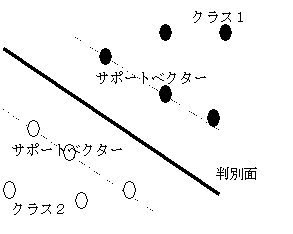
図3.5-1 SVMの概念図
最近の音声情報処理に関連するトピックスや個々のプロジェクトを、音声認識の分野を中心に、具体的にピックアップして述べる。トピックスとしては、まず、アルゴリズムや手法の研究に関して、現在の主流である統計的手法に対するブレークスルーを目指す試みを、いくつか紹介する。次に、研究や開発に不可欠な、ツールやソフトウェアの整備状況について報告する。また、急速に広がりつつある音声認識の応用分野や製品をとりあげて、その傾向を探る。プロジェクトとしては、現在進行中のものを、日米欧それぞれについて、経過や背景を含めて述べる。最後に、研究やプロジェクトの今後の方向性を展望する。
現在主流となっている音声認識のアルゴリズムは、隠れマルコフモデル(HMM)[1]をはじめとする統計的手法に基づくものである[2]。近年の音声認識ソフトウェアの実用化の急速な進展は、これに負うところが大きい。しかし、その進歩が収束しつつある今、新たなブレークスルーとなるような手法の開発を目指した研究が、活発に行われている。残念ながら今のところ、画期的な手法が発見されるには至っていないが、そのなかでも比較的まとまった潮流になりそうなものを、いくつかピックアップして紹介する。
3.5.1.1 独立成分分析(ICA)
独立成分分析(ICA)は、音源の数より多い本数のマイクを用意して収録した波形から、音源信号の統計的独立性に基づいて、信号を分離する手法である[3]。これを利用することにより、複数話者の音声が混じっている環境から必要な音声を分離したり(いわゆるカクテルパーティー効果[4])、ノイズ環境における認識精度の向上が期待される。研究報告としては、[5][6][7]などがある。
3.5.1.2 サポートベクターマシン(SVM)
サポートベクターマシン(SVM)は、サンプルのクラスを判別する空間を学習する手法であり、単層パーセプトロンの改良版ととらえることもできる。図3.5-1のように、サポートベクタと呼ばれる最前線のサンプルに基づいて、クラスを分ける最適な超平面を求める。VC次元(Vapnik-Chervonenkis
dimension)に基づく尺度により、過学習の問題を回避できる利点がある[8]。これを音声認識に適用した研究としては、[9] などがある。
3.5.1.3 ベイジアンネット
ベイジアンネットワークは、命題や確率変数の間の依存関係を、条件付き確率を付加した有向グラフで表現したものである[10]。これは、HMM を一般化したものととらえることもでき、従来の
HMM をベースとする手法からの性能改善が期待される。このような試みとして、[11] などがある。
3.5.1.4 HMM音声合成
HMM を音声認識だけでなく音声合成にも利用しようとする試みも、数年前から精力的に研究されている[12]。合成音声の話者的特徴を変える(声質変換・話者変換・音声モーフィング)際に、パラメータの加工が容易になる利点がある。
音声情報処理の研究や開発を効率よく進めるためには、そのためのソフトウェアやツールが重要な役割を果たす。本節では、無償で入手できるものを中心に、いくつか紹介する。
3.5.2.1 IPA日本語ディクテーション基本ソフトウェア
ディクテーションとは、新聞記事の読み上げのように、主として書き言葉的な文章を比較的正確に発声するタスクである。「IPA日本語ディクテーション基本ソフトウェア」は日本における大語彙音声認識の研究開発のための、共通のプラットホームを目指し、情報処理振興事業協会(IPA)のプロジェクトとして、開発が行われた[13]。1999年版の認識精度は、毎日新聞記事読み上げ音声
(JNAS)の20000語彙のタスクにおいて、単語認識率 85〜95% となっている。プロジェクトの終了後、「連続音声認識コンソーシアム[14]が組織され、話し言葉への対応や、認識精度の向上、実環境への対応、Windows
への移植、などの研究が続けられている。
3.5.2.2 擬人化音声対話エージェント基本ソフトウェア
