�}3.7-1�@�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�V�X�e���̍\��
�@
�}3.7-2�@�A�m�e�[�V�����ɂ��WWW �̊g��
�@
�@
�@���̃g�����X�R�[�f�B���O������ɐi�߂āA�e�L�X�g�̗v��Ȃǂ̓��e�Ɋ�Â������̐��x�����߂�H�v�荞�̂��A�M�҂̒�Ă���Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�ł���[8]�B��̓I�ɂ́A�R���e���c�Ɋ܂܂��e�L�X�g���v�f�Ɍ���I�ȕt�����i�A�m�e�[�V�����j�������邱�Ƃɂ���āA�v���|��Ȃǂ̎��R���ꏈ���̐��x��傫�����コ���邱�Ƃ��ł���B���Ƃ��A�t�������g���ăR���e���c�Ɋ܂܂��e�L�X�g���̞B�������y������ƁA���m�ȗv���|���҂ł���B�R���e���c�ɃA�m�e�[�V������t�����Ԃ��������A�d�v�ȏ��̓A�m�e�[�V���������Đ���������`���A���L���ׂ��Ƃ����l���Ɋ�Â��Ă���B���̃A�m�e�[�V�����̓R���e���c�̓��e�����𑣐i������̂ƈʒu�t������B���݁A�M�҂�͌����҂��܂ޑ����̐l�X�������̓��e�Ɋւ���⑫�I����t���ł���悤�Șg�g�ݍ���A���̏����������ĕ�����ǎ҂ɓK�����`�ɉ��H����d�g�ݍ��Ɏ��g��ł���B�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�́A��{�I�Ƀe�L�X�g�R���e���c�̏����𒆐S�Ƃ������̂ł��邪�A���̎�@�͉f����摜�Ȃǂ̔�e�L�X�g�R���e���c�̉��H�ɂ����p����A�}���`���f�B�A�E�f�[�^���܂ރR���e���c�ɓK�p�ł���B
�@�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�́A���[�U���w�肵��Web ��̐V���L���Ȃǂ̃R���e���c��C�ӂ̈��k���ŗv�ĕ\��������A�e���r�ԑg�Ȃǂ̉f���f�[�^���烆�[�U�̍D�݂ɉ������b�肾�����o���āA�_�C�W�F�X�g�f�����쐬����Ƃ��������Ƃ��\�ɂ���B����ɁA�v���R���e���c��|����A�e�L�X�g�����������Ē������Ƃ��ł���B
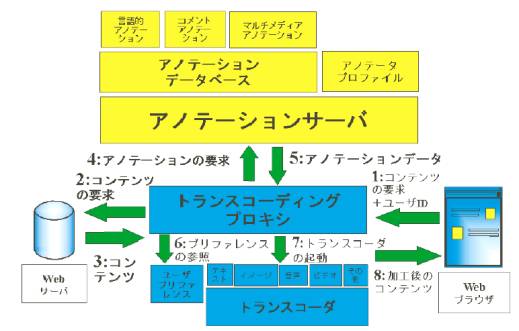
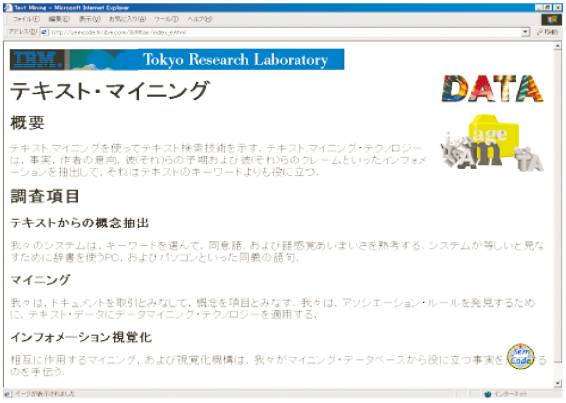
�@�}3.7-1�̓Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�V�X�e���̍\����\���Ă���B�R���e���c�T�[�o�ɂ����ꂽ�e�L�X�g�A�摜�A�����A�f���Ȃǂ̃R���e���c�̓g�����X�R�[�f�B���O�v���L�V�ɂ���āA���[�U�̎g�p����f�o�C�X�i�p�\�R���A�g�ѓd�b�A�J�[�i�r�Ȃǁj��A���[�U�̗v��(�T�v�����݂����A�ꍑ��œǂ݂����A���ŕ��������A�Ȃ�)�ɍ��킹�ĉ��H�����B���̂Ƃ��A�A�m�e�[�V�����ƌĂ��t������p���āA��萸�x�̍����v��E�|����s�Ȃ��B�A�m�e�[�V�����̓A�m�e�[�V�����T�[�o�ɒ~�����Ă���B
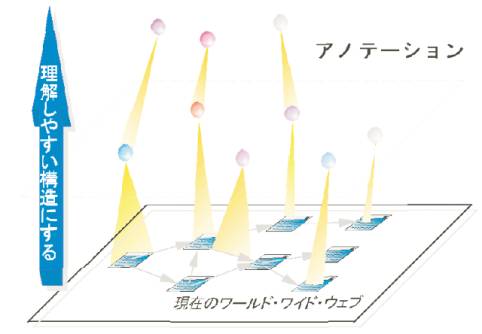
�@�}3.7-2�Ŏ������悤�ɁA�A�m�e�[�V�����́A���݂�Web�ɏ�ʍ\��������ՂɂȂ�B���݂�Web�R���e���c���ʼn��w�ŁA�A�m�e�[�V�����̓R���e���c�ɏ���t�������郁�^�i��ʁj�R���e���c�A����Ƀ��^�R���e���c�ɑ��郁�^�R���e���c�̂悤�ɊK�w���Ȃ��Ă���B
�@�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�̎�@���g���āA��̓I�ɂ�HTML�����Ȃǂ�Web�R���e���c��������A�ȉ���3�̉ۑ�������ł��邾�낤�B
�@
�@�����ł̃A�m�e�[�V�����ɂ́A�傫��������3�̎�ނ�����B�e�L�X�g���̌���\���Ȃǂ�t�^���錾��I�A�m�e�[�V�����A�摜��n�C�p�[�����N�Ȃǂ̃R���e���c���\������e�v�f�ɑ���R�����g�E�A�m�e�[�V�����A�r�f�I�f���Ȃǃ}���`���f�B�A�E�f�[�^�̈Ӗ��I�\�����L�q���邽�߂̃}���`���f�B�A�E�A�m�e�[�V����������B��̓I�ȉ��p��Ƃ��ẮAWeb�y�[�W�̗v���|��A���C�A�E�g�ϊ��A�������e�L�X�g��e�L�X�g�������Ƃ������ϊ��A�f������v���f���ւ̕ϊ��Ȃǂ���������B����ɁA�����̃R���e���c���烆�[�U�̍D�݂ɍ������V�K�̃R���e���c������Ƃ��������p������ɓ����Ă���B���ۂɃA�m�e�[�V������t�^�����@�́A�R���e���c�̎�ނɂ���ĈقȂ�B
