World-Wide Web情報検索(WWW情報検索)の最新動向をサーベイし、WWW情報検索の重要性と現在の問題点を指摘する。そして、それらの問題点を解決するための試みの例として「分散型WWWロボット」及び「投機的情報検索システム」について紹介する。最後に、WWW情報検索を例題として、これからの研究開発がどうあるべきかを論じる。
1969年のアメリカ国防総省高等研究計画の出資によるARPAnet(Advanced Research Project Agency Network)に始まるインターネットの歴史は、1994年頃からの WWW(World-Wide Web)ブームにより、研究者たちだけのものから、一般大衆のものへと大きな変化を遂げた。
この変化は数値で見ても明らかであり、インターネットに接続するコンピュータ台数は、1994年1月に220万台であったものが、1995年1月に580万台、1996年1月に1440万台、とほぼ倍々で増加した。そして、1997年1月に2180万台、1998年1月に2970万台と1996~1997年の伸び率は多少鈍化したものの、ここ2年は年間約800万台のコンピュータが新たにインターネットに接続され続けている[1]。
1998年1月には、世界の約300万組織、2970万台のコンピュータがインターネットに接続され、1998年2月現在のWWWサーバ数は全世界で約192万台[2]、それらのサーバから提供されるHTMLページ数は2億ページを越えると推測される。
このような膨大な情報の中から、必要な情報を瞬時に、かつ、的確に見つけ出すための仕組みがWWW情報検索サービスである。そして、インターネット上の膨大な情報を有効に利用するためにWWW情報検索は必要不可欠な存在となっている。
1994年頃からインターネットが一躍注目されるようになったのは、インターネットを介して文字、画像、音声などの情報を広く世界中に発信できるWWW(World Wide Web)サーバとそれにアクセスするソフトウェア(WWWブラウザ)が普及し、インターネットがマルチメディアを具現化する媒体として活用されるようになったからである。
WWWは、欧州のCERN[3]と呼ばれる高エネルギー物理学の研究所が開発した分散データベースである。1993年に、このWWW上のデータにアクセスするためのWWWブラウザを米国のイリノイ大学の研究グループが開発し、Mosaic[4]という名で無料で一般に公開したのをきっかけとし、爆発的にその利用が進んでいる。
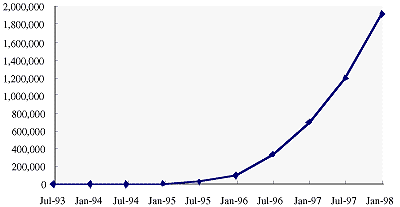
図3.2-1に示すように1995年以降、WWWの利用が急速に進み、現在では、WWWを使えば、世界の政治・経済・観光情報、各企業の製品情報、さらには、映画や音楽等の趣味にいたるまで、世界中のありとあらゆる情報を手に入れられるようになっている。
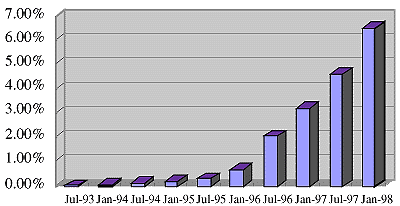
1998年2月の時点でのWWWサーバ数は、約192万台[2]であり、インターネットに接続される全コンピュータ台数に占める割合は、約6.5%である。また、図3.2-2に示すようにこの割合は年々増加しており、WWWサーバによる情報提供が、積極的に押し進められていることがわかる。
WWW情報検索サービスは、そのデータベースの構築によって図3.2-3に示すように、大きく3つに分類できる。
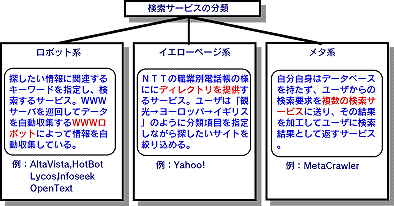
(1)ロボット系検索サービス
ロボット系検索サービスは、WWWロボットやスパイダーと呼ばれるWWW探索プログラム(一般にWWWロボットと呼ぶ)を用いて、インターネット上で見つけることのできる全WWWサーバー上の情報を定期的に収集し、その情報の索引付けを自動的に行う検索サービスである。例として、AltaVista[6]、HotBot[7]、Lycos[5]、Infoseek[8]、OpenText[9]等が挙げられる。これらの検索サービスでは、探したい情報に関連するキーワードを入力することによって、目的のサイト(WWWサーバ)を検索できる。
