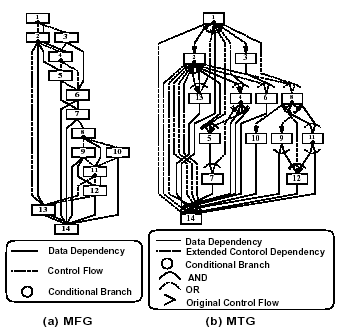
図1: マクロフローグラフ(MFG)とマクロタスクグラフ(MTG)の例
第3章 ハイエンドコンピューティング研究開発の動向
3.3.2 自動並列化コンパイラによるSPM上での粗粒度タスク並列処理笠原 博徳 委員
1. はじめに
現在、SMPアーキテクチャはシングルチップマルチプロセッサからワークステーション、各種サーバマシンまで多くのシステムで採用されている。このようなSMPマシン上では従来よりループレベル並列処理技術が用いられ、様々なプログラムリストラクチャリング技術を用いたループ並列化コンパイラが開発されてきた。例えば、Polarisコンパイラ[1,2]は、サブルーチンのインライン展開、シンボリック伝搬、アレイプライベタイゼーション[3,1]、実行時データ依存解析[2]によってループ並列性を抽出する。また、SUIFコンパイラ[4,5,6]は、インタープロシージャ解析、ユニモジュラ変換、アフィンパーティショニングを用いたループ内とループ間のデータローカリティ[7,8,9]に関する最適化などを用いてループを並列処理する。
これらをはじめとする優れたループ並列化コンパイラにより、様々なプログラムの解析・評価が行われてきたが、ループレベル並列性抽出技術は既に成熟期にあり、今後の画期的な性能向上は見込めないと言われている。したがって、今後の並列処理の性能向上のためには、これまでの並列化コンパイラでは抽出できなかった粗粒度並列性の利用が重要となる。
粗粒度並列性を利用するコンパイラとしては、NANOS コンパイラ[10,11]とPROMIS コンパイラ[12,13]、そしてOSCARマルチグレイン並列化コンパイラが挙げられる。NANOSコンパイラでは、階層並列化実現のための拡張OpenMP
API[14,15,16]を用いて、粗粒度並列性を含むマルチレベル並列性を抽出しようとしている。また、PROMISコンパイラは、HTGとシンボリック解析[17]を用いるParafrase2コンパイラ[18]をベースとして、実用レベルのコンパイラを開発する努力が行われている。
筆者らが開発中のOSCAR FORTRANマルチグレイン並列化コンパイラ[19,20]は、ループ並列化に加え、ループ・サブルーチン・基本ブロック間の並列性を利用するマルチグレイン並列処理[21,19,20]を実現し、OpenMPを用いたワンタイムシングルレベルスレッド生成手法[22]によって、NANOSコンパイラのような言語拡張を行うこと無く、低オーバヘッドでの粗粒度並列処理を可能としている。さらにSMPマシンで問題となる大きな共有メモリアクセスオーバヘッドを軽減するため、粗粒度タスク間共有データをキャッシュメモリ上で授受できるようにするデータローカライゼーション手法[23]の開発も行っている。
本報告では、このOSCARマルチグレイン並列化コンパイラを用いて、SPEC95FPベンチマークの101.tomcatv、102.swim、107.mgrid、103.su2cor、Perfect
ClubベンチマークのARC2Dについて、SMPサーバIBM RS6000、SMPワークステーションSUN Ultra80の2機種のマシン上で粗粒度タスク並列処理性能の評価を行った結果について述べる。
2. 粗粒度タスク並列処理
ここでは、逐次プログラムを粗粒度タスクに分割し粗粒度タスク間並列性解析を行う手法、及び並列性抽出後のOpenMPを用いた粗粒度並列化プログラム生成法について述べる。
粗粒度タスク並列処理とは、プログラムを基本ブロック、あるいはその融合ブロック(BPA)、繰返しブロック(RB)、サブルーチンブロック(SB)の3種類のマクロタスク(MT)に分割し、そのMTをプロセッサエレメント(PE)や複数PEをグループ化したプロセッサクラスタ(PC)に割り当てて実行することにより、MT間の並列性を利用する方式である。
OSCARマルチグレイン並列化コンパイラにおける粗粒度並列処理の手順は次のようになる。
| 1) | 逐次プログラムのMTへの分割 |
| 2) | MT間の制御フロー、データ依存解析によるマクロフローグラフ(MFG)の生成 |
| 3) | 最早実行可能条件解析によるマクロタスクグラフ(MTG)の生成[24,21] |
| 4) | MTGがデータ依存エッジのみで構成される場合は、スタティックスケジューリングによるMTのPCまたはPEへの割り当て。 MTGがデータ依存エッジと制御依存エッジを持つ場合は、コンパイラによるダイナミックスケジューリングルーチンの自動生成 |
| 5) | OpenMPによる粗粒度並列化プログラム生成 |
以下、各ステップの概略を示す。
2.1 粗粒度タスク生成
粗粒度タスク並列処理では、ソースプログラムは、基本ブロック、あるいはその融合ブロック(BPA)、繰返しブロック(RB)、サブルーチンブロック(SB)の3種類のマクロタスク(MT)に分割される。生成されたRBが並列化可能ループ、すなわちDoallループの場合は、
