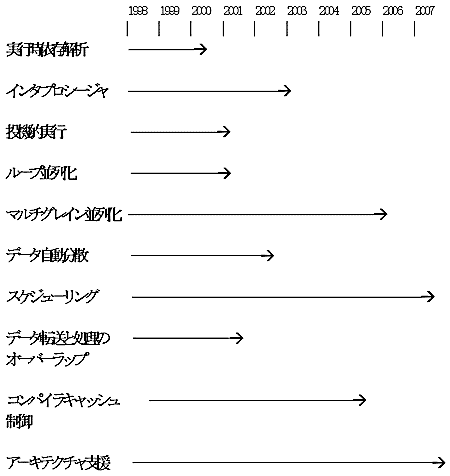
1980年代の後半、マイクロプロセッサはRISCの提案による命令の簡素化によるクロックの向上とパイプライン処理の利用により高速化を果たしたが、90年代になって、命令の動的スケジューリング、複数命令の同時発行、キャッシュの高機能化、投機的実行など、高速化のテクニックはますます発達し、それにつれてマイクロプロセッサの構造はますます複雑化した。複雑化した構造は、それを実装するための半導体の面積を必要としたが、高機能マイクロプロセッサの実装に見合う分の面積は、半導体技術の発達によって常に供給が保証されてきた。このようにして高性能マイクロプロセッサの性能は向上し続けてきたが、1996年に入って、シングルプロセッサとしての高速化テクニックが限界に達する一方、半導体技術の発達が衰えぬペースで続いた結果、半導体の面積を有効に利用できない可能性が生じた。この問題を解決するためのアプローチが2つ提案された。
(1) シングルチップマルチプロセッサ:巨大な高機能プロセッサに代わって、 比較的簡単なRISCプロセッサを複数搭載する。
オンチップマルチプロセッサ、マルチプロセッサチップ、1チップマルチプロセッサと呼ばれる場合もあるが、ここではシングルチップマルチプロセッサと呼ぶことにする。
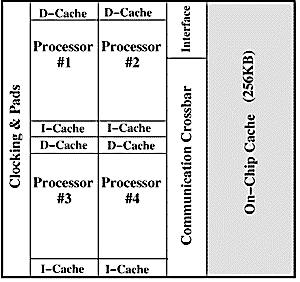
図1に最も基本的なシングルチップマルチプロセッサの構成を示す。
この構成では、4つのプロセッサが大規模な共有L2キャッシュと共に1チップ上に搭載されている。
(2) DRAM混載:主記憶の一部であるDynamic RAMを同一チップ上に搭載する。
後者の考え方には、チップ外のメモリへのアクセスの壁(Memory Wall)による性能の低下に対する解決法のひとつとしての意味も持っている。
もちろん、この両方を用いる、すなわち、シングルチップマルチプロセッサにDRAMを混載するアプローチも有力である。今回のロードマップは、半導体技術の発展に対して、この2つのアプローチがそれぞれの年代で取り得る形式を検討する。
まず、SIAのロードマップ[1]を参考に、各要素の面積の予測をざっとまとめると表1のようになる。
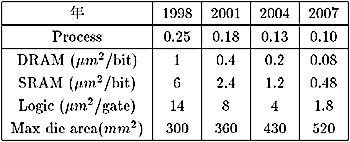

表1を基に、それぞれの年代で、どのような構成が可能になるかをざっと予測してみた(表2)。予測には、2種類のプロセッサを用いた。比較的軽量の組込み用プロセッサとしてはR5000 (3.6Mgates、 64KB Cache)を選び、WS/デスクトップPC用のプロセッサとしては、現在最も面積が大きく性能の高いDEC Alpha 21164 (9.3Mgates、 112KB Cache)を選んだ。シングルチップマルチプロセッサ構成にした場合、キャッシュの要求量が問題だが、問題を簡単化するために、各プロセッサ毎に現在のキャッシュ分だけ持たせると仮定した。すなわち、Single Portの共有キャッシュなら、現在のプロセッサ数倍、プロセッサ数分のポート数を持たせるならば、現在と同量を搭載することになる(これはちょっと少ないかもしれない)。
シングルチップマルチプロセッサ構成は、プロセッサ数は最大4とした。これは現状の技術の延長で汎用目的では、これ以上あっても活用が難しいと考えたためである。
また、ここでは、WS/デスクトップPC用の高性能プロセッサ(DT)と、ラップトップあるいは移動、制御目的用軽量省電力プロセッサ(LT)の2種類を分けて考えた。前者は、予測された最大面積を使うとしたが、後者は、年代にかかわらず150mm2とした。年代が進んでも、この辺の面積を越すと価格がぐっとアップするという状況はあまり変わらないのではないかと考えたためである。表中で4+56MBと表記した場合、4プロセッサのシングルチップマルチプロセッサで56MB DRAM搭載可能を示す。表中は、一応バランスが取れているとみなせる場合のみを示し、プロセッサに対して極端にDRAMが少なくなったり、多くなるようなアンバランスな構成になる場合は示していない。
この表自体大変怪しい代物だし、将来Alphaを上回る巨大チップが確実に出現するので、1ランク上のプロセッサに対する予測が必要であるが、少なくても以下の点を読みとることができる。
(1)余った面積をシングルチップマルチプロセッサにつぎこんだ方が有利になる時期は、2回来るだろう。
1回目は、現在から近い未来(1998年)である。この時期は、DRAM混載技術がまだ立ち上がり段階で、余った面積をDRAMにつぎこむと、価格的に有利な面積のチップでは十分な量搭載することができない。これに対しDRAMを混載しないシングルチップマルチプロセッサは、容易に数を増やすことでピーク性能を上げることができる。しかし、シングルチップマルチプロセッサにしても、並列プログラムでピーク性能を上げたり、マルチジョブをするだけでは、商業的に採算は合わないと考えられるので、実験的なシステムに留まる可能性が高い。しかし、この時期に実験システム上で、シングルジョブの高速化技術を確立しておく必要がある。
