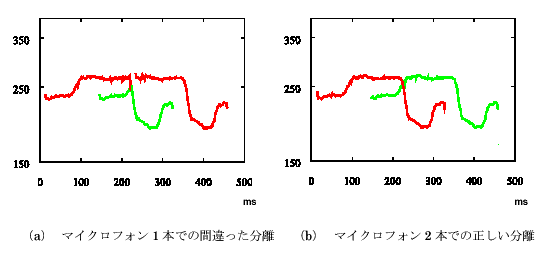
濃い線と薄い線が分離された音声を示す。
図 3.1-1 2話者同時発話分離でのあいまい性
報告者: 奥乃博主査
聴覚は人間にとって最も重要な感覚である。言語によるコミュニケーションが聴覚によって成立することは容易に理解されるが、「ヒトは聴覚によってのみ言語を獲得し、そこに文化が生まれ、継承される。書かれた言語は目によって伝承されるが、話す言葉は耳からしか得られない。話し言葉があって書く言葉が生まれる」ことを、多くの人が理解していないのは残念なことである。
鈴木淳一、小林武夫共著『耳科学 - 難聴に挑む』(中公新書、1598、2001)
3.1.1 はじめに
鉄腕アトムの誕生の年2003年が近づき、ヒューマノイドと呼ばれる人間型ロボットが数多く開発されるようになった。新千年期までは、早稲田大学で30年間以上にわたるヒューマノイド研究で開発された2足歩行ロボットWabianや人間との協調作業を行うHadalyなど、あるいは、ホンダで10年間以上にわたり開発されてきたP3など、一連のヒューマノイド群ぐらいであった。
今日では、ホンダのASIMOや科学技術振興事業団北野共生システムプロジェクトのPINOはテレビ放送のCMにも登場している。科学技術振興事業団川人プロジェクトの油圧式制御によるDBは、脳神経科学の成果を生かした複雑な運動制御ができ、見る人を驚かせる。映画スターウォーズに登場するロボットR2D2の形をしたNECのPaperoやATRのRobovieなどのほかに、動物型のロボットも次々と登場してきている。
これらのロボットの多くは、マイクロフォンを装備している。その本数は、2本、ないし、3本のものが多いが、マイクロフォンアレイを搭載しているものもある。本節では、「耳が2つある」ことがロボット聴覚において本質的であるかを検討する。なお、ヒトの聴覚については生理学や心理物理学などで数多くの知見[1]が得られているので、そのような研究は他の解説に譲る。
濃い線と薄い線が分離された音声を示す。
図 3.1-1 2話者同時発話分離でのあいまい性
3.1.2 我々が日常聞く音は混合音
一般に、我々が日常生活で耳にする音は単一音源からの音ではなく、複数の音源からの音が混じった混合音である[11]。2つの音から構成される混合音の分離を1本のマイクロフォンで行うと、分離結果にあいまい性が含まれる恐れがある。
例えば、時刻ごとに調波構造を抽出し、基本周波数の時間的連続性を基にグルーピングすることによって、調波構造をもつ音響ストリーム(以下、調波構造ストリームと呼ぶ)を分離するとしよう。このシステムで、同じ話者の「あいうえお」という発話をずらして録音したモノラル音を分離させると、一方が「あいうーーえお」、もう一方が「あいえお」と誤分離される場合がある(図
3.1-1)[6]。
もし、2つの音が別々の方向から到達する場合には、そのような音を2つのマイクロフォンで聞くことができれば、方向情報が利用できるので、調波構造ストリーム分離でのあいまい性は解消できる。図
3.1-1に、同じ発話を、時間を150msずらして、左右30度から行ったときの分離結果を示す。図からわかるように、マイクロフォン1本のときには、調波構造のグルーピングが間違ってしまうのに対して、マイクロフォン2本を使用した分離では、方向情報が利用できるので、調波構造だけを手がかりとした分離で遭遇するあいまい性は解消されている。
3.1.2.1 混合音分離の手法
混合音の分離には、マイクロフォンアレイが一般的に使用される。マイクロフォンアレイで得られたマルチチャネルのデータから特定方向の音だけを抽出するには、ビームフォーミングや独立成分解析(ICA:
