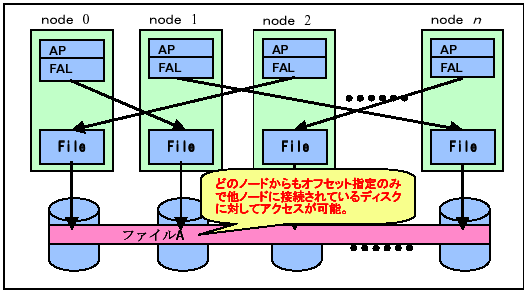
図7 並列ファイルシステムPFS
5.4 地球シミュレータのプログラミングインタフェース
地球シミュレータで満足できる性能を得るには、1プロセッサ内のベクトル処理、1ノード内8プロセッサの共有メモリ並列処理、ノード間の分散メモリ並列処理のすべてを効率よく行う必要がある。図8に、これらそれぞれで利用できるプログラミングインタフェースを示す。これらは、基本的にはSXシリーズで提供されるものと同じであるが、地球シミュレータではノード数が多いため、ノード間のスケーラビリティーが得られるように強化がなされている。
ここで、ノード内の共有メモリ並列化においてもMPIとHPFがサポートされていることに留意する必要がある。たとえば、5120プロセッサの並列処理を行う場合には、ノード間を640並列の並列処理としてMPIまたはHPFで記述し、ノード内を自動並列化またはOpenMPを用いるハイブリッドの並列処理か、5120プロセッサを対象としてMPIまたはHPFを用いる1階層の並列処理のいずれかを選択できる。これらの正確な得失については、今後の種々のアプリケーション並列化と評価結果をまたねばならないが、一般にいって、ノード内での並列処理においてデータアクセスローカリティーが得られる場合には、ハイブリッドの方が有利である。たとえば、すべてのプロセッサが参照するread
onlyのデータがある場合、ハイブリッドでは、これらのデータのコピーはプロセッサ数ではなくノードの数だけ用意すればよい。また、Linpackの場合には、係数行列をブロック分割して、ブロック単位に消去操作を進めるが、分散メモリシステムの場合、枢軸ブロック内の消去操作が逐次処理となり、並列化率を低下させる要因になる(これを避けるため、高並列システムでは、係数行列を碁盤の目状に分割して、枢軸ブロック内消去も並列処理ができるようにするのが一般的である。ただ、この場合にはpartial
pivotingにおいて、列方向の通信が発生する)。ハイブリッドの並列化では、共有メモリ内で、枢軸ブロック内消去が、これ以外の処理と合わせて負荷分散できるため、係数行列の行方向の分割のみでも、高い並列化効率が得られる。
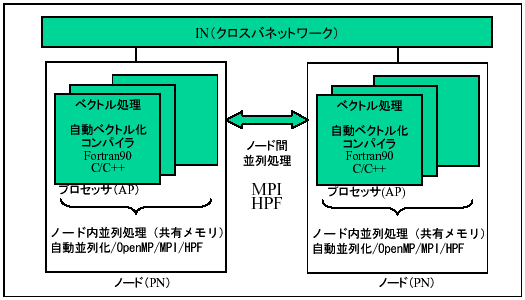
図8 地球シミュレータ上のプログラミングインタフェース
一方で、1階層の並列処理は、1種の並列化インタフェースだけで並列処理が記述できるため、プログラミングはハイブリッドより容易である。また、同期、通信操作も、データアクセスローカリティーにおいて効率に差がなければ、ハイブリッドよりも、1種の並列化インタフェースを用いる方が、わずかだが効率が良い(たとえば、5120プロセッサのバリア同期を行う場合、自動並列化で8プロセッサ内の同期を行い、さらにノード単位で640ノードの待ち合わせをMPIで実行するより、5120プロセッサの同期をMPIだけで行う方が効率が良い。ノード内のMPIの同期処理は共有メモリ機構を用いて効率よく実装されていることにも留意する必要がある)。
5.5 地球シミュレータのMPI(Message Passing Interface)
地球シミュレータのような大規模分散メモリ型計算機上でプログラムを効率的に実行するには、並列プログラムの高速化、特に通信処理の最適化が大切であり、そのためにユーザプログラムから利用できるライブラリのデータ転送性能値を評価することは重要である。ここでは、地球シミュレータの計算ノード内および計算ノード間でのMPIの通信性能に関する測定結果を示す。地球シミュレータのMPIライブラリでは、MPI-1及びMPI-2をサポートしており、MPI-1の関数、MPI-2の主要関数の性能評価を行った。MPIの性能測定には、新しく開発されたMPI-1/MPI-2関数の性能を詳細かつ多角的に測定するためのツール