コンピュータのユーザインタフェースとして音声を利用する場合、前節のディクテーションのように、人間が一方的に発声するだけでなく、音声合成も利用して、対話的なやりとりによって、目的を達成するようなシステムが望ましい。さらに、対話の具体的な相手として、画面上に、秘書のような人物(エージェント)が表示されると、よりユーザの親近感が増し、コミュニケーションの効率が向上する。
IPAの「擬人化音声対話エージェント基本ソフトウェア」プロジェクトは、そのような擬人化エージェント技術の実現を目指して、2000年から3年間実施される[15]。それ以前の
IPA プロジェクトとして開発された、大語彙音声認識技術(前節)及び、顔画像生成技術(感性擬人化エージェントのための顔情報処理システム)をベースに、対話音声認識、音声との同期が可能な顔画像合成・制御、対話音声合成、それらを統合するエージェント統合ソフトウェアの開発が行われる。
3.5.2.3 OGI CSLU Toolkit
OGI CSLU Toolkit[16] は、Oregon Graduate Institute の Center for Spoken Language
Understanding において、NFS(The National Science Foundation)やDARPA(Defense Advanced
Research Projects Agency)の支援を受けて開発された。これには、音声認識、音声合成、自然言語理解、顔のアニメーションなどのプログラムが含まれている。このうち音声合成のプログラムは、エジンバラ大の
CSTR(Centre for Speech Technology Research)で開発された Festival であり、これは Edinburgh
Speech Tools Library[17] としても配布されている。
3.5.2.4 CMU-Cambridge Statistical Language Modeling Toolkit
CMU-Cambridge Statistical Language Modeling Toolkit は、カーネギーメロン大とケンブリッジ大で開発された、統計的言語モデルを構築するためのツールである[18]
。統計的言語モデルは、HMM とともに、現在確立されている音声認識手法の基本要素である。このツールキットには、n-gram と呼ばれる n 個の単語の連鎖統計を求めるプログラムが含まれている。通常の音声認識では、bigram(2連鎖)や
trigram(3連鎖)が用いられる。
3.5.2.5 HTK
HTK(Hidden Markov Model Toolkit)は、HMM に基づく音声認識システムを構築するためのツールキットとして、使い勝手や完成度に定評があり、研究や開発に広く用いられている。ケンブリッジ大の
Speech Vision and Robotics Group で開発され、米 Entropic Research Laboratory 社から販売されていたが、昨年Microsoft
社が買い取って、ケンブリッジ大工学部(CUED)にライセンスを返還し、無料で配布されるようになった[19]。
3.5.2.6 音声データベース
音声サンプルを収集したデータベース(コーパス)も、音声の研究や開発のための重要な要素である。特に、統計的手法においては、データベースの質と量が、その性能を決定すると言っても過言ではない。これまでは、ディクテーション向けの読み上げ音声を中心に収集が進んでいたが、近年は、認識対象の拡大に応じて、雑音環境、自由発話音声、会議音声、多言語、非母語(ノンネイティブ)話者、子供や老人話者、などを扱ったものが増えてきている。各々についての詳細は省略するが、日本語の音声データベースの一覧は[20]で参照できる。
ここ数年の間に、統計的手法が確立され、かなり高い精度で大語彙音声を認識することが可能となったことにより、音声認識の応用範囲も急速に拡大してきた。
ここで、現在の音声認識技術の水準を振り返っておくと、認識精度は、(雑音環境やマイクの設置方法や発声のしかたなどにも依存するので、一概には言えないが、)概数として、数万語彙の書き言葉的文章の読み上げに対して、約80〜90%
といったところである。また、対話的なタスクの意味処理に関しては、予め想定された状況や意味の遷移に対して、フレームのスロットを埋めていくといった手法が主となる。従って、人間を相手とするときのような高度な意味理解は期待できない。