Independent Component Analysis)といった技法がよく使われる。ビームフォーミングの原理は、「N + 1本のマイクロフォンで、N個の音響的な死角が作成できる」というものである。ビーフフォーミング技法で音源分離によく使用されるのは、遅延型加算(delayed
sum)である。
すべての音源が情報論的に互いに独立であるとすると、独立成分解析を使えば、N本のマイクロフォンでN個の音源を理論的に分離することができる[5]。実際、2本のマイクロフォンによる2話者同時発話分離では、独立成分解析の方が、調波構造と方向情報を手がかりにした分離よりも、分離音の音声認識結果がよいという結果が得られている[9]。Wangらも複数のマイクロフォンを使用することによって、音響ストリーム分離の精度の向上を達成している[13]。
つまり、マイクロフォンの数を増やせば、音源分離の性能が向上することは、理論的にも、実験的にも明らかである。では、マイクロフォンは何本用意すればよいのか?「想定される音源の数より多ければよい」が正解なのであろうか。
一般環境では、マイクロフォンの位置が変化したり、音源が移動したりするので、必ずしも理論通りに行かない。体の動くロボットに装着したマイクロフォンは、頻繁に動くし、ロボットの体に何十本というマイクロフォンを装着することも現実的ではない。もちろん、このような状況にも適用可能なマイクロフォンアレイを開発する研究プロジェクトも始まっている[12]。
報告者らは、このような問題を「マイクロフォンの数が音源の数よりも少ないときに、音源分離を行うにはどのようにしたらよいのか」ととらえ、研究を進めてきた。次のように問題は整理できよう。
(1) 体が固定されたときに、耳がいくつ必要か。
(2) 逆に、自由に体の動きが許されるときに、耳がいくつ必要か。
前者の問題については、方向情報を得るためには、最低2本のマイクロフォンは必要であると考えている。後者の問題については、最少解は1本のマイクロフォンであろう。しかし、上述したような理由から、実用的な意味での最少解は、2本のマイクロフォンではないかと予想している。3本のマイクフォンを装備しているロボットもあるが、処理の基本は2本のマイクロフォンであり、2本のマイクロフォンでは難しい「前後問題」を残り1本のマイクロフォンで解決している[2]。
以下、2つの耳で十分かを検討をする。

図 3.1-2 上半身ヒューマノイドSIG
3.1.2.2 2本のマイクロフォンによる音源定位
人間の耳の聴覚機能として、音源定位のモデルとして知られているJeffressのcross-correlatorモデルは、2本のマイクロフォンから得られた入力音を遅延させながら相関をとり、最大の相関を与える遅延から両耳間時間差(Interaural
Time Difference: ITD)を求めるものである[3]。
Jeffressのモデルは、ITDしか使用していないが、のちの研究では両耳間強度差(Interaural Intensity Difference:
IID)も音源定位に寄与するように修正されている。ITDとIIDは周波数帯域によってその貢献度が異なる。一般のヒトの場合には、1500Hz付近を境に、それ以下ではITDが、それ以上ではIIDが優位であることが知られている[4]。
ITDの代わりに両耳間位相差(Interaural Phase Difference: IPD)を使用すると、ITDとIIDの役割が変わる1500Hzという値を決める1つの要因が得られる。両耳間の顔の表面上の距離がおおよそ23cmとすると、IPDが初めて2ssになる、つまり、定位の際に、1周期まわり込みによって簡単にあいまい性が解消できなくなるのが、1500Hzである。ただし、ssとなる750Hzから、前後がわからなくなるというあいまい性が生じる。報告者らは図
3.1-2に示すSIGと呼ぶ上半身ロボットのための聴覚機構を開発中である。SIGの両耳間距離は18cm、頭部形状を考慮し、外装に沿った両耳間距離が約23cmとなり、ほぼヒトと同じような値で、IPDとIIDの役割が変わる。