MPI Benchmark program library for MPI-1/MPI-2 (MBL1/MBL2)を用いることにした[5]。
地球シミュレータ上での仮想メモリ空間は、ローカルメモリとグローバルメモリの2つが存在している。グローバルメモリはRCUが直接アクセス可能な領域であり、グローバルメモリ間でのRMA(Remote
Memory Access)転送が可能である。グローバルメモリは全グローバルメモリを一元的に管理する仮想グローバルメモリ空間にマッピングされている。このグローバルメモリ領域中に、Fortran90の動的割り付け(Allocate文)によってユーザアプリケーション中の配列を割り付けることができる。
これらのメモリ空間を利用したMPIライブラリの実装では、グローバルメモリをMPIライブラリの通信バッファ(以下、MPI通信バッファ)に用いている。したがって、MPI関数の引数として指定するユーザが確保したデータ領域(送受信バッファ)をローカルメモリまたはグローバルメモリに置くか、さらにノード内通信及びノード間通信のどちらを行うかによって、MPIの内部処理は以下の4つのケースに分類される。
(1) 送受信バッファがローカルメモリにあり、かつノード内通信が行われる場合
(2) 送受信バッファがローカルメモリにあり、かつノード間通信が行われる場合
(3) 送受信バッファがグローバルメモリにあり、かつノード内通信が行われる場合
(4) 送受信バッファがグローバルメモリにあり、かつノード間通信が行われる場合
送受信バッファがローカルメモリにある場合は、MPI通信バッファがとられるグローバルメモリ領域との間でメモリコピーが必要であるが、送受信バッファをグローバルメモリ上に確保した場合にはメモリコピーは必要ない。ノード間通信が行われる場合には、送信元ノードでのMPI通信バッファであるグローバルメモリ領域から、送信先ノードでのMPI通信バッファであるグローバルメモリ領域へクロスバネットワークを介したデータ転送が行われる。
この結果、内部処理におけるメモリコピーやデータ転送等の処理数(メモリコピー回数とノード間データ転送回数の和)は異なる。内部処理で用いられるメモリコピーはベクトル化されており、特にノード内のグローバルメモリを用いた通信は、グローバルメモリ間でのメモリコピー1回でデータ転送が実現されているため高速処理が期待される。また、ベクトル化されたメモリコピーがパイプライニング処理されるために、データ量が大きい場合には2回のメモリコピー処理が1回とみなせるようになる。これによってノード内通信では、転送量が多くなるにつれて、送受信バッファをローカルに配置した場合の処理性能はグローバルメモリに配置した場合の処理性能に近づくと考えられる。
(1)MPI-1関数の性能評価
MPIは、MPI/SXをベースに開発されており、MPI-2、MPI-IOがサポートされている。また、ノード間並列化におけるスケーラビリティーの改善はもとより、地球シミュレータの専用ネットワーク機能の利用インタフェースのサポートや、MPIプログラムのチェックポイントリスタート機能など種々の強化が行われている。
地球シミュレータ上でMPI-1の関数について性能測定を行った。MPI-1の同期通信関数MPI_Sendと非同期通信関数MPI_Isendについて、MPIランク0とランク1のプロセス間で行われるpingpong通信パターンでの性能を測定した。また送受信バッファをグローバルメモリに割り付けた場合と、ローカルに割り付けた場合の両方の性能を測定した。