このような制約のもとで考えられる主な応用分野は、下記のように分類される。
本節では、それらのなかから目立った動きをとりあげて紹介する。
3.5.3.1 検索への応用
意味理解を必要としない点で、音声による検索は、制約条件に合った応用分野と言える。音声認識により、予め文字情報に変換すれば、従来のテキストベースの検索手法が適用できるが、音声や画像の特性を活かしたマルチメディア向きの検索手法の研究も、活発に行われている[21]。その場合に、画像認識技術なども統合したマルチモーダル検索システムの構築を目指す研究が多い[22]。また、非母語話者を含む多言語話者による検索に適した手法の研究も行われている[23]。検索対象としては、音声データを含むコンテンツとして、放送や映画を扱うものが多い。また、音声ではないが、音楽の検索も手法的に関連のある分野である[24]。
3.5.3.2 テレビ放送への応用
ディクテーション技術の応用のひとつとして、TVニュースの字幕の生成がある。米国CNN放送などの字幕では、人間がリアルタイムにタイピングして入力しているが、日本語の場合は、熟練した人でも、ほぼ不可能である。
NHK では、2000年3月から7時のニュースで、音声認識を利用したリアルタイム字幕化を行っている[25]。予めニュース原稿を与えるなどの工夫により、実用的な認識精度に近づけている。ただし、比較的話し言葉に近いニュース解説などに対しては、認識精度の低下が起こる。
3.5.3.3 パソコン等のユーザインタフェースへの応用
意味処理における状況が比較的限定できるタスクとして、パソコンのOSやアプリケーションGUIの代替としてのコマンド処理を行うものがある。
Microsoft Officeの時期バージョンであるXP[1]には、音声認識が標準搭載されることになっている。上のHTKの項にも見られるように、Microsoft社は、音声認識技術を将来のユーザインタフェースの柱のひとつとして重要視しており[26]、この他にも、Microsoft
Agent と呼ばれる音声対話エージェントを開発し、配布している。またシャープでも、IBMの音声認識ソフトViaVoiceをベースとした対話エージェントを開発し、パソコンに同梱するなどして販売している[27]。これ以外でも、音声合成ソフトやディクテーションソフトが、多くのパソコンにバンドルされるようになってきている。
また、エージェント以外の案内システムとしては、従来のカーナビ等に加えて、電話応答によるコールセンター向けの音声認識システムなども多数販売されるようになってきている。
3.5.3.4 玩具やゲームへの応用
2年ほど前から、音声合成装置を内蔵したペットロボットが多く見られるようになってきた。また、ソニーのAIBOの2世代目には音声認識も搭載できるようになっており[28]、今後、このような製品が増えると予想される。玩具に限らず、ホンダ等に代表されるヒューマノイドロボットのブームも、近年の大きな話題であるが、これらにも音声対話技術が組み込まれていくと考えられる。
家庭用ゲーム機のソフトでも、音声認識の普及は目覚しく、「シーマン」のようにELIZA風の会話を行うものから、麻雀やサッカーゲームなどに応用が拡大してきている。
この分野は、認識誤りをある程度許容できるという点で、必ずしも最先端の音声認識技術を必要としないが、人間とのコミュニケーションによって新たな語彙や知識を獲得したり、人間にとって自然な会話を実現するなど、認知科学的研究の進展と連動していく可能性がある。また、従来から、音声認識の応用の一般への普及を阻んでいる要因のひとつとされる、初心者の音声認識に対する心理的抵抗感を、低減する効果も期待できる。
3.5.3.5 その他
これら以外に、今後の応用が広がる分野として、携帯機器がある。機器の小型化のためには、入出力デバイスの大きさの点で、ユーザインタフェースに音声のみを使うのが、最も有利であると考えられる。
携帯電話には、これまでにも、登録した電話番号を検索する単語音声認識が組み込まれたものがあったが、今後は、さらに操作全般や電子メールなども応用が進むと予想される。PDA(Personal