�@
�@
�@
3.7.3.1�@�A�m�e�[�V�����G�f�B�^
�@�R���e���c�Ɍ����ǂ��A�m�e�[�V��������t�����邽�߂ɁA�M�҂�̓A�m�e�[�V�����G�f�B�^�ƌĂ��I�[�T�����O�c�[�����J�����Ă���B������A�m�e�[�V�����f�[�^�̎���������ҏW�ɗp����B�A�m�e�[�V�����G�f�B�^��Java�A�v���P�[�V�����Ƃ��ă��[�U���̃N���C�A���g��ŗ��p�ł���B���������A�m�e�[�V�����f�[�^�́A�A�m�e�[�V�����T�[�o�֑��M����A���ށ^�i�[�����B�A�m�e�[�V�����f�[�^�̋L�q�ɂ́AXML��p����B�A�m�e�[�V�����f�[�^���L�q����Web�y�[�W���X�V���ꂽ�ꍇ�A�X�V�O�̃A�m�e�[�V�����f�[�^�̍ė��p��}��[4]�B�X�V�O�̃A�m�e�[�V�����f�[�^���Q�Ƃ��Ȃ���A�X�V��̃A�m�e�[�V�����f�[�^�̍č\�������݂�悤�Ȏd�g�݂������ꂽ�B
�@���̃G�f�B�^���g���āA���[�U�͌���\��(�\����Ӗ��Ɋւ���\��)�Ɋւ���A�m�e�[�V�������e�L�X�g���ɕt��������A�R���e���c���̉摜�≹���Ƃ������v�f�ɃR�����g��t�����肷�邱�Ƃ��ł���B����\���Ɋւ���A�m�e�[�V�����͎��������ł���B�������A���̍\���ɞB�������܂܂��ꍇ�́A���[�U���A�m�e�[�V�����G�f�B�^�𑀍삵�ďC������B����\���̕\���́A�c���[��ɕ\�����Ă��̍\�����c�����₷���悤�ɍH�v�����B
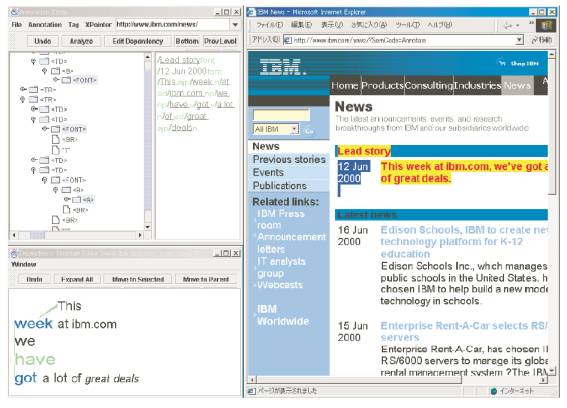
�@�}3.7-3�́A�A�m�e�[�V�����G�f�B�^�̉�ʗ�ł���B����́A�e�L�X�g�Ɋ܂܂�錾��\����������͂��A���̌��ʂ��C������c�[���ł���B����\�����r�W���A�������ĕ\�����A�ȒP�ȃ}�E�X����ŁA�C���ł���B���̑��̋@�\�Ƃ��āAHTML�����̔C�ӂ̃^�O�v�f�ɃR�����g����t��������@�\������B
�@����ɁA�����̓R���e���c�̌����҂��A�m�e�[�V�����𐧌䂷����@���J�����Ă���B�����҂������̃R���e���c�ɑ����̃A�m�e�[�V�����������Ȃ��ꍇ�A�R���e���c���ɃA�m�e�[�V�����������Ȃ��Ƃ����L�q�����邱�Ƃɂ���āA�A�m�e�[�V�����T�[�o�������F�����A�A�m�e�[�V�����G�f�B�^����̗v�������Ă����ۂ���悤�Ȏd�g�݂ɂȂ��Ă���B
3.7.3.2�@����I�A�m�e�[�V�����ƃe�L�X�g�E�g�����X�R�[�f�B���O
�@�e�L�X�g�����̃g�����X�R�[�f�B���O�Ƃ́A����I�A�m�e�[�V������p�����e�L�X�g�����̉��H���w���B����I�A�m�e�[�V�����́A�C��-��C���W�Ƃ���������\����ŗL�����A�����Ƃ������Ӗ��t�����R���e���c�ɗ^���邽�߂Ɏg���B��̓I�ɂ́AXML�`���̃^�O���g���Č���\����Ӗ��t������ƂȂ�R���e���c�ɕt������B
�@����I�A�m�e�[�V�����́A�R���e���c�Ɋ܂܂��e�L�X�g���̌���\���Ɋւ���A�m�e�[�V�����ł���B��Ԃ̌W���㖼���̎w���ΏہA���`��̈Ӗ��Ƃ������ڍׂȏ����܂ށB���̌���I�A�m�e�[�V�����́A�h�L�������g�̓��e�����ɑ傫���v�����A�e�L�X�g���̃g�����X�R�[�f�B���O�ȊO�ɂ��A���Ƃ��A���e������m�������Ȃǂɂ����p�ł���B
�@����I�A�m�e�[�V�����̋L�q�`���Ƃ��āAGDA�iGlobal Document Annotation�j�ƌĂ����̂�����[2]�B����́AXML�`���̃^�O�𗘗p���āA�����̓���E�Ӗ��E�k�b�\������������̂ł���BGDA�^�O�t���h�L�������g�́A���Ƃ��Έȉ��̂悤�Ȃ��̂ł���B