2本のマイクロフォンを使用して音源定位を行うためには、IPDやIIDの方向情報との関係を示す頭部伝達関数(Head-Related Transfer
Function: HRTF)が必要である。
中谷と奥乃らのグループは調波構造に注目した音源分離システムを構築し、無響室環境で2話者同時発話の音声分離を行っている[6]。このシステムは、調波構造を抽出し、左右の耳で同じ音源から来る調波構造を持った音のペアを抽出し、その音の各倍音のIPDとIIDを計算し、それらの値からHRTFを基に方向情報を求める。このようにして求まった調波構造断片を方向情報でグルーピングし、調波構造ストリームを抽出する。この方法は、基本周波数が重ならない限り、理論的には音源数がいくつあっても音源定位とそれに基づいた音源分離が可能である。実際には、混合音中の調波構造抽出の精度は音源数が増えるにしたがって低下するので、音源数が増えると精度のよい分離は難しくなる。例えば、2話者同時発話の上位10位の単語認識率75%が、3話者同時発話認識では30%程度と大幅に分離性能が劣化する[10]。
このような問題点を回避するため、著者らは、特定の音源方向から来る音だけを分離する方向通過型フィルタ(Direction-Pass Filter: DPF)を設計した。DPFにおける方向推定のアイディアは、IPDとIIDに関して、実際の値と所与の方向情報から得られるHRTFからの値との間の距離から確信度を計算し、IPDとIIDの確信度をDempster-Shafer理論で統合するという仮説推論にある。
具体的には、各サブバンド(離散フーリエ変換、DFTの各点)で、IPDとIIDを求める。次に、それらと所与の方向情報のHRTFから求めたIPDとIIDとの距離を計算し、確率密度関数を用いて、それらを確信度に変換する。最後に、2つの確信度をDempster-Shafer理論で統合し、統合確信度の高いサブバンドだけを集めて、逆離散フーリエ変換で分離音を再構成する。無響室環境におけるDPFによる3話者同時発話認識では、ほぼ単一音源並みの単語認識率が達成されている[10]。
HRTFは無響室で、スピーカの位置を変え(例えば5度刻み)、インパルス応答を測定することによって求める。そのために、無響室以外では、実際の環境での空間伝達特性を畳み込まないと、得られる方向情報の精度が低下する。マイクロフォンの位置が変化するようなシステムの場合には、HRTFの測定と同様にスピーカ位置を変化させるだけでなく、マイクロフォンの位置も変化させて、空間伝達特性を測定する必要がある。また、測定点数の制限から離散的な方向情報しか使えないので、移動音源への対処は難しくなる。
ここまでの議論では、静的な環境での音源分離であった。それに対して、実環境で動き回るロボット、あるいは、頭部を動かす機能があるロボット、あるいは、行動と知覚が結びついたアクティブパーセプションでは、マイクロフォン自体が動き、それに伴って、モータ雑音や機械音が発生する。このような音は、例え小さくてもマイクロフォンに近いので、相対的に大きな雑音となり、外部からの音の信号雑音比が低下する。
ロボットやシステムが発生する内部雑音を軽減する最も簡便な方法は、動作を中断してから、聞くことである。実際、このような"stop-perceive-act"法を、マイクロフォンを搭載した大部分のロボットが採用している。
アクティブオーディションでは、内部雑音や自己生成音の抑制がきわめて重要である。特に、ロボットヒューマンインタラクションでは、自分の発話を削除し、相手の発話の信号雑音比を向上させることも必要である。また、よく聞こうとして動いたところ、自分の出す音が災いして、かえって聞こえ難くなるということも想定される。
3.1.3 複数話者実時間追跡システム
