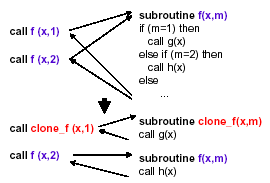
図1:手続き間定数伝播の適用例
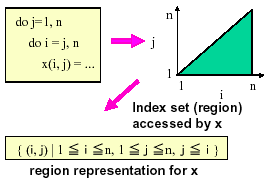
図2:連立1次不等式表現の例
第3章 ハイエンドコンピューティング研究開発の動向
3.3.1 手続き間解析の動向 〜コンパイラとその周辺〜
佐藤 真琴 委員
1. はじめに
手続き間解析とは、手続き(関数、サブルーチン)の解析情報を、その手続きの呼び出し点で利用できるようにするコンパイル技術のことである。これによってプログラムの解析精度が向上し、プログラムを最適化する機会が増加することが期待できる。広い意味では、インライン展開も手続き間解析の一つと考えられるが、リカーシブな呼び出しに対応できないなど、適用範囲が狭い点が課題である。これに対して、狭義の手続き間解析はその一般性から、FortranのみならずC++やJavaに対する最適化コンパイラでも徐々に採用されつつあるなど、広がりをみせている。
本稿では、Fortranコンパイラにおける手続き間解析、及び、ツールにおける手続き間解析の利用に関する動向を、具体的な事例を通して紹介する。
2. 手続き間自動並列化コンパイラWPP
我々は、手続き間自動並列化コンパイラWPP(Whole Program Parallelizer)[1][2][4]を開発している。これは、逐次Fortranプログラムを入力し、手続き間解析・並列化およびループ変換を施し、その結果をOpenMP[18]プログラムとして生成する。本章ではWPPの手続き間解析・並列化について述べる。
2.1 構成
WPPは以下の4フェーズから構成される。
(1)手続き間フレームワーク
(2)手続き間スカラ解析
(3)手続き間配列解析
(4)手続き間並列化
(1)は全体制御、コールグラフを含む階層的制御フローサマリグラフ(Control Flow Summary。以下、CFSグラフと呼ぶ。)やクローン手続きの作成と管理等を行なう。(2)はスカラ変数に対する手続き間データフロー解析、手続きクローニング、及び手続き間定数伝播を行なう。(3)は配列に対する手続き間データ依存解析を行なう。(4)は上記解析結果およびリダクションなどの独自解析の結果から、手続き呼び出しを含むループを並列化する。
(2)と(3)を別々に、しかも、(2)を先に行なうのは、手続き間定数伝播により配列添字やループの上下限値が定数化した場合、配列解析の精度向上が期待できるためである。
(2)から(4)までの3つのフェーズの各々は、さらに以下の3つの小フェーズに分かれる。これらの小フェーズ構成により手続き間解析が実現できる。
(A)手続き内前解析
(B)手続き間伝播
(C)手続き内後解析
(A)は、各手続きを解析し、必要なら解析結果を要約してテーブルに保持する。この時は、各手続きの中間語はメモリ上に存在し、それを用いて解析を行なう。この時点では手続き呼び出し先の解析情報がないので、手続き呼び出し点に対する解析結果は一般に、未定等の扱いとなる。但し、(A)をコールグラフを逆DFN順にたどって実施すれば、ボトムアップに得られる解析情報に関しては手続き呼び出し点でその解析結果が利用可能となる。
(B)は、コールグラフやCFSグラフをたどりながら、(A)で得られたテーブルのマージ等を行ないながら、各手続きとそこから呼び出される全ての手続き呼び出しの効果を総合した解析情報等を得る。この解析では、各手続きの中間語等は用いず、上記2つのグラフと(A)で得られたテーブルを使って処理を行なう。これにより、(A)と(C)では従来のコンパイラにおける中間語を処理するためのインターフェースを変えずに、(B)ではメモリ消費量を少なくして手続き間解析が実現できる。
(C)は、(B)によって得られた各手続きの解析結果を手続き呼び出し点での解析結果に翻訳し、この翻訳結果と各手続きの中間語等を使って、呼び出し先手続きにおける効果を考慮した解析を行なう。
以上の3つの小フェーズでの解析方法は、解析内容によって多少の違いがある。注意すべきなのは、従来のコンパイラにおける解析方法は以上の3つに分割にする必要があるため、その解析アルゴリズムはかなり変更される、という点である。例えば、全ての手続きに対する中間語が同時に存在することを前提とした解析アルゴリズムは使えない。
2.2 手続き間フレームワーク
手続き間フレームワークは、手続き間解析全体の処理の制御、コールグラフを含むCFSグラフやクローン手続きの作成と管理等を行なう。
コールグラフとは、手続きをノード、呼び出す手続きと呼び出される手続きに対応するノード同士を有向エッジで接続した有向グラフである。我々の方法では、1つの手続きを表わすノードはコールグラフ上でただ1つである。リカーシブな呼び出しがある場合は、コールグラフ中にループができる。