�@�����͓���\����\�킵�Ă���A�e�G�������g(�^�O�ň͂܂ꂽ����)�͓���I�\���f�ł���B�����ŁA<su>�͈ꕶ�͈̔͂�\���A<n>,
<np>, <vp>,<adp>, <namep>�́A���ꂼ�ꖼ���A������A������A�`�e����/�`�e������(�O�u����A��u������܂�)�A�ŗL�������\���Bsyn="p"�͓��ʍ\���i���Ƃ��Ώ�́u�`�����`�q�Ɓ`����}����`�q�v�j��\�킷�B���ʍ\���̒�`�́A�W��W�����L����Ƃ������Ƃł���B���ɉ����w�肪�Ȃ��ꍇ�́A���Ƃ��A<np><adp
rel="x">A</adp><n>B</n> </np>��A��B�Ɉˑ��W�����邱�Ƃ�\���B�܂��Arel="x"��<adp>�G�������g�̊W������\���Ă���B�܂��Asense="*"�͌�`������\���Ă���i�����l�Ƃ��ẮA���Ƃ���EDR�P�ꎫ��[5]�̊T�O���ʎq�����p�ł���B�܂��A��ꂪ�����̌�`�����ꍇ�́A�����l�������ɂȂ�j�B
�@���̌`����p���āA�e�L�X�g�����̗v���|�����������B���Ƃ��A���̃^�O���g�����v��̃A���S���Y���͈ȉ��̂悤�ɂȂ�[9]�B
| �@ | �v�f�Ƃ��̎Q�Ɨv�f�̊Ԃŏd�v�x���������Ȃ�A����ȊO�ł͏d�v�x����������悤�ɏd�v�x�̌v�Z(�����g�U)�����s����B |
| �A | �d�v�x�̊g�U���Z���I���������_�ŁA���Ϗd�v�x�̑傫�����ɕ���I������B |
| �B | �I�����ꂽ���ō폜����ƈӖ����ʂ�Ȃ��K�{�v�f�𒊏o����B |
| �C | ���̕K�{�v�f���Ȃ��ĕ��̍��i�����A�v��ɉ�����B�㖼���Ȃǂ̎Q�ƕ\���̐�s�����v��Ɋ܂܂�Ȃ��ꍇ�͎Q�ƕ\�����s���Œu��������B |
| �D | �v�w�肳�ꂽ���ʂɒB�����Ƃ��͏I������B�܂��]�T������ꍇ�́A���ɏd�v�x�̍������Əȗ������v�f�̏d�v�x���r���āA��������v��ɉ�����B |
�@�K�{�v�f�ɂȂ蓾��v�f�́A�傫��������3����B��͗v�f�̎厫�ł���B�厫�Ƃ́A�ق��̗v�f�Ɉˑ����Ȃ����S�ƂȂ�v�f�ł���B������͓��e�A�����A�����A���Ȃǂ̊W���������v�f�ŁA���Ƃ��A����ړI��Ȃǂ����Ă͂܂�B�ق��ɁA���ʍ\�����K�{�v�f�̏ꍇ�́A����ɒ��ڊ܂܂��v�f���K�{�v�f�ɂȂ�B���ʍ\���Ƃ́A���Ƃ��Γ�̗v�fA�Ɨv�fB���AAND
���邢��OR�̊W�Ō���Ă���\�����w���B���ʍ\���̗v�f�̂�����������폜���Ă����̈Ӗ����ς���Ă��܂��B
�@����̎�@�ł́A����̌l�̎��n�D�ɂ��_��ɍ��킹�Ĉ�A�̏��������s���邱�Ƃ��\�ł���B���ۂɍ���J�������V�X�e���ł́A�v����J�n���鎞�_�Ń��[�U���C�ӂ̃L�[���[�h����͂��Ěn�D�⋻���f�ł���悤�ɂ����B���[�U�����͂����L�[���[�h�Ɗ֘A����P����d�v��Ƃ��ď�������B�d�v����܂ޗv�f�͏d�v�x�̏����l�����Ȃ�傫�����B���̂����ŏd�v�x�̊g�U���Z���s�Ȃ��B����ɁA����̃V�X�e���ł́A���[�U�̎��n�D�̊w�K�@�\�����荞�B�L�[���[�h�ݒ�̍s�������ɉ����āA�R���e���c�Ɋ܂܂��v�f�̏d�v�x�����߂�B����ɂ���āA�v��V�X�e���͓��Ƀ��[�U����̓��͂��Ȃ��Ă��A���̌�A���[�U�ɓ��������v������邱�Ƃ��ł���B���̂ق��A�e�L�X�g�����̃g�����X�R�[�f�B���O�̗�Ƃ��Ă͖|��������B���݁A�p�ꂩ����{��A����щp�ꂩ�烈�[���b�p����(�h�C�c��A�t�����X��A�X�y�C����A�C�^���A��)�̎����|����g�����X�R�[�f�B���O�Ƃ��Ď������Ă���B����A�p���|��Ɋւ��ẮA���{�A�C�E�r�[�E�G�����J�������|��G���W�����g�p���Ă���B���Ђ̃p�\�R�������|��\�t�g�E�F�A�u�C���^�[�l�b�g�|��̉��l�v�̖|��G���W�����A�A�m�e�[�V�������l�����Ė|��悤�Ɋg�������B�|��ŗp���錾��I�A�m�e�[�V������IBM
������b���������J������LAL�iLinguistic Annotation Language�j�Ɋ�Â��Ă���[15, 16]�B�|�̃g�����X�R�[�f�B���O�ł́A�A�m�e�[�V�����f�[�^��GDA
����LAL �֎����I�ɕϊ����Ă���|��G���W���ɓn���Ă���B
