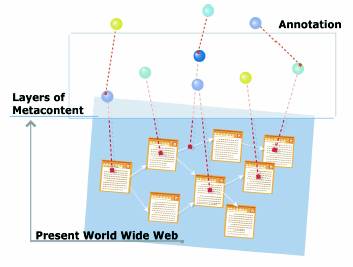
図1 アノテーションによるWebコンテンツの拡張
長尾 確 委員
次世代の高度な知識共有のインフラであるSemantic Web に不可欠なものは、ユーザが自由にコンテンツを作成し、さらにその共有化を促進し、知識として再利用可能にするためにコンテンツを意味的に拡張するツールやプラットフォームである。われわれは、これまでセマンティック・トランスコーディングという枠組みにおいて、現在のWeb の若干の延長線上に、Semantic Web と同等の機能を有する仕組みを研究してきた。それは、主に以下の3つのシステムから成っている。
これらのシステムを実現した経験に基づいて、Semantic Web の早期実現のために、近い将来に、われわれが何を、どのように行うべきか、に関する一つの提言を行う。また、動画コンテンツに対するアノテーションとそれを用いた応用についても述べる。
Semantic Web[10] はグローバルな知識共有のインフラを目指すアプローチであるが、そのような試みがそう簡単にうまくいくはずがないのは、これまでの人工知能(特に、知識工学)、あるいは経営工学における知識管理などの分野における方法論の多くの失敗から考えても明らかである。ではどうしたら、この困難な問題に対処できるだろうか。
筆者の考える「現在の」Semantic Web の主な問題点は以下の通りである。
以下では、これらの問題についての具体的なアプローチについて述べる。キーとなる概念は、アノテーションによる情報の階層化とトランスコーディングによる情報の個別化である。当然ながら、これらはXMLのような、情報を相互運用するための枠組みを前提としている。
アノテーションとトランスコーディングによって、内容および利用の観点から拡張されたWeb は、「現在における」Semantic Web の一つの具体例と考えられる。これは、人間と機械がよりよく助け合って利用するためのWebである。システムの内部に人間が上手に関わっていくための仕組みがないと、知識共有のような高度なシステムはうまく機能しないだろう。
アノテーションは、従来のデジタルコンテンツを知的コンテンツとするための最良の手段である。それは、人間が、自分自身あるいは他者の創り出したコンテンツを再評価し、価値あるものとそうでないものを見分ける良い機会が与えられるからである。コンテンツを人類共有の財産とするためには、やはり、責任を持って、そのコンテンツを吟味する人間が必要であろう。アノテーションとは、まさにそのような責任の所在を明らかにし、内容にさらなる価値を与えていく仕組みなのである。
また、トランスコーディングは、コンテンツのアクセシビリティ(ユーザの身体的特性やスキル、使用するツールなどによらずに適切にアクセスできること) を強化する手段である[1]。これによって、コンテンツは真に人類共有の資源となる。
アノテーションは人間と機械の構成するシステム全体が賢くなっていくための仕組みである。この場合の機械とは、あらかじめプログラムされた手続きを文脈に応じて選択的に実行する自律的なシステム、すなわちエージェントである。エージェントをある程度以上に複雑にする代わりに、コンテンツの方をアノテーションによって、人間がエージェントにとって都合の良い形に変えていければ、人間とエージェントとコンテンツが構成するシステム全体をより高度にすることができる。つまり、コンテンツそのものがより理解しやすくなれば、それを扱うエージェントが可能なタスクもより高度になるだろう。
ージェントはアノテーションの付与されたコンテンツを対象にすることによって、単純な手続きを繰り返すだけで、より高度なサービスを提供できる。これは、見かけ上、エージェントが賢くなったように見えるが、実際はコンテンツそのものが(人間の不断の努力によって)
賢くなっているのである。
このようになって初めて、人々はエージェントの価値を認めて受け入れていくだろう。そして、情報の収集や分類などのタスクはエージェントに任せて、より創造的な仕事に専念できるようになると思う。