CFSグラフとは、ループ、基本ブロック、手続き呼び出し点を1つのノードとする制御フローグラフでである。ループボディはそのループノードを親ノードとする下層のサブグラフとなる。したがって、n重ループは(n+1)階層のグラフとなる。このCFSグラフをコールグラフと接続することによって、手続き全体のデータフロー解析が可能となる。
手続きクローニングでは、ある手続きの情報をコピーしてクローン手続きを作成する。その際、コールグラフにおいてクローン手続きに対応するノードの追加や、対応するCFSグラフの作成、及びコールグラフとの接続が必要となる。
2.3 手続き間スカラ変数解析
手続き間スカラ変数解析はスカラ変数に対する手続き間データフロー解析を行ない、各手続きに対して参照集合を決定する。各集合は、各手続きにおける変数の定義・使用情報を要約したものである(表1)。これらの集合うち、最初の2つは制御フローに関係しない情報(flow-insensitive)であり、 後の3つは制御フローに関係する(flow-sensitive)情報である。
手続き間スカラ変数解析はまた、手続きクローニングと手続き間定数伝播も行なう。1つの手続きに対する異なる呼び出し点で、同じ引数に異なる定数値が伝播された場合、このままでは呼び出し先手続きに各々の定数値を伝播できない。これを可能にするために、手続きクローニングを適用する。これによって、上記の場合でも呼び出し先手続きに定数伝播ができる。この結果、次に行なう手続き間配列解析の精度向上が見込める。図1はこの最適化の適用例である。手続きfに手続きクローニングが適用され、その手続きの引数mに定数伝播が適用される。
| 参照集合 | 意味 |
| MOD | 定義の可能性のある変数 |
| USE | 使用の可能性のある変数 |
| KILL | 確実に定義される変数 |
| EUSE | 定義前に使用の可能性の有る変数 |
| LIVE | ループや手続きの最後でライブな変数 |
2.4 手続き間配列解析
手続き間配列解析は配列に対して参照リージョンと呼ばれる集合を解析して、手続き間データ依存解析を行なう。ここで、ある配列に対する参照リージョンとは、あるプログラム単位内でのその配列の参照情報を要約した配列添字の集合である(表2)。
図1:手続き間定数伝播の適用例 |
図2:連立1次不等式表現の例 |
| 参照リージョン | 意味 |
| MODA | 定義の可能性のある添字範囲 |
| USEA | 使用の可能性のある添字範囲 |
| KILLA | 確実に定義される添字範囲 |
| EUSEA | 定義前に使用の可能性のある添字範囲 |
| LIVEA | ループや手続きの最後でライブな添字範囲 |
参照リージョンのコンパイラ内部表現には矩形表現と連立1次不等式表現を用いている。矩形表現は各次元毎の区間表現の直積である。連立1次不等式表現は各次元の添字の1次結合から成る連立不等式である。添字が単純な場合は矩形表現を用いて高速に処理を行ない、添字が複雑な場合は連立1次不等式表現を用い、その計算にはオメガテスト[19]と同様な手法を用いる。後者はストライドが2以上の場合や三角ループにおける多次元配列の参照領域を表現でき、また、実引数と仮引数の配列次元が異なる場合にも対応可能である。図2は三角ループの例である。プログラム中に異なる参照パターンが多く出現する場合、参照リージョンは各々のパターンの和集合として表現される。この数がある閾値を越えた場合は、和集合を近似する。近似された集合はより大きい1つの集合への近似(拡大近似)とより小さい1つの集合への近似(縮小近似。空集合の場合もある)のペアとして表現する。尚、参照リージョンの表現に現われる式は定数だけでなく、変数を含むことも許している。
2.5 手続き間並列化
手続き間並列化は上記解析結果およびリダクションなどの独自解析の結果から、手続き呼び出しを含むループを並列化する。以下では、DOALL並列化のみ説明する。
特別な変換なしにループを並列化できる条件は、ループ運搬のフロー依存、逆依存、及び出力依存がないことで与えられる。スカラ変数ではこれらの条件を一つひとつチェックするのではなく、スカラ変数への定義があったらループ運搬依存があると判定している。即ち、
MOD ≠φ (1)
なら、そのループは並列化不能である(インダクション変数は除く)。配列では、上記の各ループ運搬依存をチェックし、一つでも依存が存在すればループは並列化不能であると判定している。以下に参照リージョンを用いたループ運搬フロー依存のチェック方法を説明する。
まず、各参照リージョンに対して、解析対象ループに関する以下の3種類の参照リージョンを計算する。1つ目はループ繰り返しi回目。但し、iは一般の値を取る変数を表わす。2つ目はループ繰り返し1回目から(i-1)回目までの和集合。3つ目は全ループ繰り返しに対する和集合である。