�@LAL �`���̕��́A���Ƃ��Έȉ��̂悤�Ȃ��̂ł���(mod �͌W�����Apos �͕i����\��)�B
�@�}3.7-4(a)�͊�ƂȂ�R���e���c�ł���A�v��E�|�����ʂ�(b)�ł���B
�@�|��G���W���ɂ����̑����̕����́A��Ԃ̌W���͂̎��s��A���`��̖��I���̎��s�ɂ��B�W����`���������A�m�e�[�V�������R���e���c�ɕt�����邱�Ƃɂ���āA�|�x�̉��P�������߂�B�����I�ɂ̓R���e���c�̍�҂́A�g�����X�R�[�f�B���O�ɂ���Č����������̂�h�����߂ɁA�ϋɓI�ɃA�m�e�[�V������t����悤�ɂȂ邾�낤�B
�@�߂������AWeb�R���e���c��ꍑ��ł����\�����Ă��Ȃ��l�X���A�g�����X�R�[�f�B���O�ɂ���Ă��܂��܂Ȍ��ꌗ�̐l�X�ɏ�M�ł���悤�ɂȂ邾�낤�B
�@�܂��A�ǎ҂̗���x�ɍ��킹�Đ��I�ȕ\��������ʓI�ȕ\���ɏ��������āA�킩��₷�����͂ɂ���A�p���t���[�Y�E�g�����X�R�[�f�B���O�ɂ��Ă�������i�߂Ă���B
3.7.3.3�@�R�����g�E�A�m�e�[�V�����Ɖ����g�����X�R�[�f�B���O
�@�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�V�X�e���́A�e�L�X�g���Ȃǂ̃R���e���c�����������ɂ���āA�����ɕϊ����邱�Ƃ��ł���B�e�L�X�g�������łȂ��A�摜�ƃe�L�X�g�������݂���R���e���c�̏ꍇ�A�摜�̐����ɂ�����R�����g�E�A�m�e�[�V������p���邱�Ƃɂ���āA��e�L�X�g�v�f���܂߂ĉ��������邱�Ƃ��ł���B����ɌŗL�����ȂǁA�������ǂݕ������������p�̎����ɖ����ꍇ������I�A�m�e�[�V�����ɂ���āA�ǂݕ����w�肷�邱�Ƃ��ł���B
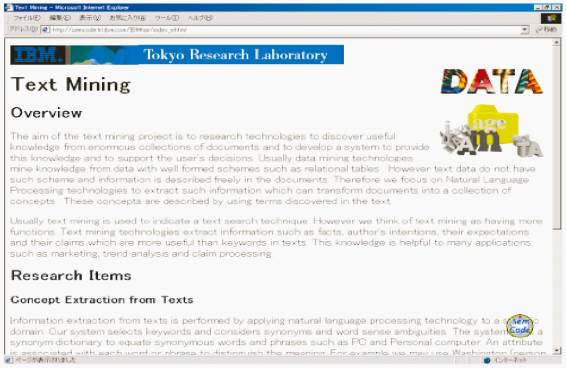
�@�}3.7-5 �́AWeb �y�[�W�̉����g�����X�R�[�f�B���O�̌��ʂ������Ă���B���������s�Ȃ���MP3�iMPEG-1Audio Layer 3�j�f�[�^����������A�Y�����镔���ɃA�C�R�����}������A�����N�����B�u���E�U��ł��̃A�C�R�����N���b�N����ƃv���C�����N�����ĉ������Đ������B
�@�R�����g�E�A�m�e�[�V�����́A��ɔ�e�L�X�g�v�f�ɑ���C�ӂ̃R�����g���܂ރA�m�e�[�V�����ł���B�R�����g�̓e�L�X�g�������łȂ��A�摜��n�C�p�[�����N�Ȃǂ��܂ނ��Ƃ��ł���B���Ƃ��A�R�����g�E�A�m�e�[�V�������܂摜���}�E�X�E�|�C���^�Ŏw���ƁA���̉摜�̐����E�B���h�E���|�b�v�A�b�v���ĕ\�������B���邢�͉摜�ƃe�L�X�g���܂ރR���e���c�S�̂����������œǂݏグ���ꍇ�A�摜�����Ɋւ��Ă̓R�����g�E�A�m�e�[�V�������Q�l�ɂ��ĉ���������B�R�����g�E�A�m�e�[�V�����͈ȑO���猤�����s�Ȃ��Ă���B���Ƃ��A�R�����g���Ǘ�����T�[�o�ƁA�R���e���c�ɃR�����g�������ĉ��H����v���L�V��ʌɗp�ӂ���Ƃ������̂ł���[10,
11]�B����̓R���e���c�����L����O���[�v���A�R���e���c�Ɋւ���⑫�������ʓI�ɋ��L�ł���悤�ɔz���������̂ł���B��{�I�ɂ́A�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�̘g�g�݂�����Ɠ��l�ł���B�������A�R�����g��t�^����P�ʂ��R���e���c�S�̂ł͂Ȃ��A�C�ӂ�HTML�̗v�f�ɑ��čs�Ȃ���B�R�����g�͂����ǂސl�Ԃ̂��߂ł���Ɠ����ɁA���̃R���e���c���@�B���������ēK�Ƀg�����X�R�[�h���邽�߂̎�i�Ƃ��đ����Ă���B
�@���ۂɃR���e���c�������ɕϊ����ă��[�U�ɔz�M����ɂ�2 ��ނ̕��@�����邾�낤�B��̓g�����X�R�[�f�B���O��S������O���T�[�o�������f�[�^���쐬���ăN���C�A���g�ɔz�M������@�ł���B�N���C�A���g�����������@�\�������Ȃ��ꍇ�ɗL���ł���B���Ƃ��A�g�ѓd�b����Web�y�[�W�ɃA�N�Z�X����Ƃ��Ɏg���B������́A���������V�X�e����������N���C�A���g�ɉ��H�����e�L�X�g�f�[�^��z�M������@�ł���B���̏ꍇ�A���������ɓK�����`���ɃR���e���c���g�����X�R�[�f�B���O���邱�ƂɂȂ邾�낤�BMP3�̃f�R�[�_���������ꂽ�g�ѓd�b�����������悤�ɂȂ����B����A�z�M���ꂽ�����f�[�^���g�ѓd�b�ɕۑ����āA���[�U�̓s���̗ǂ��Ƃ��ɕ����Ƃ������g����������ɂȂ�Ǝv����B