本節では、2つの耳でどのような機能が実現可能かを示すために、図 3.1-2に示したSIGの上に実現されている複数話者実時間追跡システムを紹介する。このシステムは、繁華街の大通りに面したマンションの一室(3m×3m)に置かれている。
3.1.3.1 2本のマイクロフォンによる音響と画像を統合した実時間複数話者追跡
本システムのアイディアは、以下の通りである[7]。
(1) HRTF使用上の問題点である、部屋の伝達特性が必要であり、離散的な点のHRTFしか使えない、という2点を解決するために、聴覚エピポーラ幾何学を提案し、HRTFに相当する部分を代用する。これは、ステレオ画像処理でのエピポーラ幾何学の焼き直しであり、ステレオカメラとマイクロフォンの位置が一定であることを利用して、画像処理から得られる3次元位置を使って、IPDとIIDを求める。音源が無限遠にあるときには、聴覚エピポーラ幾何学で求めた値と、幾何学的に求めたIPDやIIDの値[4]とは一致する。
(2) SIGでは、体内に有する1対のマイクロフォンから取得されるモータ音や機械音についての簡単なモデルを持っており、モータが稼働中でモデルに合うような音が発生すると、ヒューリスティクスを用いて、破壊されているサブバンドを推定し、破棄する。ヒューリスティクスによる方法を採用したのは、FIRフィルタを応用したアクティブノイズキャンセレーションでは、IPDを計算するために必要な左右の位相特性の線形性が実データでは成立しないからである。
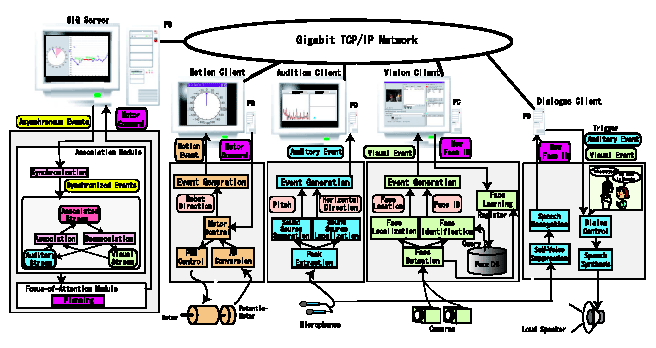
図 3.1-3 視聴覚統合による実時間話者追跡システム
システム全体の構成を図 3.1-3に示す[8]。システムは、音響処理部、画像処理部、モータ駆動部、アソシエーション部、対話管理部、注意制御部、および、サーバから構成されている。これらは5台のPC上に配置されており、Gigabit
Ethernetで接続されている。音響処理部はDPFと同じ考え方で、音源方向を抽出する。ただし、画像からの音源方向が得られない場合には、すべての方向について仮説を生成することによって、音源方向を抽出する。抽出した方向情報は、確信度とともにアソシエーション部に送られる。画像処理部は、肌色抽出により顔を発見し、ステレオ画像処理により、3次元情報を取得する。さらに、抽出した顔ごとに顔認識を行い、3次元情報と顔ID情報をアソシエーション部に送る。モータ駆動部からは、現在のSIGの体の向きについての情報をアソシエーション部に送る。
アソシエーション部では、各モジュールから得られる情報(方向や顔)を同期させ、音響ストリームと画像ストリームを構築する。次に、音響ストリームと画像ストリームを、時間的継続性や距離的近さを基にグルーピングをし、アソシエーションストリームを構成する。一定時間、音響ストリームや画像ストリームが消失すると、アソシエーションは解除される。
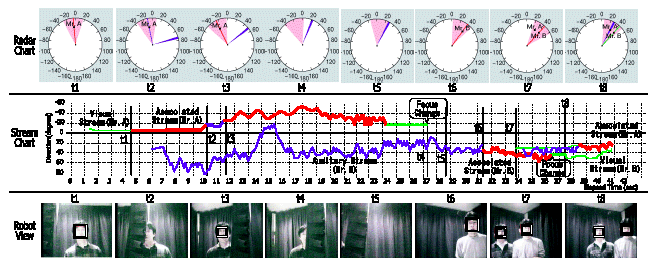 Radar ChartとStream Chartはviewerのスナップショットである。 radar chart上の幅広い扇形は、カメラの視野を示し、狭く鋭い扇形は音源方向を示す。 stream chart上の細い線は、音響ストリームか画像ストリームを、太い線はアソシエーションストリームを示す。 図 3.1-4 2話者追跡の時間経過 |
実際の2話者追跡の時間経過を図 3.1-4に示す。時刻t1で左側の人(Mr. A)がしゃべり始め、画像ストリーム(細い線)と音響ストリームがアソシエートされ、アソシエーションストリーム(太い線)が構築される。Mr.
Aはしゃべりながら移動し、t2で物影に隠れ始め、t3で再び現われる。この間、アソシエーションは一時的に解除される。Mr. Aはさらに移動し、しゃべるのを止め、t4で再び物影に隠れ始める。システムは、Mr.