これらを用いると、ループ運搬フロー依存が存在することのチェック方法は以下となる。
MODA [1:i-1] _EUSEA [i:i] ≠φ (2)
式(2)がループ運搬フロー依存を示すのは以下のように説明できる。まず、次の式(3)は依存距離が1のループ運搬フロー依存の存在を示すことは定義から容易にわかる。
MODA [i-1:i-1] _EUSEA [i:i] ≠φ (3)
したがって、式(2)は依存距離が1からi -1までの範囲のいずれかのループ運搬フロー依存があることを示す。iは一般の値を取る変数なので、式(2)は結局、いずれかの依存距離を持つループ運搬フロー依存の存在を示す。
次に、変換を伴う並列化方法について以下に概略を説明する。
| (1) | 手続き間変数プライベート化:ループの各繰返しで変数の使用の前に必ず定義がある時、この変数への参照を各スレッド固有の変数への参照に変更することで、ループ運搬依存をなくしてループが並列化できる。これが可能な条件はスカラ変数に対してはEUSE =φ、配列に対してはEUSEA [i]=φである。 |
| (2) | 保証コード生成:プライベート化された変数・配列に対して、それらの初期値設定(初期値保証)、並列ループ終了時の変数値の設定(終値保証および条件付終値保証)を行う。初期値保証は、例えば、EUSEA [i]={1}, MODA [i] _{1} =φの時、ループ直前のA(1)の値を各スレッドのプライベート配列のA(1)に設定する。終値保証は、変数の定義が条件文下になければ、最終ループ繰返しにおけるプライベート変数の値をループ終了時の変数の値として設定する。条件付終値保証は、変数の定義が条件文下にある場合、定義が発生した最後のループ繰返しを記録しておき、その繰返しを実行したスレッドの値をループ終了時の変数の値として設定する。ループが手続き呼出しを含む場合は、ループから呼び出される全ての定義が条件文下にあるか否かをチェックし、そのような定義に対してはある大域変数に定義の発生を記録して、並列ループ終了直前に定義が発生した最後のループ繰返しを検出する。 |
| (3) | リダクション並列化:SUM, PRODUCT, MAX/MIN, MAXLOC/MINLOCなどのリダクションパターンを検出してリダクション固有処理に変換した後、ループを並列化する。リダクションパターンの検出は、ループから呼び出される各手続きで各変数毎に、リダクションパターンを持つか否か、リダクション以外のパターンを持つか否か、リダクション演算の種類を解析し、ある変数がループ中でリダクションパターンのみを持ち、リダクション演算の種類が唯一である場合にリダクション並列化を適用する。 |
2.6 性能評価
SPECfp95/turb3dに対してWPPが生成するOpenMPプログラムの性能評価を行なった。評価マシンは、SGI TM 社のOrigin TM
2000である。Origin 2000は、2CPUから成る共有メモリプロセッサ(SMP)を1ノードとする分散共有メモリ型マシンである。CPUはMIPS
R10000(195 [MHz])である。生成したOpenMPプログラムはMIPS Pro Fortranでコンパイルした。コンパイルオプションは以下である。
-mp -Ofast=ip27 -OPT:IEEE_arithmetic=3
2.6.1 並列実行性能の評価
Turb3dには、6つの手続き呼出しのみを含む4つの主要ループがあり、実行時間のほとんどはこれらのループによって占められている。これらの各ループは、ループ毎に同じ手続きを呼び出しているが、各呼出し毎に実引数の定数値が異なる。WPPによる手続き間並列化では、同じ手続きでも実引数値が異なるごとに別のクローン手続きを作成することによって、これら実引数値を呼出し先手続きに伝播させ、IF文の削除、配列添字の単純化をコンパイル時に行なうことができた。更に、連立1次不等式を用いた手続き間配列解析により、ストライド参照の検出や異なる次元の引数配列に対応でき、4つの主要ループ全てが並列化された。
図3は並列実行性能の評価結果である。ほぼリニアな台数効果を得たことがわかる。
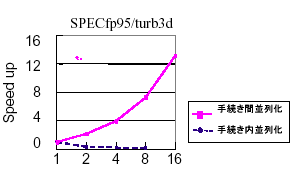
図3:Origin2000上での並列実行性能
2.6.2 手続き間定数伝播の評価
表3は、turb3dからWPPが自動生成したOpenMPプログラム(IP)とそのOpenMPプログラムにおけるOpenMP指示文を元のturb3dプログラムに挿入しただけのプログラム(manual)とのOrigin
2000上での実行時間を比較した結果である。