PC数やキャッシュサイズを考慮した数の粗粒度タスクにループを分割し、それぞれ異なった粗粒度タスクとして定義する。また、ループ並列化不可能で実行時間の長いRBやインライン展開を効果的に適用できないSBに対しては、そのボディ部を階層的に粗粒度タスクに分割し並列処理を行う。
2.2 粗粒度並列性抽出
次に、各階層(ネストレベル)において、生成されたMT間のデータ依存と制御フローを解析する。解析結果は、図1(a)に示すようなマクロフローグラフ(MFG)として表される。図中、ノードはMTを表し、実線エッジはデータ依存、点線エッジは制御フローを表す。また、ノード内の小円は条件分岐を表す。図中のエッジの矢印は省略されているが、エッジの向きは下向きを仮定している。
MFG生成後、MT間の並列性を抽出するために、データ依存と制御依存を考慮し、各MTの最早実行可能条件を解析する。最早実行可能条件とは、各MTが最も早い時点で実行可能になる条件を表し、例えば、図1(a)におけるMT6の最早実行可能条件は、MT3が終了するかMT2がMT4に分岐、となる。各MTの最早実行可能条件は、図1(b)に示すようなマクロタスクグラフ(MTG)として表される。
MTGにおいても、ノードはMTを、ノード内の小円は条件分岐を表す。また、実線エッジはデータ依存を表し、点線エッジは拡張された制御依存を表す。ただし、拡張された制御依存とは、通常の制御依存だけでなく、MTiのデータ依存先行MTが実行されない条件も含むものである。図1(b)中のエッジを束ねる実線アークは、アークによって束ねられたエッジがAND関係にあることを示し、点線アークはOR関係にあることを表す。MTGにおいても、エッジの矢印は省略されているが、下向きを仮定している。また、矢印のあるエッジはオリジナルの制御フローを表している。
図1: マクロフローグラフ(MFG)とマクロタスクグラフ(MTG)の例
2.3 OpenMPを用いたSMP用粗粒度タスク並列化コード生成
メSECTIONSモによってプログラムの実行開始時に一度だけ並列スレッドを生成するワンタイムシングルレベルスレッド生成手法[22]を用いる。OSCARコンパイラによって生成された粗粒度タスクは、ダイナミックスケジューリング、あるいはスタティックスケジューリングを用いて、PEに対応するスレッド、あるいはPCに対応するスレッドグループに割り当てられる。スレッドグループとは、MTの割り当て単位として、任意の数のスレッドをプログラム的にグループ化したものである。MTG内に条件分岐のような実行時不確定性が存在する場合はダイナミックスケジューリングが適用され、MTは実行時にスレッドグループもしくはスレッドに割り当てられる。ダイナミックスケジューリングルーチンは、OSコールによるスレッドスケジューリングオーバへッドを避けるために、コンパイラによって各プログラムに合わせて生成され、出力される並列化プログラム内に埋め込まれる。一方、MTGがデータ依存のみで構成される場合には、コンパイル時にスタティックスケジューリングを適用し、実行時スケジューリングオーバヘッドの最小化を図っている。
階層的なMTGが生成されている場合は階層的粗粒度並列処理を行うが、一般的に、階層的並列処理は、上位スレッドが子スレッドを生成することによって実現される。しかし、本研究で用いるOSCAR
FORTRANコンパイラでは、メPARALLEL SECTIONSモ メEND PARALLEL SECTIONSモディレクティブ間のメSECTIONモディレクティブ間に、生成される全MTG階層での処理やダイナミックスケジューリングを適用する全MTG階層のスケジューリングルーチンを記述することによって、シングルレベルスレッド生成のみで階層的並列処理を実現する。これにより、スレッドのfork/joinオーバヘッドの最小化、及び既存の言語仕様のみで階層的粗粒度並列処理を実現することができる。
また、スタティックスケジューリング、ダイナミックスケジューリングにおいて、MT間でキャッシュメモリを用いて共有データを受け渡すためのデータローカライゼーション手法[23]を適用することも可能である。データローカライゼーションを適用する際は、各MTの使用データ量がキャッシュサイズ以内に収まるように粗粒度タスク分割し、同一データ領域を使用するMTができるだけ同一プロセッサ上で連続実行されるようにスケジューリングを行う。
3. SMP上での性能評価
ここでは、OSCARマルチグレイン並列化Fortranコンパイラを用いて、SPEC95ベンチマークのtomcatv、swim、mgrid、su2cor、Perfect
ClubベンチマークのARC2Dプログラムを粗粒度タスク並列化し、IBM RS6000 SP 604e High Node、SUN Ultra80上で性能評価を行った結果を述べる。
3.1 OSCAR FORTRAN Compiler
マルチグレイン並列化コンパイラメOSCAR FORTRANコンパイラモは、フロントエンド・ミドルパス・バックエンドから構成される。本研究では、OpenMPディレクティブを含む並列化Fortranソースコードを自動的に生成するOpenMPバックエンドを用いる。すなわち、OSCARコンパイラは逐次FortranをOpenMP