まず、計算ノード内でのMPI_SendとMPI_Isendによるpingpong通信パターンでのスループットを図9に示す。この計測結果から、MPI_Send、MPI_Isend共に最大スループットは64MB転送時でほぼ飽和し、その値は14.8GB/sであった。MPI_SendとMPI_Isend間での最大スループットにおいて大きな差は見られない。なおグローバルメモリを使用した方が、256KB転送時で最大約50.6%、4MB転送時で最大約27%処理性能値が向上している事も確認できた。また、pingoingパターンでの最小レイテンシは、MPI_Sendの0B転送について計測し、送受信バッファのローカル配置時で4.86マイクロ秒,
グローバル配置時で4.56マイクロ秒であった。MPI_Isendについても同様に計測し、送受信バッファのローカル配置時で5.12マイクロ秒, グローバル配置時で4.58マイクロ秒であった。
また、計算ノード間でのMPI_SendとMPI_Isendによるpingpong通信パターンでのスループットを図10に示す。グローバルメモリ使用時のMPI_Send、MPI_Isend共に最大スループットは64MB転送時で11.8GB/sが得られたが、ローカルメモリ使用時は64MB転送時で8.7GB/sに留まっている。ノード間クロスバネットワークの理論最大性能は12.3GB/sであることから、11.8GB/sの実効性能は約96%の効率を実現しており、十分高い実装であることが示された。この場合の最小レイテンシは、送受信バッファのグローバル配置時で8.56マイクロ秒であった。
図11に、1対1通信をシステム全体で行った場合の転送性能合計値を示す。これは、全プロセッサが、同時に隣のプロセッサにデータを送信した際の転送性能の合計値である。512ノードの際のシステムスループットは、5.8Tbyte/秒であり、12Gbyte/秒を512倍した値とほとんど遜色ない値が得られている。ほとんど同様の傾向なので、グラフは掲載しないが、MPI_PUTとMPI_GETの場合には、512ノード時のシステムスループットは、6.2Tbyte/秒であった。
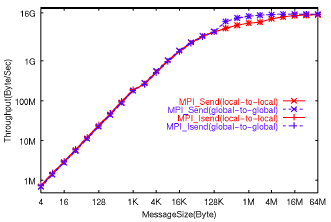 図9 Pingpong通信性能(ノード内) |
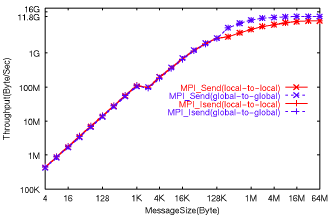 図10 Pingpong通信性能(ノード間) |
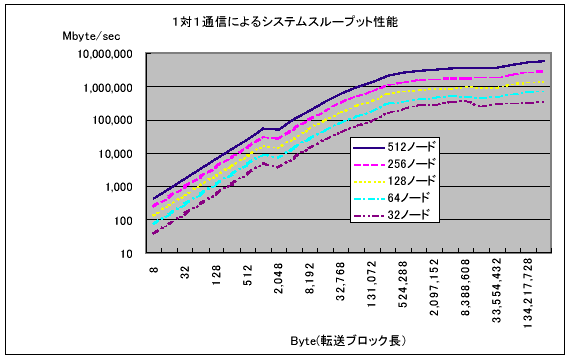
図11 1対1通信のシステムスループット
最後にMPI_Barrierの時間を図12に示す。ハードウェアの専用機能を用いているため、ノード数によらず約3.3μ秒前後という高速バリアが実現されている。
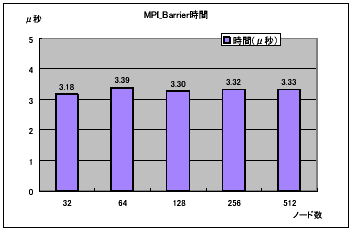
図12 ノード間バリア性能
(2)MPI-2関数に関する計測結果
地球シミュレータ上でMPI-2のRMA関数の性能測定を行った。MPIプロセス数を2とした時に、ランク0からランク1へのMPI_Get, MPI_Put,
MPI_Accumulate(reduction演算は総和演算)によるRMAデータ転送について、RMA関数起動からfence処理終了までの処理時間を計測した。なお送信バッファやRMAウィンドウ用の配列はグローバルメモリ上に割り付けた。
この性能測定結果として、MPI_GetとMPI_Put、およびMPI_Accumulate関数のスループットを図13に示す。MPI_GetおよびMPI_Putの最大スループットは64MB転送時に約11.63GB/sで、MPI_Accumulateは3.16GB/sであった。レイテンシは、4B転送時においてそれぞれ7.02マイクロ秒、6.63マイクロ秒、7.06マイクロ秒であった。
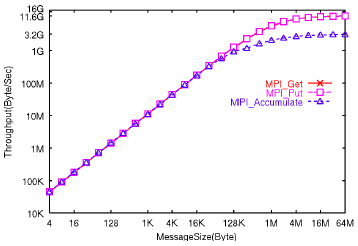