IPの実行時間はmanualに較べて、最低で14.4%、最高では33.5%高速である。この原因を確かめるために、Origin 2000の1プロセッサでプロファイルを取った。その結果、IPとmanualのキャッシュミス回数は1%しか差がなかったが、実行命令数はIPの方が31%だけ少なかった。よって、手続き間定数伝播により、IF文の削減等による命令数の削減や変数の定数化による命令数の少ないコードの生成ができたと考えられる。
| 台数 | 1 | 2 | 4 | 8 | 16 |
| manual | 324.9 | 179.7 | 101.3 | 54.4 | 36.0 |
| IP | 274.6 | 148.4 | 79.8 | 46.6 | 23.9 |
| manual - IP
manual |
15.5% | 17.4% | 21.3% | 14.4% | 33.5% |
3. 他コンパイラにおける手続き間解析
本章では、商用及び研究コンパイラにおける手続き間解析の動向を述べる。
IBM のXL Fortran v.7.1[5]では、以下のように積極的に手続き間解析を行なっている。しかし、手続き間自動並列化は未サポートと思われる。
SGIのMIPSPro Fortran 90 [6]も以下のように積極的に手続き間解析を行なっている。このコンパイラでは自動並列化の時、インライン展開は必須とあるので、狭義の手続き間並列化は未サポートと思われる。
以上の2社は共に手続き間並列化をサポートしてない。このこととサポート項目より、手続き間解析の対象はスカラ変数のみであり、配列に対する参照リージョン解析は未サポートと予測できる。
以下の各社のコンパイラは手続きインライン展開のみサポートしている[7][8][9]。
- Forte Fortran/HPC (Sun Microsystems Inc.)
- Fortran Compiler for Linux (Intel)
- Visual Fortran (Compaq)
- Compaq Fortran for Tru64 UNIX/Linux Alpha/OpenVMS Alpha (Compaq)
KAPTM [10]も手続きインライン展開のみサポートしている。OpenMPプログラムを生成する時は、インライン展開した時の解析結果を利用するが、指示文はインライン展開しない元のプログラムに挿入する。
Stanford大のSUIFコンパイ [11]は、狭義の手続き間解析による以下の解析を行なう。
Illinois大のPolarisコンパイラ及びPurdue大のPolaris/OpenMP [12][13]はインライン展開を行なって手続き間解析を行なっている。Purdue大のEigenmann教授によると最近、狭義の手続き間解析をやっているとのことだがその研究に関する発表はない。
4. コンパイラ解析情報表示ツールAivi
我々は、手続き間解析の結果を利用したコンパイラ解析情報表示ツールAivi(Analysis Information Visualizer)を開発している[3][4]。本章では、Aiviの機能について述べる。
4.1 並列化チューニング方法
我々は、手続き呼び出しを含むループに対する並列化チューニング方法は以下のように進むと考えている。
ステップ1:最も時間のかかるループの検出
ステップ2:そのループの外側ループの検出
ステップ3:外側ループ群中、最も効率的な並列ループの検出
ステップ1は既存のツールが利用できる。手続き呼び出しを含まないループに対しては、ここで検出されたループを最適化すれば良い。ところが、このループを含む手続きが複数の呼び出し点から呼ばれている場合、このループは何度も呼び出されるために実行時間が長くなり、重要なループとして検出されるが、実際はその呼び出し点を含むループを並列化する方が実行性能が良いことがあり得る。そこで、ステップ2が必要となる。次に、こうして得た外側ループに対して、ステップ3でデータ依存関係を調べ、なるべく外側で、効率良く並列化できるループをさがす。ループが自動並列化できない原因は、自動並列化コンパイラがデータ依存を精度良く解析できないことにある。ユーザはそれらの不明確なデータ依存をチェックし、ループ並列性を判定しなければならない。
以上を実現するため、Aiviは以下の2つの機能を持つ。
1) 与えられたループの外側ループを手続き境界を越えて検出すること
2) あるデータ依存の依存元と依存先を手続き境界を越えて検出すること
4.2 並列化構造表示・外側ループ検出機能
プログラム全体の並列化構造を視覚化し、外側ループを検出しやすくするためにAiviは以下の機能を持つ[3][4]。各機能のループ等は相互にリンクされている。
| (1) | コールグラフ ループや手続き呼出しを、各々、インデント付きの四角形や三角形でコールグラフのノード上に実行順に表示する。並列化ループは色付けする。これらから手続き内の外側ループと呼び出し元手続きが分る。 |