�@
�@
3.7.3.4�@�C���[�W�E�g�����X�R�[�f�B���O
�@�摜�̃g�����X�R�[�f�B���O�́A���[�U���g�p����@��̕\���\�͂Ȃǂɍ��킹�ăR���e���c�Ɋ܂܂��摜�̃T�C�Y��𑜓x��ϊ����鏈���ł���B����̃V�X�e���ł́A�ϊ����ꂽ�摜�͕K����ƂȂ�摜�ւ̃����N���܂ނ悤�ɂ����B�g�����X�R�[�f�B���O�O�̃T�C�Y��𑜓x�Ō������Ƃ��́A�P�ɂ��̉摜���N���b�N����Ί�̉摜�������B����A�摜�̃g�����X�R�[�f�B���O�ƃe�L�X�g�̃g�����X�R�[�f�B���O�p���āA���[�U�̍D�݂ɉ����āA�摜�ƕ����̕\���o�����X��ς�����悤�ɂ����B�\������v��̕��ʂ�A�摜�ƕ����̕\���o�����X�͐ݒ�E�B���h�E�Œ����ł���B
3.7.3.5�@�}���`���f�B�A�E�A�m�e�[�V�����ƃr�f�I�E�g�����X�R�[�f�B���O
�@�f���R���e���c���g�����X�R�[�f�B���O����ꍇ�A�܂��f���R���e���c�Ɋ܂܂�鉹���̃g�����X�N���v�g(�����N�������e�L�X�g��)��p�ӂ���B���̃g�����X�X�N���v�g�ɁA�Ӗ��\����A�V�[���̕ς��ڂ̃^�C���R�[�h�A�V�[�����Ƃ̃L�[�E�t���[���̈ʒu�A�f���̊e�V�[���ɓo�ꂷ��I�u�W�F�N�g�̖��O�Ƃ��̏o���ʒu(���Ԃƍ��W)�Ȃǂ��A�m�e�[�V�����Ƃ��ĕt������B
�@�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�V�X�e���ł́A�g�����X�N���v�g�������I�ɐ������āA�������I�ɃA�m�e�[�V�������쐬�ł���B�f���̃V�[���̕ς��ڂ������F�����A�V�[���Ɋւ���^�O�t�����x������B
�@���̃V�X�e���́A���݂̂Ƃ���A�f���R���e���c�̗v��̐����A�f���R���e���c����e�L�X�g�Ɖ摜����Ȃ�R���e���c�ւ̍č\����A�r�f�I�����̖|��Ȃǂ������ł���B
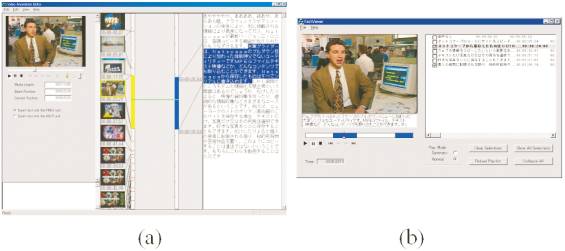
�@�}3.7-6(a)�̓r�f�I�A�m�e�[�V�����G�f�B�^�̉�ʗ�������Ă���B���̃G�f�B�^�́A�r�f�I�̃V�[���ւ̕����Ɖ��������̃e�L�X�g�����s�Ȃ��B���������̌��ʂ̓C���^���N�e�B�u�ɏC���ł���B(b)�̓r�f�I�̃A�m�e�[�V�����Ɋ�Â��č쐬�����v��r�f�I���Đ�����v���C���̉�ʗ�ł���B�v��r�f�I���[�h�ł́A�v�݂̂��Đ����A�t���r�f�I���[�h�ł́A�C�ӂ̃V�[���������_���ɑI���E�Đ��ł���B
�@�f����v��ɂ́A�܂��f���̃g�����X�N���v�g��v��B���̗v��ɑΉ�����f���V�[���𒊏o���邱�Ƃɂ���ĉf���̗v����������Ă���B�f���V�[���̒��o�́A�^�C���R�[�h�̏����肪����Ɏ����I�ɍs�Ȃ��B�f���R���e���c����e�L�X�g�ƃC���[�W�ւ̕ϊ��́A�N���C�A���g���Ƀr�f�I�Đ��@�\�������ꍇ�ɗL���Ɏg���邾�낤�B�f���R���e���c���Ɋ܂܂��A���ꂼ��̃V�[�����\����摜�Ƃ��ꂼ��̃V�[���̓��e��\���e�L�X�g������Ȃ�R���e���c�����邱�Ƃ��ł���B����ɁA���������e�L�X�g����v��^�|�邱�Ƃ��\�ł���B�߂������ɉf���R���e���c�̉���������|�A�f���Ɠ��������Ȃ��獇�������ŏo�͂�����@�\������̃V�X�e���ɓ����������B��̉f���R���e���c���畡���̌���ɑΉ������f���R���e���c���쐬���邱�Ƃ������ł��邾�낤�B�����͉f���R���e���c������d�v�ȏ��\�[�X�ɂȂ邱�Ƃ��m�M���Ă���B���̂��߁A�v���t�B���^�����O�Ɍ��肳��Ȃ��A�R���e���c�̍ė��p���\�ɂ��邳�܂��܂Șg�g�݂��ł��邾�����߂ɗp�ӂ��Ă��������ƍl���Ă���B����̃A�m�e�[�V�����𗘗p����
