恾3.9-1丂Google偺儂乕儉儁乕僕(http://www.google.com/傛傝堷梡)
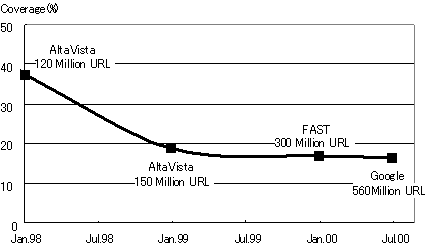
丂僀儞僞乕僱僢僩偺忣曬傪桳岠偵棙梡偡傞庤抜偲偟偰丄崱傗僒乕僠僄儞僕儞偼丄寚偔偙偲偑偱偒側偄懚嵼偲側偭偰偄傞丅偲偙傠偑丄尰懚偡傞庡偨傞僒乕僠僄儞僕儞偼慡偰奀奜偱塣梡偝傟偰偄傞丅僒乕僠僄儞僕儞抋惗偺帪婜偵偼変偑崙偵傕懡偔偺幚尡揑僒乕僠僄儞僕儞偑懚嵼偟丄悽奅偲嫞憟偟偰傕晧偗傞偙偲偺側偄僨乕僞検傪帩偪丄偐偮丄崅惈擻傪幚尰偟偰偄偨偑丄尰嵼偱偼丄晉巑捠偺InfoNavigator[1]丄僼儗僢僔儏傾僀偺FreshEye[2]丄NTT偺ODIN[3]傪彍偗偽奆柍偲尵偭偰傛偄丅傑偨丄僨乕僞検偱斾妑偟偨応崌丄変偑崙偺僒乕僠僄儞僕儞偼丄崙撪偵摿壔偟偨専嶕傪採嫙偟偰偍傝丄Google[4]摍丄奀奜偺僒乕僠僄儞僕儞偺俀寘壓偺僨乕僞検偟偐帩偭偰偄側偄丅杮復偱偼丄側偤変偑崙偱僒乕僠僄儞僕儞偺價僕僱僗偑掕拝偟側偐偭偨偐傪専徹偡傞偨傔偵丄尰帪揰偱嵟傕桳柤偱偁傝丄偐偮丄悽奅嵟戝偺僨乕僞検傪帩偮Google傪椺偵偲傝丄1998擭9寧偺婲嬈帪偐傜尰嵼偵偄偨傞傑偱偺價僕僱僗揑丄媄弍揑側摦岦傪挷嵏偡傞偲嫟偵丄崱屻偺僒乕僠僄儞僕儞偺價僕僱僗儌僨儖偲専嶕媄弍偵偮偄偰峫嶡偡傞丅
丂
丂Google乮恾3.9-1乯偼丄Stanford戝妛偺Ph.D僐乕僗偺妛惗偱偁偭偨Larry Page[5]偲Sergey
Brin[6]偑1998擭9寧偵愝棫偟偨World
Wide Web傪懳徾偲偟偨専嶕僔僗僥儉傪採嫙偡傞夛幮偱偁傝丄Netscape幮偲摨偠暷崙僇儕僼僅儖僯傾廈僒儞僲僛巗偺Moutain View偵埵抲偡傞丅
丂Stanford戝妛偺Computer Science晹栧偵愋傪抲偔Brin偼丄攷巑壽掱偱僨乕僞儅僀僯儞僌偵娭偡傞尋媶傪峴偭偰偄偨丅偦偙偵丄Page偑壛傢傝丄棙梡偡傞僨乕僞偺攞憹傪恾傞偨傔偵Web僨乕僞偺廂廤傪峴偭偨偲偙傠丄Web僨乕僞偵旕忢偵嫽枴傪堷偐傟條乆側夝愅傪帋傒傞傛偆偵側偭偨丅僨乕僞儅僀僯儞僌偺尋媶偵偼朿戝側僨傿僗僋梕検偲僐儞僺儏乕僥傿儞僌僷儚乕偑昁梫偱偁傝丄怴偟偔僐儞僺儏乕僞傪摫擖偟偨強偱偼僐儞僺儏乕僥傿儞僌僷儚乕偑梋偭偰偄側偄偐偳偆偐丄Stanford戝妛撪傪嬱偗偢傝夞偭偰偄偨丅
丂俁擭娫偺尋媶偺屻丄偝傜偵嫄戝側僨傿僗僋梕検偑昁梫偲側偭偨偙偲偐傜丄Page偲Brin偼擇恖偑帩偭偰偄傞慡偰偺僋儗僕僢僩僇乕僪傪巊偭偰TB乮僥儔僶僀僩乯偺梕検傪帩偮僨傿僗僋傪1.5枩僪儖乮栺150枩乯偱峸擖偟偨丅偟偐偟丄偦傟偱傕擇恖偺尋媶偵偲偭偰僨傿僗僋梕検偼廩暘側傕偺偱偼側偔丄斵傜偼丄摉帪惉岟偟偰偄偨Yahoo![7]偵晧偗偠偲丄價僕僱僗僾儔儞傪俀擭娫傕偺娫彂偒懕偗偨丅