| (2) | プログラムフィルタリング プログラムから、手続きの開始・終了、ループ、手続き呼出し点等の、並列化に関連する文のみ抜き出して表示できる。これから手続き呼出し点やそれを含むループがすばやく検出できる。 |
| (3) | インライン展開表示 手続き呼出し点直後に呼び出し先プログラムを挿入して表示できる。これにより多重の呼び出しにまたがるループ間の包含関係がわかる。 |
4.3 手続き間データ依存位置検出機能
図4は手続き間データ依存位置検出機能を説明した図である。 (a)は従来のツールによるデータ依存位置検出機能が表示可能なデータ依存位置である[14][15][16]。解析対象ループLと同じ手続き(ベース手続きと呼ぶ)内にある、ループLに関して運搬依存のある文が
表示される。 (b)は手続き間データ依存位置検出機能が表示可能なデータ依存位置である。ベース手続き内の文S1とベース手続き内から呼び出される手続き内にある、ループLに関して文S1とループ運搬依存のある文Qが表示される。本機能は以下の2つに分かれる。
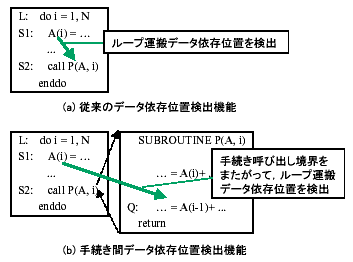
図4:手続き間データ依存位置検出機能
4.3.1 ループ内全データ依存位置検出機能
本機能は、ループに含まれる。ループと同じ手続き内にある文の対のうち、データ依存関係にあるものを全て検出する。この検出方法として、全ての文同士を比較するよりも比較回数が少なくなることを期待して、本機能では階層的解析方式を採用している。これはループボディに対するCFSグラフを用い、データ依存のあるノードの対を、上位階層から下位階層に向かって順番に検出していく方式である。
4.3.2 手続き間段階的データ依存位置検出機能
本機能は、前項で検出された文の対のうち、一方が手続き呼び出しで、それをユーザが選択した場合、その呼び出し先手続き中にある、データ依存関係にある文を検出する。本機能では、与えられたループから呼び出される全ての手続きに対して一括して解析するよりも解析時間・解析データ量が少なくなることを期待して、段階的解析方式を採用している。これは解析対象ループ中の、ユーザが選択した手続きに対してのみデータ依存位置をその都度、解析し、その結果をユーザに表示する方式である。正確には、一括解析は、初回には解析に多くの時間がかかるが、ユーザ選択時にはユーザ指示に従って解析結果を表示するだけなのでレスポンスは良い。しかし、ユーザが選択してない手続きに対しても解析することになり、解析時間・データ量が無駄になるので、段階的解析方式を選択した。
図5はデータ依存位置リストの表示である。メインプログラムの8行目から呼び出されるDEFAと9行目から呼び出されるUSEA内のデータ依存(17、23行目)をユーザが表示したことを示し、現在、ユーザが選択しているのはDEFA内の17行目の文であることを強調表示している。
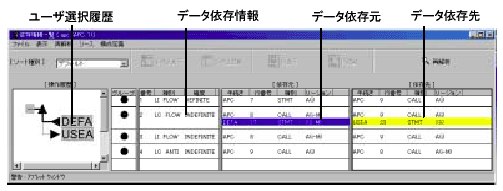
図5:データ依存位置リスト表示ウィンドウ
5. 他ツールにおける手続き間解析
本章では、ツールにおける手続き間解析の利用に関する動向を述べる。
Rice大のParaScope Editor[14]は対話的解析・プログラム変換ツールである。データ依存元と依存先をリスト表示し、ソースプログラム上でそのデータ依存を矢印で表示する。また、両方のデータ依存位置が離れている場合にはソースプログラムの一部を隠蔽して、それらを1画面に表示することが可能である。以下を行なう。
Stanford大のSUIF/Explorer[15]は対話的解析ツールである。ある文で参照する変数に対して、その変数値に影響を与える可能性のある文から成るプログラムスライス[20]を表示する。また、データ関係にある文をソースプログラム上で強調表示する。以下を行なう。
Parallel Software Products Inc.のCAPTools [16] は、Greenwitch大、Nasa Ames等で開発されてきた。CAPToolsは対話的解析及びSPMDコード生成ツールである。データ依存元と依存先をノードとする依存グラフを表示する。以下を行なう。
GrammaTech Inc.のCodeSurfer[17]は、Sun, IBM, HP, SGI 各社のマシンにインストールされている。以下を行なう。
6. おわりに
手続き間解析は商用の最適化コンパイラでも採用されつつある。その解析対象はまだスカラ変数程度であるが、自動並列化を目指した配列解析も徐々にサポートされると考えられる。一方、ツールに関しては、手続き間解析をサポートした商用ツールはまだ少ない。しかし、プログラムがモジュール化されてゆくにつれて、ツールにおいても手続き間解析のサポートが広がるものと考えられる。
参考文献