<Package title="Sports Program Package">
<Package title="Basic Description Package">
<scheme name="Title" type="element"/>
<scheme name="TitleText" type="element"/>
<scheme name="Place" type="element"/>
<scheme name="Time" type="element"/>
<scheme name="Annotation" type="element"/>
</Package>
<Package title="Production Package">
<scheme name="CreationMetaInformation"
type="element"/>
<scheme name="Creation" type="element"/>
<scheme name="Classification"
type="element"/>
<scheme name="MediaInformation"
type="element"/>
<scheme name="MediaProfile"
type="complexType"/>
<scheme name="MediaFormat"
type="complexType"/>
</Package>
</Package>
�@
�@ �Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�̋�̓I�ȃV�X�e���\���Ƃ��ẮA�g�����X�R�[�f�B���O���s�p�̃\�t�g�E�F�A���A�v���L�V�T�[�o���ɒu�����B�v���L�V�T�[�o�́A���[�U���p�\�R���Ȃǂ̃N���C�A���g������R���e���c��n���Ə��]�̌��ʂ�Ԃ��B����ɃA�m�e�[�V�������⎖������߂��A�m�e�[�V�����T�[�o��ʌɗp�ӂ����B���������`���Ƃ�̂́A�s���葽���̐l���\�t�g�E�F�A�𗘗p���Ă��炤���ƂŁA�T�[�o���̎��Ꭻ���Ƀm�E�n�E��~�ς��ϊ����x�����߂邽�߂ł���B
�@�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�����s���镡���̃\�t�g�E�F�A�E���W���[���i�g�����X�R�[�_�j�́AHTTP�iHyperText Transfer Protocol�j�v���L�V��ŋ@�\����v���O�C���Ƃ��Ď��������B�g�����X�R�[�_���]���䂷��HTTP�v���L�V���g�����X�R�[�f�B���O�v���L�V�ƌĂԁB�g�����X�R�[�f�B���O�v���L�V�𒆐S�Ƃ������̗���͎��̂悤�ɂȂ�B
| �@ | �N���C�A���g��Web �u���E�U����URL�iUniform Resource Locator�j�ƃN���C�A���gID�����B |
| �A | Web�T�[�o��URL�̎���Web�y�[�W�����N�G�X�g����B |
| �B | Web�y�[�W�����ƁA���̃n�b�V���l���v�Z����B |
| �C | �A�m�e�[�V�����T�[�o��URL�Ɋ֘A����A�m�e�[�V�����f�[�^��v������B�����A�A�m�e�[�V�����f�[�^������������A�A�m�e�[�V�����T�[�o����f�[�^�����B |
| �D | �f�[�^�����ƁA�f�[�^�̃n�b�V���l��Web�y�[�W�̃n�b�V���l�Ɣ�r����B |
| �E | �����ɃN���C�A���gID�Ɋ�Â��ă��[�U������������B���[�U��Ȃ��ꍇ�́A���[�U����^������܂Ńf�t�H���g�ݒ���g���B |
| �F | �n�b�V���l���ƍ�������A�A�m�e�[�V�����f�[�^�ƃ��[�U���Ɋ�Â��ēK�ȃg�����X�R�[�_���N������B |
| �G | ���H�����R���e���c�����[�U��Web�u���E�U�ɑ��M����B |
�@�g�����X�R�[�f�B���O�v���L�V�́A�������Ƃ���IBM Almaden Research Center �̊J������WBI�iWebIntermediaries�j���g�p����[5]
[4]�B����WBI�𗘗p�����g�����X�R�[�f�B���O�v���L�V�ɂ́A�ȉ���3�̎�v�ȋ@�\������B�l���̊Ǘ��A�A�m�e�[�V�����f�[�^�̎��W�ƊǗ��A�����ăg�����X�R�[�_�̋N���ƌ��ʂ̓����ł���B
�@�l���̊Ǘ����s�Ȃ��ɂ́A�܂��A�N�Z�X���Ă������[�U����肷��K�v������B���[�U�̓����Cookie���g���B�l�����Ǘ�����ID���ACookie�f�[�^�Ƃ��ă��[�U�ɓn���B����ɂ��A���[�U�̃A�N�Z�X�|�C���g�ɊW�Ȃ����[�U�̓��肪�s�Ȃ���B�������A������Web�u���E�U�́ACookie���Z�b�g�����T�[�o�ɑ��āA����Cookie��n�����̂ł���A�v���L�V��Cookie���p�͍l������Ă��Ȃ��B�ʏ�v���L�V�́A�z�X�g����IP�iInternet