丂價僕僱僗僾儔儞傪憲偭偨憡庤偺堦恖偱偁傞Andy Bechtolsheim[8]偲偁傞擔偺憗挬丄Page偲Brin偼夛偆偙偲偵側偭偨丅夛崌偱偼丄Page偲Brin偑斵傜偺價僕僱僗僾儔儞傪愢柧偟廔傢傜側偄撪偵丄Bechtolsheim偼実懷揹榖偱偳偙偐偵揹榖偟偨屻丄乽廩暘偵價僕僱僗僾儔儞偼暦偄偨丅偁偲巆傝偺帪娫偱榖傪懕偗傞傛傝丄偙偙偵彂偔彫愗庤偱價僕僱僗傪偡偖偵巒傔偰傒側偄偐乿偲擇恖偵崘偘丄10枩僪儖乮栺1000枩墌乯偺彫愗庤傪搉偟偨丅偙傟偑Google偺婲嬈偺戞堦曕偲側偭偨丅
丂偦偺屻丄僔儕僐儞僶儗乕偱桳柤側Kleiner Perkins偲Sequoia Capital偺擇戝儀儞僠儍乕僉儍僺僞儖[9]偐傜憤妟2500枩僪儖乮栺25壄墌乯偺弌帒傪庴偗丄1998擭9寧偵Google偑抋惗偟偨丅
丂
丂Google偼丄懠偺僒乕僠僄儞僕儞偲偺嵎暿壔偺偨傔丄専嶕媄弍偵摿壔偟偰偙傟傑偱惉挿傪懕偗偰偒偰偄傞丅堦曽丄Yahoo!丄Altavista摍偺偦偺懠偺僒乕僠僄儞僕儞僒僀僩偼丄僒乕僠僄儞僕儞偺傒偱偼廂塿偑摼偵偔偄偙偲偐傜丄mail傗chat摍偺晅壛僒乕價僗傪儚儞僗僩僢僾偱幚尰偱偒傞傛偆側丄portal壔傪栚巜偟偰偍傝丄僒乕僠僄儞僕儞傪採嫙偡傞儂乕儉儁乕僕偼暋嶨壔偟偰偒偰偄傞丅
丂Google偼丄儂乕儉儁乕僕偺portal壔傪栚巜偟偰偍傜偢丄恾3.9-1偵帵偡傛偆偵儂乕儉儁乕僕偼僔儞僾儖偱偁傝丄奊偺擖偭偨廳偄峀崘傕夋柺偵昞帵偝傟傞偙偲側偔丄儐乕僓偺棙曋惈傪峫偊偨僔僗僥儉偲側偭偰偄傞丅堦曽偱丄僒乕僠僄儞僕儞晹暘偺傒傪堦妵偟偰Yahoo!傗Biglobe(NEC)偵巊偭偰傕傜偆偲偄偆價僕僱僗儌僨儖傪峔抸偟偰偄傞丅價僕僱僗儌僨儖偺徻嵶偼屻弎偡傞丅
丂恾3.9-2偵丄Google偱壱摥偟偰偄傞Linux PC偺戜悢偺悇堏傪帵偡丅摉弶30戜偺Linux PC偱僗僞乕僩偟偨屻丄2000擭6寧偵偼僩乕僞儖偱6000戜傊偲憹壛偟丄暯嬒33戜/擔偺儁乕僗偱憹偊懕偗偰偄傞丅2000擭10寧帪揰偱偺栚昗偼丄2000擭枛傑偱偵10000戜傪払惉偡傞偙偲偱偁傝丄惓幃側曬崘偼偝傟偰偄側偄偑丄婛偵10000戜傪払惉偟偰偄傞傕偺偲巚傢傟傞丅
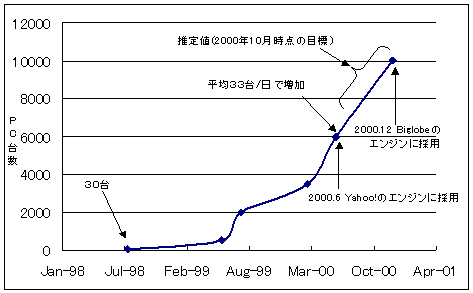
丂Google偵懳偡傞傾僋僙僗悢傕巜悢娭悢揑偵墑傃偰偍傝丄1999擭6寧帪揰偱50枩僸僢僩/擔偱偁偭偨傕偺偑丄2000擭6寧偵偼4000枩僸僢僩/擔偲側偭偰偍傝丄枅寧20乣30亾傾僋僙僗偑憹戝偟偰偄傞丅偙傟偼丄2000擭6寧偵Yahoo!偺僒乕僠僄儞僕儞偲偟偰嵦梡偝傟偨偙偲偑戝偒側梫場偲側偭偰偄傞丅傑偨丄2000擭12寧偵偼NEC偺Biglobe偺僒乕僠僄儞僕儞偲偟偰嵦梡偝傟偰偄傞丅
丂堦曽偱丄Google偑帩偮僨乕僞検傕巜悢娭悢揑偵憹戝偟偰偄傞丅1999擭8寧偵偼俀壄儁乕僕偱偁偭偨傕偺偑丄2000擭3寧偵偼俆壄儁乕僕傊偲憹戝偟丄2001擭2寧偵偼丄NetNews偺専嶕僒僀僩偱偁傞Deja傪攦廂偟怴偨偵俆壄儁乕僕偺僨乕僞傪捛壛偟偨丅偙傟偵傛偭偰丄2001擭2寧枛尰嵼偱偼13.5壄儁乕僕偲側偭偰偄傞丅