ロボット系検索サービスでは、コンピュータによって自動的に全世界のデータを収集しているため、情報量が多いという利点を持つ。一方、各HTMLページの要約を自動的に生成したり、索引付けを自動で行うため、要約の完成度が低くかったり、キーワードを入力して検索しても、目的とするサイトが何万件と出てしまい、目的のサイトを絞り込むのに膨大な時間がかかったりするという欠点を持つ。例えば、人間が文章を読めば、「この文中でインターネットという単語は出てくるが、この文は、日本の経済について書いた文である」と理解できても、コンピュータには、それが理解できず、「インターネット」に関連のある文と判断し、キーワードとして「インターネット」を付加してしまう。つまり、人間が索引付けをする時には、内容を考えた索引付けができるが、コンピュータは、出てくる単語を単純に索引とするため、キーワード検索した際に、本来関係無いようなサイトまで検索結果として表示されることになる。
(2)イエローページ系検索サービス
イエローページ系検索サービスは、Yahoo![10]に代表されるディレクトリー型の検索サービスである。WWWのアドレスを示すURL(Universal Resource Locator)を、芸術、ビジネス、教育....、のように分野別に整理して並べてあるので、NTTの職業別電話帳のような使い方ができ、分野を決めてから探す時に便利である。データの入力は、基本的に人手で行うため、ロボット系検索サービスに比較してデータ量が2~3桁少なく、有名なページやユーザが登録したページ以外を探すことが出来ないといった欠点を持つ。一方、人間が索引を作成し、かつ、要約を書いているので、索引と要約の信頼度が高い。
(3)メタ系検索サービス
メタ系検索サービスは、自分自身でデータベースを持たず、ユーザからの検索要求を複数のロボット系検索サービスやイエローページ系検索サービスに送り、その結果を加工・編集して、ユーザに検索結果として返す検索サービスである。例としては、MetaCrawler[11]等、多数のサービスがある。MetaCrawlerでは、検索要求をAltavista、Excite[12]、Infoseek、Lycos、Webcrawler[13]、Yahoo!、の6つ検索サービスに同時に送り、これら6つの検索サービスからの結果の重複を除去した上で、1つの検索結果のページとしてユーザに返す。
AltaVistaをはじめとする多くの検索サービスでは、検索の絞り込みを行うためのオプション指定を数多く持っているが、メタ検索サービスでは、それらの内の一部のみが利用可能である場合が多い。例えば、MetaCrawlerでは、AND検索、OR検索、節一致検索の3つのみを用意している。
このように、メタ検索サービスは、複数の検索サービスの結果をまとめて表示してくれるので便利ではあるが、詳細な検索指定ができないため、「どの検索サービスを使ったらいいかわからない場合」など、初心者向けの検索サービスと言える。
WWW情報検索サービスの問題点として、以下の4つが挙げられる。
(1)検索対象データの陳腐化
(2)全WWWデータに対する検索対象WWWデータ数の割合の低下
(3)検索速度
(4)検索品質
これらの問題は、大きく(1)と(2)の問題と(3)と(4)の問題の2つに分類できる。
最初の(1)と(2)の問題は、インターネット上からWWW上のデータを自動収集するWWWロボットの処理能力に起因する。例えば、WWWロボットの処理能力が1000万URL/日(HotBot[7]の場合)であり、全世界のWWWデータ数が 2億URL であるとすると、全てのデータを収集するのに20日以上を要することになる。ところが、インターネット上の情報の移り変わりは激しく、「検索できても、検索の結果得られた20日前のリンク先が存在しない」という問題が発生する。また、同様のことは、古いリンク先情報をデータベースから消去しない場合にも発生する。
特に1996年秋までは、WWWサーバの増大に伴って、WWW情報検索サービスがデータベースとして保持するURL数も増大していたが、1996年秋以降、WWW情報検索サービスのデータベース量は最大でも1.4倍程度の増加の8,000万URLにとどまる。すなわち、現在、世界中の全WWWのデータを検索できる検索サービスは存在しない。この問題を解決するには、ロボット自体を分散化して、高速なデータ収集を可能にするか、あるいは、世界中の約192万のWWWサーバ自身に検索のための機能を付加して、分散検索を可能にする以外には方法がない。しかし、後者の方法は、プロトコルの統一など、標準化という大きな壁が立ちはだかる。
もう一方の(3)と(4)の問題は、単一データベースに起因する問題である。現在の検索サービスは、ロボットにより収集したWWWデータを単一データベースとして構築している。単一データベースは、構築が単純で効率的であるが、対象となるWWWデータの増加に伴いデータベース構築に時間がかかったり、検索時に多数の検索要求を並列に処理する能力が低かったり、という問題が発生する。また、多数の情報を検索するために、検索アルゴリズムを単純化せざるを得ず、高度な検索のアルゴリズムの搭載が困難となる。