Fortranに変換するプリプロセッサとして利用される。
3.2 RS6000上での評価
ここでは、RS6000上での粗粒度並列処理結果について述べる。
評価に用いたRS6000 SP 604e High Nodeは、200MHzのPowerPC 604eを8プロセッサ搭載したSMPサーバである。1プロセッサあたり、32KBずつのL1命令、データキャッシュと、1MBのユニファイドL2キャッシュを持ち、共有主メモリは1GBである。使用したコンパイラはXL
Fortran Compiler Version 7であり、OSCARコンパイラの出力をコンパイルする際のオプションは、メ-O3 -qsmp=noauto
-qhot -qarch=ppc -qtune=auto -qcache=autoモである。XL Fortran Ver.7単独での評価においては、逐次性能評価でのオプションとしてメ-O5
-qhot -qarch=ppc -qtune=auto -qcache=autoモを用い、自動並列化ではメ-O5 -qsmp=auto -qhot -qarch=ppc
-qtune=auto -qcache=autoモを用いた。
図2にtomcatv、swim、mgrid、su2cor、arc2dの評価結果を示す。横軸はプログラム名を示し、プログラム名の下の数字はオリジナルプログラムをXL
Fortranで逐次処理コンパイルした際の実行時間を表す。縦軸は、XL Fortran Ver.7での逐次処理時間を1.00とした場合の速度向上率を示す。各プログラムについては、図中左からオリジナルソースプログラムをXL
Fortranによって自動並列化した際の8スレッドでの性能、XL Fortranによる自動並列化において8スレッドまで用いて並列化を行った場合の最高性能が得られたスレッド数とその性能、OSCARコンパイラのOpenMP出力をXL
Fortranでコンパイルした際に最高性能を与えたスレッド数とその際の性能を表している。また、棒グラフ上部の数字はそれぞれの並列処理時間である。
図2中、tomcatvでは、XL Fortranによる自動並列化においては3スレッドで最高性能が得られ、1.7倍の速度向上となったのに対して、OSCARコンパイラは8スレッドで5.7倍の速度向上が得られた。
swimでは、逐次処理に対するXL Fortranは6スレッドで4.2倍だが、OSCARコンパイラの性能は8スレッドで8.3倍となった。またmgridにおいては、XL
Fortranでは4スレッドで3倍の速度向上であったが、OSCARコンパイラでは8スレッド時で6.8倍の最高性能が得られた。tomcatv、swim、mgridでは、スタティックスケジューリングを用いて粗粒度並列処理を行っている。これらのアプリケーションはループ並列性が大きいため、XL
FortranもOSCARコンパイラもループ並列性を利用しているが、OSCARコンパイラのスレッド数に対するリニアな性能向上に対して、XL Fortranではスレッド数の増加に対してスケーラブルな性能向上が見られない。この差の理由として、timeコマンドによる計測結果におけるSystem
timeの差が使用スレッド数が増えるにつれて非常に大きくなることが挙げられる。例として、表1に、tomcatvとswimにおける各スレッド数ごとのSystem
timeを示す。表1のtomcatvでは、XL Fortranの自動並列化で最高性能を示す3スレッドでのSystem timeが110秒であるのに対して、OSCARコンパイラでは最高性能が得られる8スレッドで3.1秒であり、差が非常に大きい。また、RS6000上で各スレッドやプロセスの処理時間などを計測できるPPROFコマンドの出力結果より、XL
Fortranによる自動並列化の際の各スレッドでの処理時間は、マスタースレッドの処理時間とスレーブスレッドでの処理時間に非常に大きな差が出ることを確認しており、負荷の不均衡が生じている。
一方、図2におけるsu2cor、arc2dは、分散ダイナミックスケジューリングによる粗粒度並列処理を行った結果である。ただし、OSCARコンパイラによる評価では、su2corではインライン展開、配列リネーミング、arc2dではインライン展開、ループアンローリングをオリジナルの逐次プログラムに対して適用したプログラムを逐次プログラムとしてOSCARコンパイラに入力した。これは、研究用コンパイラであるOSCARコンパイラは既存のコンパイラで行われていない機能の実現・実装に主眼を置いているため、多くの市販コンパイラで実現されているリストラクチャリング技術のいくつかは未実装、あるいはデバッグ作業を遅らせているため、今回の評価では手動でリストラクチャリングを行った後、OSCARコンパイラを用いた粗粒度並列化を行った。
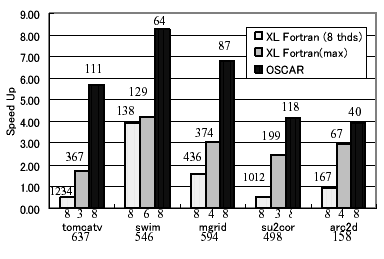
図2: RS6000上での評価