図13 ノード間のRMA関数の処理性能
5.6 地球シミュレータのHPF(High Performance Fortran)
地球シミュレータで実装されているHPFの機能を図14に示す。
機能としては、HPF/JA1.0拡張仕様[8]をベースとして、これに独自機能として、HALO/REDUCE HALOの非定型通信の高速処理機能、ベクトル化指示認識機能、自動並列化機能(Independent指示自動挿入機能)、並列I/O機能が付加されている。
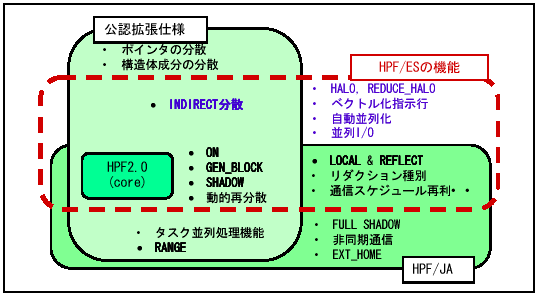
図14 地球シミュレータ用HPFの機能
HALOは、有限要素法や非定型の計算グリッドを用いたシミュレーションなどで現れる、連続ではない近傍参照エリアのことで、特定プロセッサから特定プロセッサへのデータ転送領域が非連続のため、高速通信には、データのパッキング処理が必要となる。HALOは、これらプロセッサ間通信が必要になるデータ参照エリアを明示的に指定する機能を言語として用意することにより、MPIで明示的に記述する並列処理と遜色ない性能をHPFで実現することができる[9]。
HPF並列I/Oは、ノードごとに独立して行うローカルディスクアクセスを用いて、HPF処理系が仮想的な並列ファイルを提供する仕組みである。図15にHPF並列I/Oの概念図を示す。配列Aが2次元目で分割され、4ノードに分散配置されているとする。このとき、HPF並列I/Oを用いて配列Aを書き出すと、それぞれのノードが保持している領域をそれぞれが独立(並列)に4つの別々のファイルに書き出す。ファイルには、配列Aのマッピング情報(どのように分散配置されているか)に続いて、データが書き出される。
性能的には、マッピング情報の管理とマッピング情報の出力のオーバヘッドが余分にかかるが、I/OのサイズがMB単位以上であれば、これらオーバヘッドは無視できる。
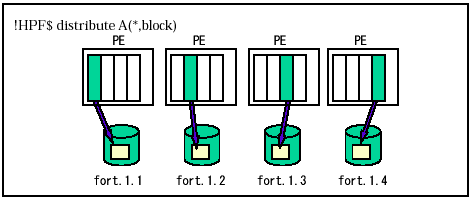
図15 HPF並列I/Oの動作例
ただし、ここで生成されたファイルはHPFからしかアクセスできない。また、ファイル生成時のプロセッサ(ノード)構成と読み込み時の構成が異なると、読み出しができないという問題がある。このため、分割数変更ツールが用意されている。本ツールを用いることにより、たとえば4ノード実行で生成されたHPF並列ファイルを8ノード実行用に変換し、8ノードで実行中のHPF並列プログラムから読み出すことが可能になる。また、逐次フォーマット(通常のUnixファイル)に変換することも可能である。
HPFを用いた並列化評価は、まだ実施途中であるが、APRベンチマーク、有限要素法プログラムの評価結果を図16に示す。左はAPRベンチマークのうち、shallow、scalgam、gridの3本について、1ノード2プロセッサ構成で2ノードから512ノード(1024プロセッサ)までの加速率を示している(横軸がプロセッサ数で縦軸が加速率)。問題規模が不十分のため、1024PEで性能劣化が見られるが、概ね良好な結果と言える。
図16右のグラフは、東大奥田研で開発された有限要素法カーネル[7]の評価結果である。系列1はHALO指定あり、系列2はHALO指定なしの場合である。1ノード1プロセッサを用い、1ノードから512ノードまで測定した。これも問題サイズが不十分で、128ノードで38倍の性能向上に留まっているが、HALO機能の効果を確認することができた。
この他に、まだ実験途中であるが、姫路工業大学の坂上さんの開発した、impact-3D[10 ]というTVD差分コードの大規模構成での評価を行っている。これまでの結果では、160ノード、1280プロセッサを用いて4Tflopsの実効性能を達成している。ピーク性能が10Tflopsであるので、40%の効率でHPFプログラムの走行が実現された。