Aのストリームのアソシエーションを解除し、画像ストリームへ変更し、さらに、t4で消滅させる。
一方、Mr. BはMr. Aから少し遅れてしゃべり出し、音響ストリームが構築される。図 3.1-4から、音響ストリームの音源定位の精度は画像よりも格段に劣ることがわかる。システムは、t4でMr.
Bの音響ストリームに注意を向け、回転をし、t5では何も見えず、t6でMr. Bの顔を発見し、画像ストリームと音響ストリームをアソシエートする。t7でMr.
Aが現れ、また、しゃべり出し、同様にアソシエーションストリームが構築される。顔認識により、システムはt4とt7の2名が同一人物であることがわかる。t8でMr.
Bがしゃべり終わり、注意がMr. Aに移る。以上のように、システムは、内部的には複数の話者や人物の位置を常時把握している。
3.1.3.2 注意制御部
注意制御部は、システムが保持する話者や人物情報をもとに、どの対象に注意を向け、体を回転し、正対するのかを制御する。この部分は完全にプログラム可能であるので、いくつかのシナリオで、SIGの挙動を紹介する。
受付嬢: 話している人に注意を向けるのが第一目的であり、そうでなければ、音のする方向に振り向く。図 3.1-4に示したように、注意を置くべきストリームの優先順位は、(1)アソシエーションストリーム、(2)音響ストリーム、(3)画像ストリームである。
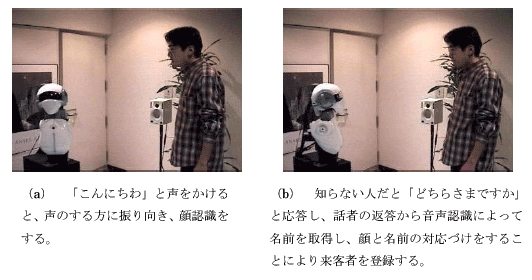
図 3.1-5 受付嬢としてのSIGの振る舞い
具体的な挙動を図 3.1-5に示す。来客が知らない人だと、「どちらさまですか」という応答をし、名前と顔との照合データを登録する。既知の人の場合には、「こんにちは、XXさんでいらっしゃいますか」とその人の名前を呼び、確認を行う。このように、対話管理部は顔認識・音声認識・音声合成を含んでおり、自己生成音の抑制と音声の分離を行っている。音声認識はフリーのディクテーションソフトウェアであるJuliusを使用し、音声合成は市販のソフトウェアを使用している。
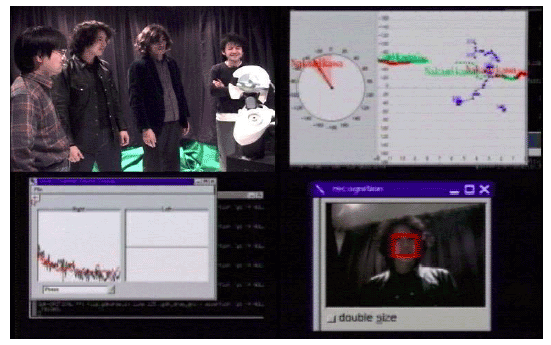
(a) 4人の話者で声のする方を向く。
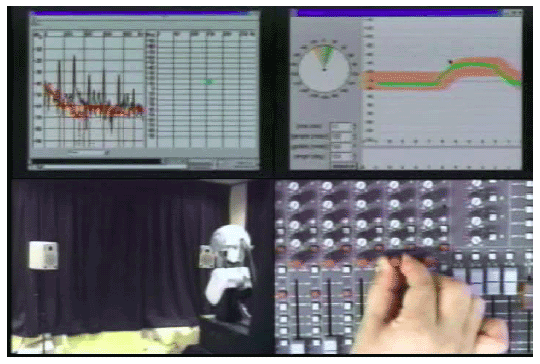
(b) バランスコントロールの音源定位に追従する。
図 3.1-6 SIGの音源追跡のさまざまな評価実験
コンパニオン: 「聞き耳を立てる」ために、新たな音のした方に注意を払うように、(1)音響ストリーム、(2)アソシエーションストリーム、(3)画像ストリームという優先順位を設定する。4人の中で話し声に顔を向ける実験風景を図
3.1-6(a)に示す。
仮想音源: 追跡するものは、人物だけではなく、仮想的な音源であってもよい。基本周波数が100Hzの調波構造を持つ音を左右のスピーカから流し、そのバランスコントロールを変化させることで、仮想的に音源を左右に振る。SIGは仮想的な音源を正しく追跡する(図
3.1-6(b))。
以上の例から、2本のマイクロフォンでも、画像処理と統合すると、実時間で音源定位を行い、話者追跡を行えることがわかった。2本のマイクロフォンによる音源定位の前後問題のあいまい性は、画像を使えば解消はできよう。また、アクティブオーディションにより、体の回転に対して、音源がどちらに動くかという情報からも、前後問題のあいまい性は解消できよう。
3.1.4 おわりに
本節では、ロボットには耳(マイクロフォン)は2つで十分かという問いに対して、現状で実現できた聴覚機能について、著者の考え方も含めて解説をした。体を動かして聞くというアクティブオーディション、音響処理と画像処理(3次元位置情報と顔認識)やモータ処理との情報統合が重要である。このために、方向通過型フィルタや聴覚エピポーラ幾何学、実時間処理方法を開発してきた。今後の課題としては、複数話者の話者認識や音声認識が挙げられる。このためには、話者認識や音声認識のフロントエンドとしての精度のよい音源分離、および、雑音の混入により失われたデータをうまく回避できる話者認識や音声認識の双方からの研究が必要であろう。
冒頭に引用した一節からも、聴覚機能というのは人間生活にとってきわめて重要であり、そのような原点に戻り、音響処理の新しい枠組みを打ち立てることが、音声認識システムが一般的となってきた今求められてことではないであろうか。本節が、そのような新しい潮流の一助となれば幸いである。