逐次処理に対するXL Fortranによる自動並列化での最高性能は、su2corでは2.5倍、arc2dでは3.0倍の速度向上であったが、OSCARコンパイラにおける最高性能は、su2corでは8スレッドで4.2倍、arc2dでは8スレッドで3.9倍となった。su2cor、arc2dにおいては、OSCARコンパイラによる評価では、分散ダイナミックスケジューリングを適用することによって、図2に示すような性能が得られたのに対して、XL
Fortranの性能はtomcatv、swim、mgridと同様、OSCARコンパイラよりも低い性能を示している。また、使用スレッド数と性能で比較した場合、OSCARコンパイラでは全てにおいて8スレッドを用いた場合が最高性能を示すが、
XL Fortranでの8スレッド使用時の性能は、swimとmgridを除いて、逐次処理よりも性能が低下している。
したがって、XL FortranではOSおよびOpenMPランタイムルーチンによるスレッドスケジューリングを含めたスレッド管理のためのオーバヘッドが大きいため、性能が向上しにくいことがわかった。同時に、OSCARコンパイラでのワンタイムシングルレベルスレッド生成手法を用いた粗粒度並列処理手法は、このスレッド管理オーバヘッドを低く抑えられるため、有効であることが確認された。
3.3 Ultra80上での評価
次に、OpenMPを用いた粗粒度並列処理手法のポータビリティを示すため、tomcatv、swimのUltra80上での粗粒度並列処理結果について述べる。
本研究で用いたSUN Ultra80は、450MHzのUltra SPARCIIを4つ搭載しており、 1プロセッサあたり、16KBずつのL1命令、データキャッシュと4MBのユニファイドL2キャッシュを持ち、共有主メモリは1GBである。使用したネイティブコンパイラはForte
Developer 6 Update 1であり、OSCARコンパイラの出力した粗粒度並列化Fortranをコンパイルする際のオプションはメ-fast -mp=openmp
-explicitpar ミstackvarモである。Forte自体の性能評価においては、逐次処理ではメ-fastモ、自動並列化ではメ-fast -parallel
-reduction ミstackvarモを用いた。Ultra80はRS6000と比較して共有メモリアクセスオーバヘッドが非常に大きいため、今回のtomcatvの評価においてはローカライゼーション手法を適用した。その際、前述のようにOSCARコンパイラの未実装部分、およびバグを避けるため、ループ終値変数の定数化、収束ループ内のループインターチェンジ、配列の次元入れ替えといったリストラクチャリングを手動で行った。今回は、Forteによる逐次処理、自動並列化、OSCARコンパイラによる評価全てに対してこれらの改変後のプログラムを用いた。また、swimについても、サブルーチンのインライン展開とクローニング、ループ終値変数の定数化を行い、tomcatv同様の評価を行った。これらの変換についても、RS6000での評価と同様に、既存のコンパイラによって実現されている変換技術であり、現在OSCARコンパイラへ組み込み中である。
図3、4にUltar80上でのtomcatv、swimの評価結果をそれぞれ示す。グラフの横軸は使用スレッド数、縦軸はForteによる逐次処理時間を1.00とした速度向上率を表し、メOSCAR(Localize)
モはOSCARコンパイラによるローカライゼーション手法、メOSCAR(Loop) モはOSCARコンパイラでループ並列性のみの利用、そしてメForteモはForte
6による自動並列化の結果を表す。また、各プロット横の数字は実行時間(単位は秒)を表す。
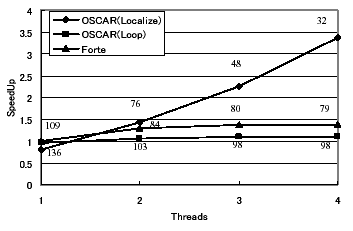
図3: Ultra80上でのtomcatvの評価結果
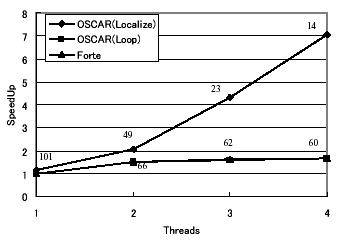
図4: Ultra80上でのswimの評価結果
tomcatv、swimともに、OSCARコンパイラによるデータローカライゼーション手法を適用した結果は優れた性能を示している。Forteによる自動並列化では性能はほとんど向上しないが、OSCARコンパイラの評価においては、tomcatvでは、ローカライゼーションの適用により4スレッドで3.4倍の速度向上が得られた。swimでは、4スレッドで7.1倍の速度向上を達成している。
図3の1スレッド部分を見ると、OSCARコンパイラによってローカライゼーション手法を適用した結果はForteによる逐次処理の性能よりも低い性能を示しているが、スレッド数が増えるにつれて高効率を示す。この結果は、Forteではオリジナルソースプログラムに対するキャッシュタイリング技術を中心とした逐次処理最適化は非常に強力だが、ローカライゼーション手法を適用したOSCARコンパイラによる逐次処理用出力への最適化には向かないことを示している。また図3、4より、並列処理時におけるOSCARコンパイラでのループ並列性利用結果は、Forteの性能とほぼ同等かそれよりも若干低下していることが分かる。この結果は、Ultra80ではキャッシュミスヒットした際の主メモリへのアクセスが非常に高コストであるため、OSCARコンパイラによるデータローカライゼーション手法が有効であることを示している。