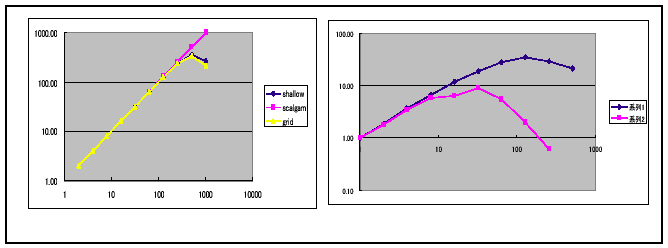
図16 HPFによる並列化評価結果
5.7 バッチデバッグツール
地球シミュレータは、巨大な計算パワーを可能な限り効率よく用いるために、バッチ処理が運用の基本となっている。仮に、インタラクティブ処理が可能であったとしても、数千プロセッサを用いる処理を、実行中に止めてデバッグすることは計算パワーの浪費という点で現実的ではない。これら大規模バッチジョブのデバッグのために開発されたツールがバッチデバッグツールである。
バッチデバッグの基本的な考え方は、実行時にログ情報を各ノードで別々に採取し、実行後にこれらログ情報をもとにデバッグを行うというものである。本ツールは、ログ情報の採取を簡便に、しかも効率良いものにするためのログ採取支援機能と、数百以上のファイルとして生成されたログ情報から有用な情報を得ることを支援するログファイルブラウザから構成される。
ログ採取支援機能は、Fortran90およびC/C++をベースにMPIで並列処理を記述したプログラムあるいはHPFから利用でき、ログ採取の指定は、指示行(pragma)形式で記述できるため、コンパイルオプションでログ採取のon/offを切り替えられる。また、トレースバック情報や、手続き遷移の情報、配列データの中身などを簡易な指示文で手軽に出力できる機能、これら出力の実行時のon/off制御機能(これは膨大になりがちなログ出力の制御に必須)などがサポートされている。
ログファイルブラウザは、lessライクなインタフェースで、プロセッサ(ノード)ごとに生成された(巨大かもしれない)ログを横断的に高速に検索したり、特定の条件でフィルタリングしたりする機能を有している。
6. 一様等方性乱流シミュレーション
地球シミュレータを利用して、ナビエ・ストークス方程式の大規模な直接数値シミュレーション(DNS)を計画している。乱流は、大小さまざまな渦が不規則に入り混じった極めて複雑な流体の運動であり、その解明にはスーパーコンピュータを用いなければ詳細な解析は不可能である。非圧縮性流体のDNSを現在のスーパーコンピュータで行おうとすると格子点数10243が限界であるが、地球シミュレータを用いればさら大きい格子点数のDNSが可能と考えられる。
我々は、地球シミュレータ開発と同時に、地球シミュレータで実行できるDNSのプログラムTrans7を開発してきた。ここでは、地球シミュレータ上でTrans7の実効性能の予備評価を行った結果を示す[6]。
6.1 並列化コードのテスト結果
Trans7の並列化では、スペクトル空間のフーリエ係数はkz方向、物理空間の変数はy方向に分割する領域分割法を用いた。この際必要なデータ転置は、3次元実FFTにおいてz方向に1次元FFTを適用する部分とy方向に1次元FFT
を適用する部分の間で行うこととし、MPIライブラリを用いてそれを実装した。
Trans7 による計算結果の妥当性を検証するために、Trans7を用いてN=512(格子点数5123)のDNSを行った。速度場の初期条件は、エネルギースペクトルE(k)=a
k4 exp{-b k2}に従う一様等方的なランダムな速度場で、周期境界条件を満足するように与えた。Δt = 0.001、動粘度ν=0.000763とし、十分乱流場が発達しエンストロフィー(渦度の2乗平均の1/2)が安定するt=10まで時間発展させた。乱流の統計的準定常状態を得るための外力fとして、低波数領域(|k|
< 2.5)に負の粘性を仮定し、その値は全エネルギーが一定に保たれるように各時間ステップで調整した。t=10でのテーラー長λに基づくレイノルズ数は、Rλ≒164であった。図17にt=10でのエネルギースペクトルを示す。この図から、波数領域4