参考文献
| [15] | Bregman, A. S.: Auditory Scene Analysis - the Perceptual Organization of Sound, The MIT Press (1990). |
| [16] | Huang, J.: Spatial Sound Processing for a Hearing Robot, Enabling Society with Information Technology, LNCS, Springer-Verlag (2001). |
| [17] | Jeffress, L.A.: A Place Theory of Sound Localization, Journal of Comparative Physiology, Vol. 41, pp. 35-39 (1948). |
| [18] | ムーア, B. C. J., 大串ほか (訳): 聴覚心理学概論, 誠信書房 (1994). |
| [19] | Murata, N. and Ikeda, S.: An On-line Algorithm for Blind Source Separation on Speech Signals, Proceedings of 1998 International Symposium on Nonlinear Theory and its Applications, pp. 923-927 (1998). |
| [20] | 中谷智広, 奥乃博, 川端豪: 音環境理解のためのマルチエージェントによる調波構造ストリームの分離, 人工知能学会誌, Vol. 10, No. 2 pp. 232-241 (Mar. 1995). |
| [21] | Nakadai, K., Lourens, T., Okuno, H.G., and Kitano, H.: Active Audition for Humanoid, Proceedings of AAAI-2000, pp. 832-839 (Aug. 2000). |
| [22] | Nakadai, K., Hidai, K., Mizoguchi, H., Okuno, H., and Kitano, H.: Real-time Auditory and Visual Multiple-object Tracking for Robots, Proceedings of IJCAI-01, pp. 1424-1432 (2001). |
| [23] | 奥乃博: 音環境理解 - 混合音の認識を目指して, 情報処理, Vol. 40, No. 10, pp. 1096-1101 (Oct. 2000). |
| [24] | Okuno, H.G., Nakadai, K., Lourens, T., and Kitano, H.: Separating Three Simultaneous Speeches with Two Microphones by Integrating Auditory and Visual Processing, Proceedings of Eurospeech 2001, pp. 2643-2646, ESCA (Sep. 2001). |
| [25] | Rosenthal, D. and Okuno, H. G. (Eds.): Computational Auditory Scene Analysis, Lawrence Erlbaum Associates (1998). |
| [26] | 田中穂積: 言語理解と行動制御に関する研究 (課題番号12NP9201) 平成12年度科学研究費補助金 (創成的基礎研究) (Mar. 2001). |
| [27] | Wang, F., Takeuchi, Y., Ohnishi, N., and Sugie, N.: A Mobile Robot with Active Localization and Discrimination of a Sound Source, Journal of Robotic Society of Japan, Vol. 15(2), pp. 61-67 (1997). |