4. まとめ
本報告では、SPEC95FPベンチマーク、Perfect Clubベンチマークから、 101.tomcatv、102.swim、103.su2cor、107.mgrid、ARC2Dについて、
SMPサーバIBM RS6000 SP 604e High NodeとSMPワークステーションSUN Ultra80上での粗粒度タスク並列処理について述べた。これらのマシン上での性能評価の結果、RS6000、Ultra80用のネイティブコンパイラXL
Fortran Version 7、 Forte Developer 6 Update 1の自動ループ並列化性能を 60%から430%上回る性能を得られることが確かめられた。この評価より、筆者等が開発した粗粒度タスク並列処理スレッド生成手法であるワンタイムシングルレベルスレッド生成手法、およびキャッシュ最適化のためのデータローカライゼーション手法が、スレッド管理オーバヘッド、共有メモリアクセスオーバヘッドを軽減し、SMP上で効果的な並列処理を実現するために有効であることが確認された。
なお本研究の一部は、経済産業省/NEDOミレニアムプロジェクト IT21 メアドバンスト並列化コンパイラモにより行われたものである。
参考文献
| [1] | Eigenmann, R., Hoeflinger, J. and Padua, D.: On the Automatic Parallelization of the Perfect Benchmarks, IEEE Trans. on parallel and distributed systems, Vol. 9, No. 1 (1998). |
| [2] | Rauchwerger, L., Amato, N. M. and Padua, D. A.: Run-Time Methods for Parallelizing Partially Parallel Loops, Proceedings of the 9th ACM International Conference on Supercomputing, Barcelona, Spain, pp. 137-146 (1995). |
| [3] | Tu, P. and Padua, D.: Automatic Array Privatization, Proc. 6th Annual Workshop on Languages and Compilers for Parallel Computing (1993). |
| [4] | Hall, M. W., Murphy, B. R., Amarasinghe, S. P., Liao, S., and Lam, M. S.: Interprocedural Parallelization Analysis: A Case Study, Proceedings of the 8th International Workshop on Languages and Compilers for Parallel Computing (LCPC95) (1995). |
| [5] | Hall, M. W., Anderson, J. M., Amarasinghe, S. P., Murphy, B. R., Liao, S.-W., Bugnion, E. and Lam, M. S.: Maximizing Multiprocessor Performance with the SUIF Compiler, IEEE Computer (1996). |
| [6] | Amarasinghe, S., Anderson, J., Lam, M. and Tseng, C.: The SUIF Compiler for Scalable Parallel Machines, Proc. of the 7th SIAM conference on parallel processing for scientific computing (1995). |
| [7] | Lam, M. S.: Locallity Optimizations for Parallel Machines, Third Joint International Conference on Vector and Parallel Processing (1994). |
| [8] | Anderson, J. M., Amarasinghe, S. P. and Lam, M. S.: Data and Computation Transformations for Multiprocessors, Proceedings of the Fifth ACM SIGPLAN Symposium on Principles and Practice of Parallel Processing (1995). |