| [1] | 青木等:手続き間自動並列化コンパイラWPPの試作 −実機性能評価−, 情処研究報告, 98-ARC-130, pp.43-48 (1998). |
| [2] | 佐藤等:手続き間自動並列化コンパイラWPPの評価, 第130回計算機アーキテクチャ研究会(SHINING 2001 (2001)). |
| [3] | 佐藤等:コンパイラ解析情報ビジュアライザAivi, 情処第62回全国大会, 4R-05, Mar., (2001). |
| [4] | M. Satoh et al. "Interprocedural Parallelizing Compiler WPP and Analysis Information Visualization tool Aivi", Proceedings of The Second European Workshop on OpenMP (EWOMP 2000), pp. 38-47, 2000. |
| [5] | Bob Blainey. "Performance Programming with IBM pSeries Compilers", SCICOMP4 (IBM SP Scientific Computing User Group) Oct. 2001. |
| [6] | SGI's online-manual (IRIX 6.5 Man Pages: IPA(5)), http://www.sgi.com. |
| [7] | http://www.sun.com/forte/developer/documentation/mr/READMEs/c.html#upd2a |
| [8] | http://developer.intel.com/software/products/compilers/f50/linux/finfo_ipo.htm |
| [9] | http://www.compaq.com/fortran/docs/ |
| [10] | Kuck and Associates, Inc., http://www.kai.com/ |
| [11] | M. Hall et al. "Maximizing Multiprocessor Performance with the SUIF Compiler", IEEE Computer, pp.84-89, Dec. 1996. |
| [12] | Polaris/OpenMP, http://polaris.cs.uiuc.edu / |
| [13] | W. Blume et al. "Parallel Programming with Polaris", IEEE Computer, pp.78-81, Dec. 1996. |
| [14] | M. Hall et al. "Experiences using the ParaScope Editor: an Interactive Parallel Programming Tool", Proceedings of PPoPP '93, 1993. |
| [15] | S. -W. Liao et al. "SUIF Explorer: An Interactive and Interprocedural Parallelizer", In proceedings of the 7th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPOPP'99), pp. 37-48, Atlanta, Georgia, May 1999. |
| [16] | S. P. Johnson et al. "Computer Aided Parallelization Tools (CAPTools) User Manual, CAPTools Version 2.0Beta", Oct. 1998. http://captools.gre.ac.uk. |
| [17] | http://www.grammatech.com/ |
| [18] | OpenMP Fortran Application Program Interface Ver 1.0, Oct. 1997. http://www.openmp.org. |
| [19] | W. Pugh. A practical algorithm for exact array dependence analysis. Communications of the ACM, 35(8), pp. 102-114, 1992. |
| [20] | M. Weiser, Program slicing, IEEE Transactions on Software Engineering, 10(4), pp. 352-357, 1984. |