丂
丂Google偺媄弍柺傪庢傝巇愗傞Chief Operations Engineer偼丄Jim Reese偱偁傞丅Reese偼丄Harvard戝妛傪懖嬈屻丄Yale
Medical School偺戝妛堾丄Stanford戝妛偱3.5擭偺娫丄恄宱奜壢傪愱栧偲偟偨屻丄Stanford SRI International[10]偱偼擼偺MRI夋憸傪慛柧偵偡傞偨傔偺僐儞僺儏乕僞僜僼僩僂僃傾偺奐敪偵1.5擭廬帠偟偨偲偄偆宱楌傪帩偮丅
丂Reese偼丄堛妛攷巑偱偁傝丄僐儞僺儏乕僞偵偮偄偰偼Stanford帪戙偺撈妛偱偁傞丅SRI帪戙丄Reese偼UNIX Computer偺僐儞僒儖僞儞僩偲偟偰SRI傪偼偠傔昦堾埲奜偱妶桇偟偰偄傞丅偪傚偆偳丄SRI偵棃偰1擭偑偨偭偨偙傠丄Google偺専嶕僗僺乕僪偲惓妋側専嶕寢壥偵旕忢偵姶摦偟丄偙傟偑Google傊偺揮怑傪峫偊傞偒偭偐偗偲側偭偨丅
丂Reese偑Google幮偵棜楌彂傪採弌偟偨嵺丄Google偱偼丄恄宱奜壢偐傜偺墳曞偵屗榝偄丄嵟弶偼嵦梡偡傞偙偲傪峫偊偰偄側偐偭偨丅偦偺屻丄Google偼丄Stanford戝妛偺偮偰傪巊偭偰Reese偑堛妛攷巑偱偁傞偙偲傪妋擣偟偨屻丄揹榖僀儞僞價儏乕傪幚巤偟偨丅偦偺屻偺柺愙偱偼侾帪娫埲忋偵搉傞寖榑偺枛丄Page偲Brin偑Reese偵弌偟偨擄戣[11]偵懳偟偰丄Reese偑夝寛嶔傪帵偟偨偙偲偱丄偦偺応偱嵦梡偑寛掕偟丄柺愙偺梻擔偐傜Reese偼Google幮偵嬑柋偡傞偙偲偵側傞丅
3.9.3.1丂PC+Linux OS嵦梡偺棟桼
丂Google偱偼丄Intel偺CPU傪帩偮PC偲Linux OS偲偄偆僐儌僨傿僥傿壔偟偰偄傞僴乕僪僂僃傾丄僜僼僩僂僃傾偵傛傝丄専嶕僔僗僥儉傪峔抸偟偰偄傞丅偙傟偼丄嘆掅僐僗僩偱偁傞丄嘇僗働乕儖傾僢僾偑壜擻丄偲偄偆俀揰偑棟桼偲側偭偰偄傞丅
丂PC偼偦偺峔惉梫慺偱偁傞CPU,RAM,HD嫟偵擭乆壙奿偑掅壓偟偰偍傝丄壙奿惈擻斾偐傜峫偊偰丄Web偺憹壛偵懳偟偰廩暘偵僗働乕儖偡傞偲敾抐偟偰偄傞丅幚嵺丄僴乕僪僨傿僗僋偺枾搙偼擭棪俀攞埲忋偺墑傃傪帵偟偰偍傝[12]丄Web僨乕僞偑擭棪栺俀攞乮恾3.9-3乯偱憹壛偟偰偄傞偙偲傪峫偊傞偲丄廫暘偵梕検揑偵僗働乕儖偡傞[13]乮恾3.9-4乯丅
|
慜 擭 斾 憹 戝 棪 |
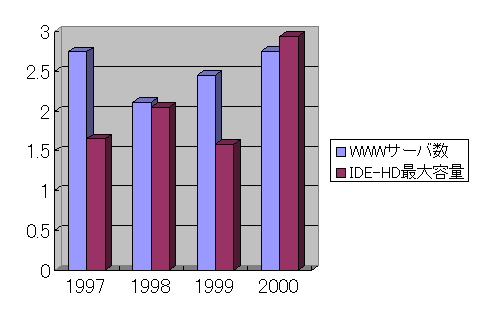 |
|
恾3.9-4丂IDE-HD偺嵟戝梕検偲WWW僒乕僶悢偺枅擭偺憹戝棪 乮倂倂倂僒乕僶悢偼塸崙Netcraft幮敪昞偺僨乕僞丄IDE-HD偺嵟戝梕検偼 暷崙Maxtor幮偑斕攧偡傞IDE-HD偺嵟戝梕検偵傛傝寁嶼乯 |
|
丂
3.9.3.2丂僴乕僪僂僃傾峔惉
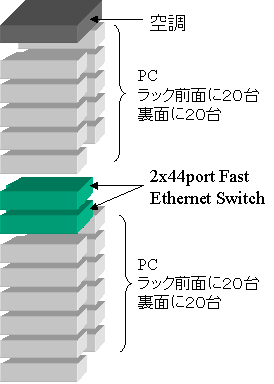