2回目は、シングルチッププロセッサ+DRAM構成にしても面積が余るようになる2004年以降である。もちろんAlphaを上回る面積の高性能プロセッサは今後も出てくると思うが、それでも2004年を越えると上記の傾向は出てくると考えられる。最初の時期に、シングルジョブの高速化技術をきちんと確立しておけば、これ以降シングルチップマルチプロセッサ+DRAMがマイクロプロセッサの王道になることが期待される。
(2) 先にブレークするのは、DRAM混載、LT用であろう
DRAM混載型プロセッサは、[1] 実装面積が小さくなる、[2] 電力消費量が減る、の2点で携帯用、移動用、制御用に圧倒的に有利である。DT用では、これからも面積の大きい強力なチップが登場するであろうから、DRAM混載がブレークするのは、まず移動用分野で、それが可能になるのは150mm2程度のサイズで搭載が可能になる2001年前後であろう。それから、どんどんDT用に普及が広がっていくであろう。
(3) DRAM混載型は必然だがシングルチップマルチプロセッサはわからない
前項のようにDRAM混載は、絶対的に有利な点と将来性のある分野を抱えているがシングルチップマルチプロセッサはそうではない。ここ数年のうちにシングルチップマルチプロセッサ上で並列化されていない単一ジョブを高速化する技法が発達することが重要である。NECの提案するMUSCUT[2]、早稲田大学の笠原研の提案するコンパイラ主導のアプローチ[3]は、有望かどうかは別としてどんどんやらなければならない。2007年以降、余った面積を使うためにのみシングルチップマルチプロセッサ化が行われるとしたら、その頃はWS/PC自体が、今のメインフレームのように計算機利用の主体からはずれているのではないかと思われる。普及しはじめたSMPの使われ方に注目する必要がある。また、マルチメディア用チップ、FPGAを用いたCustom Computing Machine、通信用チップ等専用チップと考えられているチップに注目する必要があろう。
参考文献
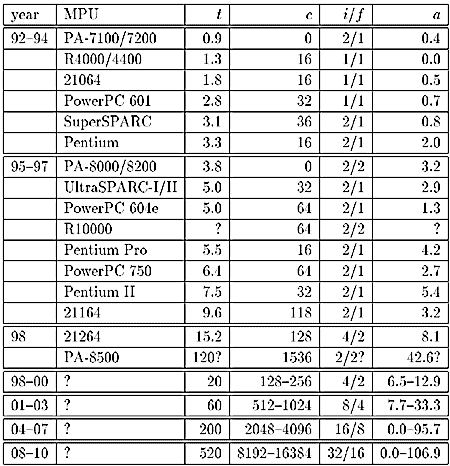
表1は、過去6年の代表的なマイクロプロセッサについて;
をまとめ、それに基づいて将来動向を予測したものである。1992~94年と1995~97年ではトランジスタ数とキャッシュ容量が約3倍程度増加したのに対し、演算ユニットの数はさほど増加していない。そこでこの傾向を説明するために、「付加的」論理によるトランジスタ消費量aを、下式によって定義する。
すなわち;
と考える。なお「基本的」論理による消費量は、比較的単純な構成であるR4000のキャッシュを除くトランジスタ数である。
最近の2世代については、この「付加的」トランジスタ数が大きく増加しているが、これは本格的なスーパスカラアーキテクチャの採用、すなわちout-of-orderの命令発行や完了、分岐予測や投機的実行といった高度なプロセッサアーキテクチャが採用されたことによるものである。またこのようなアーキテクチャは、3.1.3で述べた予測技術と密接に関連している。
そこで将来の動向を以下のように予測する。
その結果、今後10年間では100万から1000万のオーダのトランジスタが、「付加的」論理に費やされるという結論が導かれる。すなわち単純に命令を実行する以外の、予測技術などを含めた種々の機構(あるいは「付加的」プロセッサ)の一層の高度化が予測される。

――――――――――――――――――――――――――――――――――――――
説明
前にも述べたように、アプリケーションのロ-ドマップを一般的に示すことは、不可能に近い。そこで、ここではアプリケ-ションを構成する色々な軸をあげ、各軸での方向を示すだけに止める。アプリケ-ションを構成する軸には
| ・1次元 | --> | 2次元-->3次元 |
| ・線形 | --> | 非線型 |
| ・定常解 | --> | 非定常解(時間的変化) |
| ・1ケースの計算 | --> | 多くのケースの計算(パラメトリックスタディ、最適化) |
| ・粗いモデル | --> | 詳細なモデル |
| ・汎用解法 (アルゴリズム) |
--> | 専用解法 |
| ・低レベルのモデル記述 | --> | 高いレベルでのモデル記述(間違いにくい記述方法へ) |
| ・問題解決の重要度の移動(全体の時間を短縮することが重要) | ||
| ・計算能力の向上により、それまでは不可能であった計算方法・新分野が出現 | ||
が考えられる。ある時点のあるアプリケーションはこれらの要素を軸とする多次元空間上の点として表現される。計算機、計算手法の発達により、アプリケーションの位置は各軸の原点から離れた方向に発展している。どのような位置を移動するかはアプリケ-ションの性質に依存する。あるアプリケーションは速く3次元化するであろうし、他のアプリケーションは3次元化をする前にモデルの詳細化が先行するというようなことになるであろう(図1)。