| [9] | Lim, A. W. and Lam., M. S.: Cache Optimizations With Affine Partitioning, Proceedings of the Tenth SIAM Conference on Parallel Processing for Scientific Computing (2001). |
| [10] | Martorell, X., Ayguade, E., Navarro, N., Corbalan, J., Gozalez, M. and Labarta, J.: Thread Fork/Join Techniques for Multi-level Parllelism Exploitation in NUMA Multiprocessors, ICS'99 Rhodes Greece (1999). |
| [11] | Ayguade, E., Martorell, X., Labarta, J., Gonzalez, M. and Navarro, N.: Exploiting Multiple Levels of Parallelism in OpenMP: A Case Study, ICPP'99 (1999). |
| [12] | PROMIS: http://www.csrd.uiuc.edu/promis/. |
| [13] | Brownhill, C. J., Nicolau, A., Novack, S. and Polychronopoulos, C. D.: Achieving Multi-level Parallelization, Proc. of ISHPC'97 (1997). |
| [14] | : OpenMP: Simple, Portable, Scalable SMP Programming http://www.openmp.org/. |
| [15] | Dagum, L. and Menon, R.: OpenMP: An Industry Standard API for Shared Memory Programming, IEEE Computational Science & Engineering (1998). |
| [16] | Ayguade, E., Gonzalez, M., Labarta, J., Martorell, X., Navarro, N. and Oliver, J.: NanosCompiler: A Research Platform for OpenMP Extensions, Proc. of the 1st Europian Workshop on OpenMP (1999). |
| [17] | Haghighat, M. R. and Polychronopoulos, C. D.: Symbolic Analysis for Parallelizing Compliers, Kluwer Academic Publishers (1995). |
| [18] | Parafrase2: http: //www.csrd.uiuc.edu/parafrase2. |
| [19] | 岡本雅巳, 合田憲人, 宮沢稔, 本多弘樹, 笠原博徳: OSCARマルチグレインコンパイラにおける階層型マクロデータフロー処理手法, 情報処理学会論文誌, Vol. 35, No. 4, pp. 513-521 (1994). |
| [20] | Kasahara, H., Okamoto, M., Yoshida, A., Ogata, W., Kimura, K., Matsui, G., Matsuzaki, H. and H.Honda: OSCAR Multi-grain Architecture and Its Evaluation, Proc. International Workshop on Innovative Architecture for Future Generation High-Performance Processors and Systems (1997). |
| [21] | Kasahara, H. et al.: A Multi-grain Parallelizing Compilation Scheme on OSCAR, Proc. 4th Workshop on Languages and Compilers for Parallel Computing (1991). |
| [22] | 笠原博徳, 小幡元樹, 石坂一久: 共有メモリマルチプロセッサシステム上での粗粒度タスク並列処理, 情報処理学会論文誌, Vol. 42, No. 4 (2001). |
| [23] | 吉田明正, 越塚健一, 岡本雅巳, 笠原博徳: 階層型粗粒度並列処理における同一階層内ループ間データローカライゼーション手法, 情報処理学会論文誌, Vol. 40, No. 5 (1999). |
| [24] | 本多弘樹, 岩田雅彦, 笠原博徳: Fortranプログラム粗粒度タスク間の並列性検出手法, 電子情報通信学会論文誌, Vol. J73-D-1, No. 12, pp. 951-960 (1990). |