< k < 16近傍において慣性小領域におけるコルモゴロフのエネルギースペクトルが確認された。
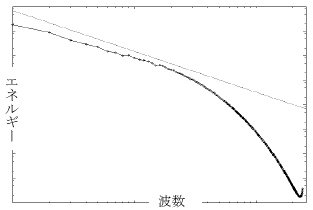
図17 エネルギースペクトル(格子点数5123)
6.2 地球シミュレータでの実効性能
Trans7 における時間発展ループの1ステップに対して、1台のPN上での実行時間を計測した。逐次版Trans7 において、格子点数5123、8APの場合の計算時間は約25秒であり、ハードウェアモニタによる実効性能で約27.8Gflop/sが得られた。これはピーク性能64Gflop/sのほぼ43%である。
また、MPIにより並列化したTrans7 に対し、格子点数(問題サイズNの3乗) を323、643、1283および2563、PN内のプロセッサ数を1、2、4、8と変化させた時の実行時間を計測した。格子点数2563、1APの時の実効性能は約3.72Gflop/sであり、ピーク性能の約47%
が得られた。地球シミュレータのベクトルプロセッサのベクトルレジスタ長は固定の256要素(8バイト長)、倍精度演算性能とデータ供給能力の比は2:1となっており、2基底FFTをベースとするTrans7
では、FFTのカーネルループの演算数とロード/ストア回数はほぼ1対1であることを考慮すれば、ピーク性能の約半分の性能が得られており、十分な性能である考えられる。8APでは約25Gflop/sを達成しているが、逐次プログラムの性能と比較すると若干低下している。これは並列化に伴うオーバーヘッドと考えている。
図18に、各問題サイズに対し、逐次実行時間に対する速度向上率を示す。N=32では、ベクトル処理の平均ループ長が32と短いため速度向上率が十分ではないが、それ以外は8APで7倍近い速度向上が得られ、ノード内並列処理においてほぼスケーラビリティを達成していると言える。
また、格子点数1283、2563、および5123のDNSに対して、地球シミュレータのPNを1台、2台、4台、および8台を用い、各PN内のプロセッサを一つとした時の時間発展ループ1ステップの実行時間を計測した。この並列実行では、PN内はマイクロタスクによる並列実行を用いた。
ノード間並列実行の速度向上率を図19に示す。速度向上率の計算では、単体PNでの逐次版の実行時間を基準にした。PN内並列処理の速度向上率より若干低い値が得られたが、8ノードで7倍近い値が得られた。PN間データ転送については、グローバルメモリを利用した実装ではなく、さらチューニングが必要と考えられる。
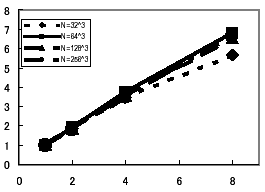 図18 ノード内の速度向上率 |
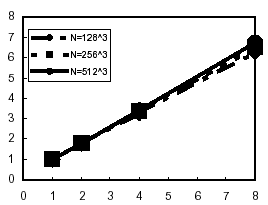 図19 ノード間の速度向上率 |
7. おわりに
地球シミュレータ計画は、地球変動研究を飛躍的に進展させるために、所謂ニーズ先行で、計算機ハードウェアの開発が開始された。5年間の開発により地球シミュレータは目標以上の実効性能を確認することが出来たが、まだ稼動して間もないシステムであり、本格的な評価や、実運用によりプロジェクトの真価が問われるのはまさしくこれからである。地球シミュレータはという5120プロセッサのとてつもない巨大システムは、フルに使いこなすのも大変だが、いともたやすくテラフロップスオーダの性能が出るというモンスターマシンである。大規模な数値シミュレーションによりどのような結果が得られるか楽しみである。また、日本はソフトウェア開発能力が低いと云われる中で、世界一のハードウェアを持ったことがソフトウェア開発に対しどのように影響するかについても興味深い。