丂Google偱棙梡偟偰偄傞僴乕僪僂僃傾偼丄RAIS(Redundant Arrays of Inexpensive Servers)[14]偵傛傝峔惉偝傟偰偄傞丅19inch儔僢僋(210cmH亊60cmW亊75cmD)偵1U僒僀僘偺PC傪80戜愝抲偟偰偄傞丅捠忢偱偁傟偽44U偺儔僢僋偵偼丄1U僒僀僘偺PC偑44戜偟偐擖傜側偄偑丄Rackable
Systtems[15]偺媄弍傪梡偄傞偙偲偵傛偭偰丄侾儔僢僋偵80戜偺PC偲Network
Switch傪擖傟偰偄傞丅儔僢僋偺昞柺偲棤柺偺椉曽偐傜墱峴偒偑捠忢偺敿暘偺PC傪憓擖偟丄80戜偺PC傪侾儔僢僋偵奿擺偡傞乮恾3.9-5乯丅偨偩偟丄敪擬検偑戝偒偔側傞偨傔嬻挷梡偺僼傽儞傪儔僢僋偺忋晹偵愝抲偟偰偄傞丅奺PC偺峔惉偼丄昞3.9-1偺捠傝偱偁傞丅
丂儔僢僋撪偺80戜偺PC偼丄俀戜偺44億乕僩偺Fast Ethernet Switch偵傛傝愙懕偝傟丄係儔僢僋乮PC320戜乯偱侾僋儔僗僞傪峔惉偡傞丅儔僢僋娫偼丄GigaEther偵傛傝愙懕偝傟傞丅2000擭枛帪揰偱栺31戜偺僋儔僗僞乮PC10,000戜乯偵偼丄慡偔摨堦偺僨乕僞偑奿擺偝傟偰偄傞丅
丂
昞3.9-1丂僋儔僗僞傪峔惉偡傞PC偺峔惉| 俠俹倀 | Intel PentiumIII (僋儘僢僋偼PC摫擖帪婜偵傛偭偰堎側傞) |
| 儊儌儕 | 256MB乣1GB |
| 俢俬俽俲 | 40乣80GB偺DISK俀戜傪1PC偵愙懕[16]乮俀channel棙梡乯 丂- DISK偼丄梕検偺戝偒偄傕偺偵弴師岎姺 |
| 俶俤俿倂俷俼俲 | Intel EtherExpressPro 100 |
| 俷俽 | Red Hat Linux(stripped-down version) 丂- 昗弨distribution偐傜Graphical晹暘傪嶍彍 |
丂
丂2000擭10寧尰嵼丄California偵俀僇強丄Virginia偵侾僇強偺僨乕僞僙儞僞乕傪愝抲偟丄悽奅拞偐傜偺query偺暘嶶傪恾偭偰偄傞丅傑偨丄2001擭3寧乮1Q2001乯傑偱偵傾僕傾偲儓乕儘僢僷偵僨乕僞僙儞僞乕傪捛壛愝抲偟丄専嶕懍搙偲latency偺抁弅傪寁夋偟偰偄傞丅
丂2000擭6寧帪揰偱偺憤DISK梕検偼500TB丄6000PC[17]偱偁傝丄暯嬒33戜/擔偺妱崌偱PC偺憹愝傪峴偭偰偄傞丅傑偨丄2000擭7寧帪揰偱偺憤僨乕僞検偼栺5.6TB(栺5.6壄儁乕僕)偱偁傞偲梊憐偝傟傞[18]丅偡側傢偪丄侾僋儔僗僞乮PC320戜乯撪偵偍偄偰傕栺係廳壔偝傟偨僨乕僞僐僺乕偑懚嵼偟丄栺68乣80戜偺PC偵暘嶶偟偰5.6TB偺僨乕僞傪奿擺偟偰偄傞偲峫偊傜傟傞[19]丅偙偺傛偆偵Google偱偼丄侾偮偺僋儔僗僞撪偱傕摨偠僨乕僞傪廳暋偟偰奿擺偝偣傞偲嫟偵丄僋儔僗僞娫偱偼姰慡側僐僺乕傪帩偮偙偲偵傛偭偰忕挿惈偺偁傞峔惉傪偲傞丅
3.9.3.3丂媄弍払惉栚昗