このような問題点を解決するには、ロボット自体を分散化すると共に、データベースをも分散化しなければならない。
現在、(1)と(2)の問題に一つの解決策を与える方法として、WWWロボットの分散化に関する研究を、早稲田大学の千里眼[14]、京都大学のMo-n-do-u[15]、東京大学のODIN[16]、大阪府立大学の検索デスク[17]、WIDEプロジェクト(慶応大学及び北陸先端大学院大学)、電子技術総合研究所、IBM、シャープの協力の元に行われており、3.2.5で紹介する。
また、(3)と(4)に対する一解決策として、投機的情報検索システムを3.2.6で紹介する。
分散型WWWロボットは、複数のWWWロボットをネットワーク上の複数の拠点に分散配置し、それらを協調動作させることにより、互いに重複しないWWWサーバのデータを分散収集することによって、高速化を図ろうとする仕組みであり、インターネット上での分散コンピューティングの一つの応用例である。
分散型WWWロボットは、図3.2-4に示すように、全体を管理するPublic Robot Server Manager(PRSM)と個々のWWWロボットであるPublic Robot Server(PRS)から構成される。PRSMは、PRSに対して担当WWWサーバの分配や、収集開始などを指示し、全体を管理する。一方、PRSは、PRSMの指示に従って、WWWサーバのデータを収集する。なお、PRSで新規に発見されたWWWサーバのデータは、PRSMに送られ、どのPRSが担当するかが決定される。このように、PRSはPRSMからの指示に基づき各々互いに重複しないWWWサーバを担当しWWWデータを収集する。
収集されたデータは、最終的に図中のSearch Service Serverに再配布することにより、検索サービスのためのインデックス作成を行う。
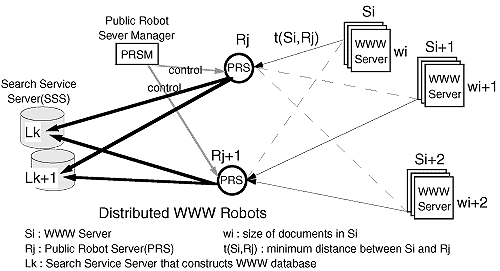
分散型WWWロボットにおいては、PRSとWWWサーバ間のデータ転送速度が、全体の収集時間を決定する大きな要因となる。このため、PRSの分担では、PRSとWWWサーバ間のサイト間距離を考慮した分散を行っている。
WWWロボットの分散による収集及び再配布時間の短縮を調べるために、日本国内の約半分にあたる6,980ドメインを対象に、計算により予備評価を行った結果を図3.2-5に示す。なお、分散ロボットであるPRSを東大、早大、電総研、及び京大の4個所に配置し、収集したデータを最終的に4つのSearch Service Serverに再配布すると仮定している。
図中のトータルコストは、PRSが担当する全WWWサーバのデータを収集し再配布を終えるまでの時間(hour)を示す。
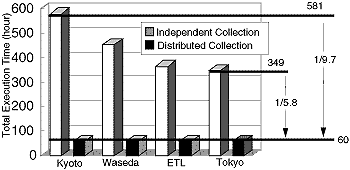
図3.2-5に示すように、WWWロボットに分散協調の機能を設け、各ロボットの設置場所に応じて収集の分担を変更する場合、4台のPRS使用時、集中型に比べて5.8~9.7倍の速度向上が得られることがわかる。
この結果は、分散型WWWロボットにおいて、分散コンピューティングの効果が顕著にあらわれていることを示している。つまり、インターネットのような広域ネットワークを対象とした場合、ネットワーク上のデータ転送遅延が大きく、分散コンピューティングによりこの遅延を隠すことができれば、分散台数以上の性能が得られることを示している。
投機的情報検索は、「高速」かつ「効率的」な検索絞込をサポートするシステムである。ユーザからの検索絞込のリクエストが無い段階からユーザの検索絞込を想定して(複数想定する)絞り込みを開始するため投機的情報検索と呼ぶ。さらに、本システムは、並列コンピューティングや分散コンピューティングで問題となる余剰計算機資源を使うことにより投機的情報検索を実現しているという特徴を持つ。つまり、計算機資源に余裕があれば、投機的情報検索を行うが、計算機資源に余裕がなければ、投機的情報検索は行わず、通常の検索サービスのみを提供する。
ユーザの検索絞込の想定にあたっては、検索要求の約40%が同一の検索要求であり、検索語を類義語で置き換える場合が約20%、さらに約15%が検索語の追加、約8%が検索語の削除という傾向[21]を用いている。そして、検索後の追加や置き換えに関しては、検索対象データから自動的に出現頻度の高いキーワード、あるいは、既に入力されている検索語の類義語を計算して用いている。また同時に、ユーザに対して、それらのキーワードを画面上に提示するという方式をとる。これは、検索結果の絞込においては、DIALOGと呼ばれるデータベースシステム中のRANKコマンド[22]や、AltaVista[6]のLiveTopics のように、検索結果中に含まれるデータ中に多く含まれるキーワードをユーザに提示し、その中から検索絞込のためのキーワードを選択させ、絞込を行う方法が有効である[23]ことがわかっているからである。