Protocol�j�A�h���X�݂̂ɂ���ă��[�U�����ʂ���B�����ŁA���[�U���l�����Z�b�g�������ɁACookie���i���[�UID�j�ƌl�����֘A�t���A����A�A�N�Z�X�|�C���g�̕ω����Ƃ�IP�A�h���X�ƃz�X�g���ACookie���i���[�UID�j���֘A�t�������B����ɂ��IP�A�h���X���ω����Ă����[�U�̓��肪�s�Ȃ���[6]�B
�@�g�����X�R�[�f�B���O�v���L�V�́A�A�m�e�[�V�����T�[�o�ƒʐM���āA�A�m�e�[�V�����f�[�^����肷��B�A�m�e�[�V�����T�[�o�͕������݂���̂ŁA���ꂼ��̃T�[�o�̊Ǘ�����A�m�e�[�V�����f�[�^�̃C���f�b�N�X�����I�ɍ���Ă����B���̃C���f�b�N�X���A�ǂ̃A�m�e�[�V�����T�[�o����f�[�^����肷�ׂ����f����Ƃ��ɖ𗧂Ă�B�g�����X�R�[�f�B���O�v���L�V�̍ł��d�v�Ȗ����́A�l���ƃA�m�e�[�V�����f�[�^�Ɋ�Â��ăR���e���c�����H���邱�Ƃł���B�R���e���c�̉��H�́A�K�v�ȃg�����X�R�[�_���N�����A���̌��ʂ����邱�Ƃɂ���čs�Ȃ��B���݁A�J���ς݂̃g�����X�R�[�_�́A�e�L�X�g���A�摜�A�����A�f���ɂ��ꂼ��Ή��������̂ł���B�����̃g�����X�R�[�_�́A���邢�͕���Ɍ������邱�ƂŁA�����I�ȃg�����X�R�[�f�B���O�������ł���B���Ƃ��A������v���ɖ|�āA����ɉ���������Ȃǂ̈�A�̏������g�����X�R�[�_�̎g�������ɂ��s�Ȃ��B
�@
�@����̉ۑ�́AWeb �R���e���c�̌����I�Ȍ�������ђm���������������邱�Ƃł���B�߂������ɂ́AWeb��̏���ɂ́A�����̌����G���W������A�����̃R���e���c����V���Ȓm���Ă��̌��ʂ�v�ďo�͂���悤�ȁA����Βm�������G���W�����g���悤�ɂȂ邾�낤�B����ɂ���āA�n�C�p�[�����N���W�߂���ʂ̃��X�g�̑���ɁA�Z���Ԃŗe�Ղɗ����ł���悤�ɗv�ꂽ�R���e���c��ǂނ��Ƃ��ł���悤�ɂȂ�B����ɂ�����̉ۑ�́A�f���≹���Ƃ������}���`���f�B�A�E�f�[�^���܂ރf�W�^���R���e���c�̌����I�Ȍ����ł���B���̏ꍇ�̌����̎���ɂ͒P�Ȃ�L�[���[�h�ł͂Ȃ��A�������邢�̓e�L�X�g�̎��R���ꕶ��p����B���������ۑ���������邱�Ƃ́A��������Ă�����̍^�����玩�����g�����ŗǂ̕��@�ɂȂ邾�낤�B�I�����C���E�R���e���c��l�ދ��L�̒m���Ƃ��邽�߂Ɉ�ۂƂȂ��ēw�͂����邱�Ƃ��Ȃ���A�l�X�͍���������Ɋg�債�Ă������̈������玩�����g��������邱�Ƃ��ł��Ȃ����낤�B
�@
�ӎ�
�@�Z�}���e�B�b�N�E�g�����X�R�[�f�B���O�͕M�҂�IBM������b�������́i���j�w���������i�גJ�^��A����ǐ��A��������Y�A�ĉ��[�T�A�ɓ����AKevin Squire�j�Ƃ̋��������ł���B�����Ɋ��ӂ��܂��B�܂��A�r�f�I�A�m�e�[�V�����G�f�B�^�̉����F�����ɂ��ẮAIBM������b�������̐�����j���ƈɓ��L�`���A�����͂Ɩ|��g�����X�R�[�_�ɂ��ẮA���������̓n�ӓ��o�Y���A�A�m�e�[�V�����G�f�B�^��HTML��͕��ɂ��ẮA���������̋ߓ������A�����g�����X�R�[�_�ɂ��ẮA���������̒����M�ꎁ�ɋ��͂��Ă��������܂����B����ɁA����I�A�m�e�[�V�����Ɋւ��ẮAGDA�v���W�F�N�g�ƘA�g���čs�Ȃ��Ă��܂��B�v���W�F�N�g���[�_�[�̓d�����̋��c�_�ꎁ�ɂ́A��ɋc�_�̑�������Ă��������Ă��܂��B�����ɋL���Ċ��ӂ������܂��B
�@
�Q�l����
[1] A. Amir, S. Srinivasan, D. Ponceleon, and D. Petkovic. CueVideo: Automated indexing of video for searching and browsing. In Proceedings of SIGIR�f99. 1999.