丂Google偱偼丄奐敪摉弶偐傜0.5s/query偺専嶕僗僺乕僪偲1000queries/s偲偄偆僗働乕儔價儕僥傿傪媄弍払惉栚昗偲偟偨丅2000擭6寧尰嵼丄偙偺栚昗傪払惉偡傞偲嫟偵丄4000枩queries/擔傪偙側偡偨傔偵6000戜偺PC傪梡偄丄20乣30%/寧偺妱崌偱憹壛偡傞queries偵懳墳偡傞偨傔丄暯嬒33戜/擔偺PC傪捛壛偟偰偄傞丅
丂恾3.9-6偵帵偡傛偆偵2000擭7寧偵偼丄Google偼丄偙傟傜偺戝婯柾僋儔僗僞傪梡偄偰5.6壄儁乕僕偺Web僨乕僞廂廤傪峴偄乮偙偺帪揰偱慡Web僨乕僞偺栺18%乯丄悽奅嵟戝偺僨乕僞検傪帩偮丅偦偺屻傕丄2001擭2寧偵偼丄NetNews専嶕僒僀僩偺Deja[20]傪攦廂偟丄NetNews娭楢偺栺5壄偺僨乕僞傪捛壛偟丄2001擭2寧枛尰嵼丄憤僨乕僞梕検偼栺13.5壄儁乕僕偲側偭偰偄傞丅
3.9.3.4丂専嶕婡擻
丂Google偺専嶕婡擻偲偟偰摿挜揑側傕偺偼埲壓偺俆偮偱偁傞丅


3.9.3.4.1丂Page Rank朄
丂徻嵶偼暥專[1][2]傪嶲徠偟偰偄偨偩偔偲偟偰丄偙偙偱偼丄Page Rank朄偺峫偊曽傪徯夘偡傞丅Page Rank朄偼丄Page偲Brin偑Stanford戝妛偺攷巑壽掱偺妛惗帪乮1998.1乯偵丄採埬偟偨庤朄偱偁傞丅Page
Rank朄偱偼丄偁傞儁乕僕A偐傜儁乕僕B偵儕儞僋偑懚嵼偡傞応崌丄儁乕僕B偵懳偟偰儁乕僕A偑堦昜搳偠偰偄傞偲峫偊傞丅偙偺峫偊曽偼1995擭偵Neeraja
Sankaran偵傛偭偰惗暔妛偺僲乕儀儖徿傪庴徿偡傞恖暔傪梊應偡傞庤朄偲偟偰梡偄傜傟偰偍傝丄摿偵怴婯惈偼側偄丅Page Rank朄偺廳梫側揰偼丄儁乕僕A偺廳梫搙偵傛偭偰丄堦昜偺廳傒傪曄偊傞揰偵偁傞丅椺偊偽丄傾僟儖僩僒僀僩摍丄儔儞僋傪忋偘傞偨傔偵暋悢偺僟儈乕僒僀僩偐傜偺儕儞僋傪挘偭偰偄傞応崌偱傕丄偙傟傜偺僟儈乕僒僀僩偺廳傒傪掅偔愝掕偱偒傞[22]偨傔丄屘堄偵儔儞僋傪忋偘傛偆偲儕儞僋傪挘偭偰傕丄儁乕僕A偺儔儞僋傪忋偘傞偙偲偼偱偒側偄丅
丂PageRank偼丄恾3.9-9偵帵偡庤朄偱寁嶼偡傞丅儁乕僕p偺儔儞僋偼丄儁乕僕p傊儕儞僋傪帩偮儁乕僕q偺儔儞僋偺憤榓偱寛掕偝傟傞丅偨偩偟丄儁乕僕q偺儔儞僋偼丄儁乕僕q偑帩偮奜岦偒偺儕儞僋悢乮outdegree(q)乯偱妱偭偨抣偲側傞丅椺偊偽丄HUB宆[23]偺Web儁乕僕偐傜偺儕儞僋偺廳傒偼彫偝偔側傞丅兠偼丄榑暥[1]偵傛傟偽捠忢0.15偵愝掕偟丄懠偐傜壗傕儕儞僋偑側偄僒僀僩偵懳偟偰0.15偺儔儞僋傪梌偊偰偄傞丅

丂PageRank傪媮傔傞偨傔偵丄傑偢丄偳偙偵傕奜晹偺儁乕僕偵懳偟偰儕儞僋傪帩偨側偄Web儁乕僕傪扵偡丅偙傟傜偺儁乕僕偼懠偺Web儁乕僕偺PageRank偵塭嬁傪梌偊側偄偨傔丄PageRank寁嶼忋丄寁嶼傪徣偔偙偲偑偱偒傞丅偦偺屻丄奺儁乕僕偺弶婜儔儞僋傪寛傔丄恾3.9-9偺幃偵傛傝奺Web儁乕僕偺儔儞僋傪峏怴偡傞丅幚尡偱偼丄3.2壄偺儁乕僕偵懳偡傞Page Rank朄揔梡帪丄栺52夞偺孞傝曉偟偵傛傝丄弶婜抣偑嵟廔抣偵塭嬁傪梌偊側偄掱搙偵廂懇偱偒偨偲曬崘偟偰偄傞丅
3.9.3.5丂僼僅儖僩僩儗儔儞僩懳嶔