図3.2-6に投機的情報検索の概要を示す。

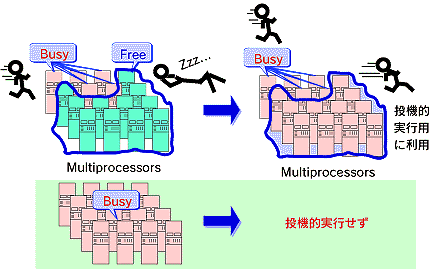
このように、投機的情報検索では、並列コンピューティングや分散コンピューティング時に無駄となっている暇なプロセッサ(計算機資源)を有効利用し、ユーザの検索をサポートする仕組みを提供している。
現在、WWWロボット系のWWW情報検索サービス分野における日本独自のシステムは、富士通のInfoNavigator[25]やNTTのTITAN[26]の二つである。富士通のシステムは、富士通の開発したAP3000と呼ばれるワークステーションクラスタをプラットフォームとして用いており、AP3000の性能を示すための一つのアプリケーションとして提供されている。一方、TITANは、純粋に検索アルゴリズムの実証のために作られたものであり、何れもWWW情報検索サービスの提供による利益の追求を目的としたものではない。
このように、現在のWWW情報検索サービスは、一つの情報産業として成り立つという面からも、採算のとれる水準に至っていない。このため、たとえWWWロボットで全WWWデータを集めることができたとしても、巨大なデータベースの構築に必要な、高性能コンピュータへの投資が思うように出来ないといった悪循環が生じている。さらに、このままの状態が続けば、世界中のWWWデータの検索ができなくなる可能性もある。
このような悪循環を断ち切るには、例えば、世界中のWWWの情報を収集するといった、WWW情報検索サービスを提供する全サイトにとって共通の利益となる部分に対しては、お互いに協力するという体制も一つの選択肢であり、その際には、3.2.5で示した分散型ロボットのような仕組みが重要となるであろう。さらに、収入源として、現在の広告収集以外に、電子課金システムによるユーザ負担(例えば1検索1円)も一考に値する。そのためには、インターネット上での電子課金システムの早期実現が望まれると共に、電子情報の共有に対するユーザの意識改革が必要である。
WWW情報検索は、これまで述べてきたようにインターネットの発展に欠かすことのできないものであるが、一方で、WWW情報検索は、「現在のインターネット上で最も多くのユーザが利用しているアプリケーションの一つ」でもある。さらに、WWW情報検索は、一つの技術により構成されるものではなく、並列処理技術、分散処理技術、さらには、文字や図形などのパターン認識や知識処理などのAI技術など、総合的技術が必要とされるアプリケーションである。
このように多岐に渡る総合的技術から構成され、かつ、多くのユーザが利用するアプリケーションは、今後の情報産業発展にとってのキラーアプリケーションとしての可能性を持つ。
すなわち、WWW情報検索に限らず、「多岐に渡る総合的技術から構成され、かつ、多くのユーザが利用するアプリケーション」を対象とした研究開発は、一旦、「研究開発→利益→研究開発」という正のフィードバックを得ることができれば、そのアプリケーション自体が産業として発展するとともに、多岐に渡る総合的技術についても研究開発が飛躍的に進む可能性を秘めている。
本項では、WWW情報検索を例題として、分散コンピューティングの研究へと発展するシナリオを考えてみる。
さらに、いくつかの疑問に対する回答例を示す。
これまで日本は、どちらかというと個々の要素技術のボトムアップで研究開発を進めてきたが、これからは、それらの成熟してきた要素技術を有機的に結び付けていくことが重要であると感じる。既に家電分野ではこの総合技術が日本の強みとなっているのは事実の通りである。
このような総合技術をこれからはコンピュータ分野に生かして行くことが求められている。その際、これまでボトムアップで積み上げてきた要素技術群を組み合わせることで、はじめて達成される総合的なアプリケーションを題材とした研究開発が重要となってくるのではないだろうか。ここで、注意しなければならないことは、アプリケーションのみを最終目標とせず、同時に研究開発が進んでいく個々の要素技術の応用を絶えず考えていくことである。
3.2.9で述べたシナリオは一例であり、本当に正しいかどうかというよりも、こういう考え方を持って研究を進めていくことが最も重要だと考える。
<参考文献>