[2] Koiti Hasida. Global Document Annotation.
http://www.etl.go.jp/etl/nl/gda/.
[3] Masahiro Hori et al. Annotation-based Web Content Transcoding. In Proceedings of the Ninth International WWW Conference. 2000.
[4] IBM Almaden Research Center. Web Intermediaries(WBI). http://www.almaden.ibm.com/cs/wbi/.
[5] Japan Electoronic Dictionary Research Institute. Electoronic Dictionary.
http://www.iijnet.or.jp/edr/J index.html.
[6] Hiroshi Maruyama, Kent Tamura, and Naohiko Uramoto. XML and Java: Developing Web applications. Addison-Wesley, 1999.
[7] Moving Picture Experts Group (MPEG). MPEG-7 Context and Objectives.
http://drogo.cselt.stet.it/mpeg/standards/mpeg-7/mpeg-7.htm
[8] Katashi Nagao et al. Semantic Transcoding: Making the World Wide Web more understandable and usable with external annotations. TRL Research Report
RT0386. IBM Tokyo Research Laboratory, 2000.
[9] Katashi Nagao and Koiti Hasida. Automatic text summarization based on the Global Document Annotation. In Proceedings of COLING-ACL�f98. 1998.
[10] Martin Roscheisen, Christian Mogensen, and Terry Winograd. Shared Web annotations as a platform for third-party value-added information providers: Architecture, protocols, and usage examples. Technical Report CSDTR/DLTR. Computer Science Department, Stanford University, 1995.
[11] Matthew A. Schickler, Murray S. Mazer, and Charles Brooks. Pan-browser support for annotations and other meta-information on the World Wide Web. Computer Networks and ISDN Systems. Vol. 28, 1996.
[12] SemanticWeb.org. The Semantic Web Community Portal.
[13] John R. Smith. VideoZoom: Spatio-temporal video browser. IEEE Trans. Multimedia. Vol. 1, No. 2, pp.157-171, 1999.
[14] Michael A. Smith and Takeo Kanade. Video skimming for quick browsing based on audio and image characterization. Technical Report CMU-CS-95-186. School of Computer Science, Carnegie Mellon University, 1995.
[15] Hideo Watanabe. Linguistic Annotation Language: The markup langauge for assisting NLP programs. TRL Research Report RT0334. IBM Tokyo Research Laboratory, 1999.
[16] Hideo Watanabe, Katashi Nagao, Michael C. McCord, and Arendse Bernth. Improving Natural Language Processing by Linguistic Document Annotation. In Proceedings of COLING 2000 Workshop for Semantic Annotation and Intelligent Content. pp.20–27, 2000.
[17] World Wide Web Consortium. Extensible Markup Language (XML). http://www.w3.org/XML/.
�@
[1]�g�ѓd�b�����̃R���e���c�ϊ��V�X�e���́A���܂��܂Ȋ�Ƃ����łɐ��i�����Ă���B��\�I�Ȃ��̂�IBM ��WebSphere Transcoding Publisher ��Oracle ��Portal-to-Go �ł���B
[2]���̓_�Ȃ��Ă��A�ŋ߂̓Z�}���e�B�b�N�E�E�F�u(Semantic Web)�Ƃ����l��������Ă���[12]�B����́AWeb �R���e���c���̂��̂��@�B�������\�Ȍ`���ɂ��āA�l�Ԃ̎���ɓ�������悤�ɂ��悤�Ƃ������Ƃł���B���������̎��̂́A�قƂ�ǖ��m�ɂ���Ă��Ȃ��B
[3] �O�������N�́AXML (eXtensible Markup Language)�̎d�l�ɂ���������Ă���B�������A������Web �̍\����ł̎������@�Ȃǂ̎����@�́A����ł͋c�_�̒i�K�ł���[17]
[4]���[�U���g�����X�R�[�f�B���O��v������Web �R���e���c���X�V���ꂽ���ǂ����́ADOM (Document Object Model)�n�b�V���ƌĂ���@�𗘗p����[6]�BDOM �n�b�V���ł́AWeb �R���e���c�̓����\���Ɋւ��ăn�b�V���l�̉��Z���s�Ȃ��B�ǂ�HTML �G�������g���X�V���ꂽ����m�邱�Ƃ��ł���B
[5]WBI �́AIBM Corp.��Web �T�C�g�ł���alphaWorks(http://www.alphaworks.ibm.com/)����_�E�����[�h�ł���BWBI �́A�v���O���}�u����HTTP �v���L�V�ł���A�ʏ�̃v���L�V�Ƃ��Ă̋@�\�̂ق��ɁA���[�U���̃A�N�Z�X�����A�v���L�V�ɗ����f�[�^�̉��H��e�Ղɍs�Ȃ���API (Application Programming Interface)�����B
[6]�ʏ�̃v���L�V�Ƃ��ē����Ƃ��́A�N���C�A���gID(�z�X�g����IP �A�h���X)��Cookie ���(���[�UID)���l���Ƃ�������ŁA�N���C�A���gID ����l���������o���B�A�N�Z�X�|�C���g���ω������Ƃ��́A�v���L�V���T�[�o�Ƃ��ăA�N�Z�X���邱�ƂŁACookie�����擾���A�N���C�A���gID ��Cookie ���(���[�UID)���֘A�t�������B