丂Google偱偼丄愭偵傕弎傋偨傛偆偵壓婰偵嫇偘傞屘忈帪懳嶔傪偲傞丅
丂偝傜偵丄岠棪偺傛偄晧壸暘嶶傪幚尰偡傞偨傔偵丄Pythonscript[24]傪梡偄偰僷僼僅乕儅儞僗儌僯僞乕傪撈帺偵峔抸偡傞偲嫟偵丄Custom
load-balancing software傪奐敪偟丄嵟彫晧壸偺PC傪慖戰偡傞偡傞偙偲傪帋傒偰偄傞[25]丅
丂側偍丄崱屻偺壽戣偲偟偰丄壓婰偺係崁栚傪嫇偘偰偄傞丅
丂乮侾乯System Image Consistent
丂乮俀乯Monitering System State
丂乮俁乯Debugging Performance Problems
丂乮係乯Bits Error on copying terabytes
丂戝梕検偺僨乕僞傪懡廳壔偟朿戝側悢偺PC偵奿擺偟偰偍傝丄偦偺僨乕僞偺惍崌惈傪偳偺傛偆偵偟偰偲傞偐乮侾乯丄朿戝側悢偺PC偺壱摥忬嫷傪偳偺傛偆偵偟偰岠棪傛偔庢摼偡傞偐乮俀乯丄晧壸暘嶶傪偳偺傛偆偵岠棪壔偡傞偐乮俁乯丄TB僆乕僟乕偺僨乕僞傪埖偆偨傔丄僨傿僗僋丄儊儌儕偺偁傜備傞売強偱偺bit error傪旔偗傞偙偲偼妋棪忋崲擄偲側偭偰偍傝丄偳偺傛偆側懳嶔傪偲傞傋偒偐乮係乯偺係崁栚偱偁傞丅
3.9.3.6丂僙僉儏儕僥傿懳嶔
丂Google偼丄OS偵Linux乮Red Hat Linux乯傪嵦梡偟偰偄傞偑屘偵丄乮僜乕僗偑岞奐偝傟偰偄側偄乯彜梡Unix偵斾妑偟丄僙僉儏儕僥傿儗儀儖偑崅偄偲偄偆棫応傪偲傞丅偙傟偼丄昁偢偟傕惓偟偄偲偼尵偊側偄偑丄Reese偼Linux偺security偵娭偡傞儊乕儕儞僌儕僗僩偱悢乆偺敪尵傪偟偰偍傝丄Reese帺恎偑Linux偺僙僉儏儕僥傿懳嶔偵旕忢偵徻偟偔帺恎傪帩偭偰偄傞偙偲偑棟夝偱偒傞丅
丂
丂2000擭枛帪揰偱偺Google偺幮堳偼昐悢廫柤偱偁傝丄僔僗僥儉偺儊儞僥僫儞僗摍傪峫偊傞偲丄岠棪偺傛偄塣梡偑惉岟偡傞尞[26]偱偁傞偲峫偊傜傟傞丅偙偺偨傔丄Google偱偼丄壓婰偵帵偡傛偆偵丄僒乕僠僄儞僕儞偺婡擻傪堦妵偟偰婜娫棙梡宊栺偡傞偙偲偵傛傝丄僆乕僶僿僢僪偑彮側偄埨掕偟偨廂擖傪摼傞偙偲傪峫偊偰偄傞丅
| (傾) | 僥僉僗僩 | |
| 丂 | 嘆 | 峀崘奺専嶕偵懳偟俀峴偺僥僉僗僩峀崘傪採嫙偡傞丅 |
| 丂 | 嘇 | Yahoo!摍偺僒僀僩偱偼丄僶僫乕峀崘偵旕忢偵鉟楉側夋憸傪弌偟偨傝丄億僢僾傾僢僾儊僯儏乕丄傾僯儊乕僔儑儞摍傪懡梡偟偰偄傞丅偟偐偟丄Google偱偼丄俀峴偺僥僉僗僩峀崘傪嵦梡偡傞偙偲偱丄儐乕僓偑堦斒揑偵姶偠傞乽僶僫乕峀崘傪昞帵偡傞偑屘偵丄専嶕寢壥偺昞帵偑抶偄乿偲偄偭偨栤戣傪夝寛偟偰偄傞丅 |
 |
||
| 丂 |
嘊 |
偨偩偟丄慡偰偺専嶕偺寢壥偵峀崘偑昞帵偝傟傞偺偱偼側偔丄摿掕偺専嶕傪峴偭偨応崌偺傒偵峀崘偑昞帵偝傟傞巇慻傪偲傞丅 |
| 丂 | 嘋 | Google偱偼丄堦斒揑側僆儞儔僀儞峀崘偺僋儕僢僋僗儖乕儗乕僩偺栺係攞傪払惉偟偰偄傞[27]丅 |
| (僀) | 摿掕偺Web僒僀僩傪懳徾偲偟偨僒乕僠僄儞僕儞採嫙 | |