Data Accessory)についても同様であり、例えば、米 Palm 社が音声認識会社と提携するなどの動きが見られる[29]。また、試作段階ではあるが、携帯用音声翻訳装置も発表されている[30]。
また、電子協のプロジェクトなどにより今後の進展が期待されるユビキタスコンピューティングにおいても、音声によるユーザインタフェースが重要な要素となる。
次に、現在進行中のプロジェクトを、日米欧それぞれにについて述べる。
3.5.4.1 米国における音声認識プロジェクト
米国における音声認識プロジェクトは、1970年代から主としてDARPAを中心に進められてきた。また、AT&TやIBMなどでも、独自に研究が進められてきた。ここではまず、「Blue
Book(Information Technology)2001」に挙げられているものを紹介し、次にDARPAのプロジェクトについて述べる。
(1) Blue Book 2001 より
「Blue Book」では、NISTがDARPAやNSAと共同で開発したベンチマークテストが取り上げられている。ラジオやテレビのニュース放送のような、語彙制約の少ない音声の準リアルタイム認識などを対象とした新しい情報抽出の尺度やテスト法が、昨年度までに実現され、今年度も開発が続けられる。また、NSAでは特に、電話における会話音声の認識や話者認識を対象とした開発を行っている。
(2) DARPAの音声認識プロジェクト
DARPAは、NSFとともに米国における政府主導の研究開発の中心的役割を担ってきた。音声認識に関しても、継続的に大規模なプロジェクトを立ち上げ、MITやCMUなどの大学や、BBNやSRIといった研究会社を組織して、研究の主流を方向付けてきた。ここでは、そのプロジェクトを、過去からの経過を含めて述べる。
まず、1970年代の「音声理解プロジェクト」において、HearsayII や Harpy などが開発され、言語処理まで含めた音声認識システムの実用化の可能性が初めて示された。その後しばらくして、1980年代後半からの一連の「第2期音声理解プロジェクト」においては、プロジェクトごとに共通の課題となるタスクを設定し、認識率の競争を行うことによって、研究の進展を促してきた。1987年〜1991年の「Resource
Management」においては、船の輸送や配置のような小規模なタスクにおける不特定話者連続音声認識を対象とした。この頃からCMUのSPHINXに代表されるような、HMMに基づく手法が主流になった。次に、1990年〜1994年の「ATIS
(Air Travel Information System)」タスクにおいて、航空券予約のデータベース検索などを行う音声対話システムが研究された。また、1991年〜1996年の新聞記事読み上げ音声の認識タスクにおいて、Wall
Street Journal や North America Business News といった新聞記事を対象とした大語彙ディクテーションシステムが研究され、統計的言語モデルの有効性が示された。その後、1995年〜1999年に、CNNなどのニュース放送音声を対象としたタスクにおいて、より自由な発話の認識の研究が行われた。そして、1999年からは、「Communicator」[31]と呼ばれるプロジェクトが始まり、擬人化エージェントを対象とした音声対話システムの開発を行うとともに、API
の共通化やライブラリの配布による研究のプラットフォームを目指している。
3.5.4.2 欧州における音声認識プロジェクト
欧州における情報関係の大規模プロジェクトとして、ESPRITプロジェクト[32]があり、現在、第5期目が実施されている。この中に、音声情報処理に関係するものも多く含まれている。代表的なものとしては、1988年〜1993年に実施されたSUNDIAL[33]があり、電話回線を用いた音声対話システムの研究が行われた。欧州における研究は、欧州統合などの社会状況を反映して、多言語音声を扱うものや翻訳関係に特徴がある。
3.5.4.3 国内における音声認識プロジェクト
国内における現在進行中のプロジェクトからいくつか取り上げて紹介する[34]。