最後になってしまったが、完成を間近にひかえた平成13年11月17日、地球シミュレータの構想から開発までを先導してきた三好甫氏が亡くなられた。地球シミュレータ完成を見ずに他界されたことはさぞご無念であったことと思われる。我々は氏の遺志を引き継ぎ、世界に冠たる日本のHPC技術を受け継いでいくことが重要であると思う。今後、「地球シミュレーション」により地球科学の発展に寄与することを願ってやまない。
参考文献
| [1] | 谷啓二,地球シミュレータ計画のバックグランドとその位置付け,RIST News (2000). |
| [2] | 横川三津夫,谷啓二,地球シミュレータ計画,情報処理,Vol.41,No.4,pp.369-374 (2000). |
| [3] | M. Yokokawa, et al., Performance Estimation of the Earth Simulator, Proceedings of the ECMWF Workshop, November (1998). |
| [4] | M. Yokokawa, et al., Basic Design of the Earth Simulator, High Performance Computing, LNCS 1615, Springer, pp.269-280 (1999). |
| [5] | 上原,田村,横川,地球シミュレータの計算ノード上でのMPI性能評価,HPCS2002,73-80 (2002). |
| [6] | 横川,斉藤,石原,金田,地球シミュレータ上の一様等方性乱流シミュレーション,HPCS2002,125-131 (2002). |
| [7] | Hiroshi Okuda and Norihisa Anan, Optimization of Element-by-Element FEM in HPF 1.1, Concurrency and Computation: Practice and Experience, Wiley & Sons Ltd., (to appear in Spring 2002) |
| [8] | Japan Association of High Performance Fortran, 1999, HPF/JA Language Specification Version 1.0, RIST (English version is available at http://www.tokyo.rist.or.jp/jahpf/index-e.html). |
| [9] | Siegfried Benkner, Erwin Laure, and Hans Zima. 1999. HPF+: An Extension of HPF for Advanced Industrial Applications. Technical Report TR 99-1, Institute for Software Technology and Parallel Systems, University of Vienna. |
| [10] |
H. Sakagami and T. Mizuno, Compatibility Comparison and Performance Evaluation for Japanese HPF Compilers using Scientific Applications, Concurrency and Computation: Practice and Experience, Wiley & Sons Ltd., (to appear in Spring 2002). |
<付録1> 実機を用いた気象シミュレーション例(大気大循環モデル)
<付録2> 海洋大循環モデルの計算例