| 丂 | 嘆 | Cisco, Washington Post, Virgin Net, Netscape NetCenter, RedHat摍 |
| (僂) | Web僒僀僩傪尷掕偟側偄僒乕僠僄儞僕儞採嫙 | |
| 丂 | 嘆 | 2000擭6寧丂Yahoo!偺僒乕僠僄儞僕儞偵嵦梡 |
| 丂 | 嘇 | 2000擭12寧丂NEC偺Biglobe偺僒乕僠僄儞僕儞偵嵦梡 |
丂
丂埲忋弎傋偨傛偆偵丄Google抋惗丒惉挿偺億僀儞僩偲偟偰廳梫側揰偲偟偰丄壓婰偺俁偮偑嫇偘傜傟傞丅
丂崱屻傕Google偑惉挿傪懕偗傜傟傞偐偳偆偐傪梊應偡傞偙偲偼崲擄偱偁傞偑丄彮側偔偲傕媄弍揑偵懠偺僒乕僠僄儞僕儞偲偺嵎堎傪曐偮偙偲偑偱偒傞尷傝丄Google偺懚嵼壙抣偼偁傞丅
丂偝傜偵丄嫄戝僋儔僗僞僔僗僥儉偼丄崱傗悽奅拞偺偳偙傪扵偟偰傕懚嵼偟側偄婯柾偵側偭偰偍傝丄悽奅嵟戝偺僋儔僗僞僔僗僥儉傪帩偮偙偲偲丄悽奅嵟戝偺Web僨乕僞偺拁愊偐傜摼傜傟傞條乆側僲僂僴僂偺拁愊偼丄師偺價僕僱僗傊偲揥奐偟偰偄偔偨傔偺僄僱儖僊乕偲側傞偙偲偼娫堘偄側偄偲巚傢傟傞丅
丂
嶲峫暥專
丂杮曬崘偼丄庡偲偟偰壓婰偵帵偡榑暥媦傃僀儞僞乕僱僢僩忋偺忣曬傪忣曬尮偲偟偨丅
PageRank偵娭偡傞榑暥
[1] S.Brin and L.Page: 乬The anatomy of large-scale hypertextual Web search
engine乭, Proc. of the 7th International World Wide Web Conf. 1998,
pp.107-117 (1998)
[2] L.Page, S.Brin,R.Motwani, and T.Winograd: 乬The PageRank citation ranking : Bringing Order to the Web乭, Stanford Digital Library Technologies, Working Paper 1999-0120 (1998)
Google Press Release
[3] Googles乫s Targeted Keyword Ad Program Shows Strong Momentum with Advertisers
(2000.8.16)
丂丂丂http://www.google.com/press/pressrel/pressrelease31.html
奺庬徯夘婰帠
[4] Searh Us, Says Google (2000.11)
丂丂丂http://www.techreview.com/articles/nov00/qa.htm
[5] Google Searches Made Snappy丂
丂丂丂http://www.intel.com/ebusiness/casestudies/snapsots/google_p.htm