1983年から開始されたATR(国際電気通信基礎技術研究所)は、近年の日本の音声認識における代表的プロジェクトである。その傘下で、音声翻訳通信研究所における、限定されたタスクでの自然な話し言葉の音声翻訳技術の開発、人間情報通信研究所における、聴覚機構や発声機構の研究、知能映像研究所における、人間と機械とのコミュニケーションに関する研究など、多くの成果をあげてきた。現在は、音声言語通信研究所[35]において、それらを発展させた研究が続けられている。
名古屋大学統合音響情報拠点(CIAIR)[36]は、1999年度から文部省COEプログラムとして開始された。音情報に関する先導的研究の拠点として、実環境における頑健性やデータベースなどの研究が進められている。
「大規模コーパスに基づく『話し言葉工学』の構築」プロジェクト[37]は、科学技術庁の科学技術振興調整費に基づき、国立国語研究所、郵政省通信総合研究所、東京工業大学を中心として、1999年度から開始された。学会発表やスピーチのような比較的自由なタスクでの独話を主体とした大規模話し言葉コーパスの構築や、その認識・理解・要約などの研究が行われている。科学技術振興調整費では、この他に「ヒトを含む霊長類のコミュニケーションの研究」が、1997年度から開始されている。
この他に、文部省科学研究費による「音声言語情報処理技術を用いた語学CAI」や、科学技術振興事業団(CREST)による「発声力学に基づくタスクプランニング機構の構築」「聴覚の情景分析に基づく音響・音声処理システム」などの研究が行われている。また、先に述べたIPAのプロジェクトや言語資源共有機構(GSK)[38]などにおいて、研究用ツールやデータベースの整備が進められている。
これまでに述べてきたような音声認識研究の現状をふまえて、今後のプロジェクトの方向性を展望してみる。
先に述べたように、統計的手法が確立されて、その後10年以上大きな展開が見られない状況を考慮すると、今後のプロジェクトとしては、現在確立されている技術を利用して、それを改良・発展させたり、新たな応用を探ったりする方向と、新たな手法や枠組みを発見していく方向とに、2極化せざるを得ないと思われる。
現在の技術の延長線上で発展させていく際の常道は、前述のDARPAのプロジェクトに見られるように、目標とするタスクの設定を段階的に拡張していく方法である。すなわち、ニュースや新聞の読み上げ音声を対象としたタスクから、講演会のスピーチ、複数話者の会議、パーティーでの日常会話、といった拡張や、雑音等の環境の種類の拡張、多言語や老人・子供といった話者の拡張、などがある。
新たな技術を開発する方向としては、HMM に代る学習・識別アルゴリズムの研究や、意味や概念や常識といった本質的に困難な認知科学的研究、MRIやPETなどの計測技術や脳科学の進歩に基づく聴覚や発声などの生理的研究などがある。
前者の方向は、比較的見通しも立てやすく、予算に応じた着実な成果が期待できるが、画期的な進展の可能性は少ない。後者は、成功すれば画期的なブレークスルーにつながる可能性はあるが、効果的な成果が得られない可能性も大きい。従って、現実的な施策としては、前者に予想される効用に応じた予算を付け、後者に広く浅く予算を付ける、ということになる。しかし、本来の方向性である熱気のある研究状況をつくりだすためには、脳科学や、音情報、知識発見、感性的コミュニケーション、といった、音声の分野としての枠を破るような大きな枠組みでの展望を考えることが課題となっていくであろう。
参考文献
[1] 中川「確立モデルによる音声認識」、電子情報通信学会 (1988).
[2] 「人間主体の知的情報処理技術に関する調査研究III」AITEC (2000).
[3] A. J. Bell, T. J. Sejnowski“An information maximization approach to blind separation and blind deconvolution,” Neural Computation No.7 (1995).
[4] J. Blauert.“Spatial Hearing: The Psychophysics of Human Sound Localization,” MIT Press (1983).