[6] Google Relies Exculusively on Linux Platform to Chun Along
丂丂丂http://www.interex.org/hpworldnews/hpw009/02nt.html
[5] Larry Page,Sergey Brin嫟偵2000擭11寧尰嵼偱27嵨偱偁傝丄25嵨偺帪偵婲嬈偟偨丅
[6] Brin偼儘僔傾惗傑傟丅NSF偺Graduate Fellowship傪庼梌偝傟偰偄傞丅
[8] Sun Micosystems幮偺co-founders偱偁傝丄Stanford戝妛弌恎丅
[9] 偙傟傜擇戝VC偼丄Apple, Amazon.com, Cisco Systems, Netscape, Yahoo!傊傕嫄妟偺弌帒傪峴偭偰偄傞丅
[11] 摉帪丄Google偑捈柺偟偰偄偨栤戣偱Page傕Reese傕夝寛偱偒側偐偭偨栤戣丅
[12] 椺偊偽ASET偑採嫙偡傞僨乕僞(http://www.aset.or.jp/seika_hdd_index.html)傪嶲徠丅
[13] 2000擭枛帪揰偱偺IDE僨傿僗僋偺嵟戝梕検偼Maxtor幮偺80GB偱偁傞丅
[14] RAID偲摨偠峫偊曽偱偁傝丄乽埨偄PC傪暲傋偰忕挿惈傪傕偨偣偨僒乕僶乿偲偄偆堄枴丅
[16] 2000擭6寧偵Google偼3000戜偺IDE40GB(DiamondMax Plus40)傪Maxtor幮傛傝摫擖丅
[17] 暯嬒偡傞偲侾戜偺PC偵40GB偺DISK偑俀戜愝抲偝傟偰偄傞偙偲偵側傞丅
[18] 昅幰偺悇應乮Web儁乕僕偺暯嬒梕検傪10KB偱姺嶼乯丅
[19] 昅幰偺悇應丅
[21] 変偑崙偱偼丄Proxy摍偱堦帪揑偵Web儁乕僕傪僉儍僢僔儏偡傞偙偲偼嫋偝傟偰偄傞偑乮暥壔挕乯丄Web儁乕僕傪僒乕僠僄儞僕儞偺専嶕寢壥偲偟偰尒偣傞偨傔偵僉儍僢僔儏偡傞偙偲偑嫋偝傟傞偐偳偆偐偵偮偄偰偼丄柧傜偐偵側偭偰偄側偄丅
[22] 偙傟傜偺僟儈乕僒僀僩傊偺儕儞僋偼柍偔丄帺摦揑偵廳傒偑壓偑傞丅
[23] 偁傞Web儁乕僕偺backlink(奜偐傜偺儕儞僋)偲forwadlink乮奜傊偺儕儞僋乯偺悢傪斾妑偟偨嵺丄backlink悢亙forwardlink悢偺帪丄HUB宆偺Web儁乕僕偲屇傇丅偙傟偵懳偟偰丄backlink悢亜forwardlink悢偺帪丄Authority宆偺Web儁乕僕偲屇傇丅椺偊偽儕儞僋廤偼丄HUB宆偺Web儁乕僕偱偁傞丅
[24] 僆僽僕僃僋僩巜岦僾儘僌儔儈儞僌偺偱偒傞旕忢偵廮擃惈偺崅偄僗僋儕僾僩尵岅(http://www.python.org)
[25] 巆擮側偑傜嬶懱揑側媄弍偵偮偄偰偼岞奐偝傟偰偄側偄丅
[26] 昅幰偺悇掕丅
[27]2000擭8寧16擔偵奐嵜偝傟偨Jupiter Online Advertising Forum(at NewYork)偱Google Inc.偑敪昞偟偨撪梕偵婎偯偔丅