[5] J. H. Lee, H. Y. Jung, T.W. Lee et al,“Speech Feature Extraction Using Independent Component Analysys,” Proc. ICASSP 2000, Vol.III, pp.1631-1634 (2000).
[6] Y. Blanco, S. Zazo, J. Paez-Borrallo,“Adaptive Processing of Blind Source Separation thorough ‘ICA with OS’,” Proc. ICASSP 2000, Vol.I, pp233-236 (2000).
[7] H. Saruwatari, S. Kurita, K. Takeda, et al. “Blind Source Separation Based on Subband ICA and Beamforming,” Proc. ICSLP 2000, Vol.III, pp.94-97 (2000).
[8] V. Vapnik, ``The Nature of Statistical Learning Theory,” Springer-Verlag (1995).
[9] A. Ganapathiraju, J. Hamaker, J. Picone, “Hybrid SVM/HMM Architectures for Speech Recognition,” Proc.the 2000 Speech Transcription Workshop.
[10] D. Poole, “Probablistic Horn Abduction and Bayesian Networks,” Artificial Intelligence, Vol.64, pp.81-129 (1993).
[11] T. Stephenson, H. Bourlard, S. Bengio, et al. “Automatic Speech Recognition Using Dynamic Bayesian Networks with both Acoustic and Articulatory Variables,” Proc. ICSLP 2000, 01212 (2000).
[12] 益子, 徳田, 小林, 他「動的特徴を用いたHMMに基づく音声合成」、信学会論文誌, J79-DII, 12 (1996).
[13] 河原、李、小林、他「日本語ディクテーション基本ソフトウェア(99年度版)」、音響学会誌、Vol.57, No.3 (2001)
[14] http://www.lang.astem.or.jp/CSRC/
[15] http://www.ipa.go.jp/STC/dokusou.html
[16] http://cslu.cse.ogi.edu/toolkit/index.html
[17] http://www.cstr.ed.ac.uk/projects/speech_tools/
[18] http://svr-www.eng.cam.ac.uk/~prc14/toolkit.html
[19] http://htk.eng.cam.ac.uk/
[20] http://db.ciair.coe.nagoya-u.ac.jp/dbciair/speech_corpus.htm
[21] 柏野、スミス、村瀬「ヒストグラム特徴を用いた音響信号の高速探索法―時系列アクティブ探索法―」、信学会論文誌、Vol.J82 D-II No.9 (1999).
[22] 岡「Cross Multi-media における音声の“認識”とは?」、音響学会春期講演論文集 pp.77-80 (1999).
[23] 田中、児島、富山、他「言語に共通な音声符号系とその音響セグメントモデルの作成」、音響学会春期講演論文集、pp.191-192 (2001).
[24] http://www.rwcp.or.jp/press-release/press00-20.html
[25] 安藤「ニュース音声自動字幕化システム」、信学会技術研究報告 SP2000-102 (2000).
[26] http://research.microsoft.com/srg/
[27] http://www.sharp.co.jp/liquiy/liquiy02.html
[28] http://www.jp.aibo.com/whatsaibo/ers_210_sound.html
[29] http://www.zdnet.com/zdnn/stories/news/0,4586,2626961,00.html
[30] 大淵、北原、小泉、他「マイコン向け音声認識技術を用いた携帯型音声通訳機」、信学会論文誌、Vol. J83 D-II, No.11, pp.2309-2317 (2000).
[32] http://www.cordis.lu/esprit/home.html
[33] http://www.newcastle.research.ec.org/esp-syn/text/2218.html
[34] 小特集「音声研究の新たな方向を探る」、音響学会誌、Vol.56, No. 11 (2000).
[35] http://www.slt.atr.co.jp/
[36] http://www.ciair.coe.nagoya-u.ac.jp/
[37] http://www.crl.go.jp/pub/nlp/CFP/540.html
[38] http://tanaka-www.cs.titech.ac.jp/gsk/gsk.htm
[1] それ以前は Office 10 と呼ばれていた。