図1 で示されるように、アノテーションは、現在のWeb に上位構造を作る基盤になる。現在のWeb コンテンツが最下層で、アノテーションはコンテンツに情報を付け加えるメタ(上位) コンテンツ、さらにメタコンテンツに対するメタコンテンツのように階層をなしている。
図1 アノテーションによるWebコンテンツの拡張
この図にあるように、従来のWebコンテンツは一枚の平面上に存在する要素群として捉えることができる。セマンティック・トランスコーディングでは、Webコンテンツを平面から立体に拡張する手法を提案する。コンテンツの各要素に意味や文書構造を示すアノテーションを付加する。このことによってWeb
コンテンツに、コンテンツの各要素の意味や文書構造を記述した上位構造を築くことができる。代表的なアノテーションの例としては、リンク元の文書に埋め込まれていないハイパーリンクである外部リンクXLink[7]
や、コンテンツに対するコメントなどが挙げられる。アノテーションを作成して公開することが容易になれば、Webコンテンツの表現力は大幅に高まり、その利用価値が飛躍的に向上するだろう。
アノテーションによる階層化の手法を用いて、具体的にはHTML 文書などのWeb コンテンツが抱える、以下の3つの課題を解消できるだろう。
Webは、新しいスタイルの文書のあり方を示したという点において革新的だったと言えるだろう。Webコンテンツの自由度の高さは疑いようがない。しかし、現状ではWeb コンテンツを読者が読みやすいような体裁に機械的に変換することは非常に困難である。
3.6.4 トランスコーディング:デジタルコンテンツの個別化
デジタルコンテンツがあたりまえのものとして世の中に溢れ出したのは20 世紀の情報技術の進歩からすると必然的であっただろう。そして、それら膨大なコンテンツを活用するための技術もさまざまなものが発明され、進歩を遂げていくことは間違いがない。これまでは、ともかくコンテンツを作成して流通させることが主目的であったのに対し、これからは、それらのコンテンツをいかに賢く利用するか、あるいは、いかに多様に、多目的に利用するか、ということが最も重要な課題になると思われる。
デジタルコンテンツの高度利用の主なものに、パーソナライゼーションとアダプテーションがある。デジタル放送の映像やWeb ページなどのデジタルコンテンツをユーザの好みに応じて変換することをパーソナライゼーションと呼び、それらのコンテンツをPC
やPDAや携帯電話などのデバイスの特性に合わせて変換することをアダプテーションと呼ぶ。これらは、ともにコンテンツの個別化の例である。個別化はコンテンツの送受信がブロードキャストからポイントto
ポイントになったことと大いに関係がある。
ここでは、デジタルコンテンツのパーソナライゼーションとアダプテーションを合わせたものをトランスコーディングと呼ぶ。現状では、オンラインコンテンツへのアクセスはPC
経由で行なわれることが多い。しかし、この様相は近年、急激に変わりつつある。PC に加えて、携帯電話やPDA、テレビ、カーナビなどを使ってインターネットにアクセスする機会がますます増加するだろう。このとき重要となるものがトランスコーディングである。たとえば、PC
で表示することを前提にして作成したWeb ページを携帯電話などで表示する場合、画像の縮小やテキスト部分の圧縮といった操作を自動的に行なう必要がある。トランスコーディングには、少ない伝送容量を使ってサーバからクライアントにコンテンツを配信できるという利点の他に、ユーザの嗜好に応じた理解しやすいコンテンツを生成できるといった利点がある。トランスコーディング技術を使えば、画面の表示機能やデータ伝送速度など、それぞれ違った仕様や制約をもつ多様な機器に対して、1つのコンテンツ・ソースから情報やサービスを提供できるようになる。コンテンツ・プロバイダやサービス・プロバイダは、それぞれの機器に対応したコンテンツを個別に用意しなくても済む。具体的な応用例としては、PC
向けWeb コンテンツのトランスコーディングによって、携帯電話向けのコンテンツを生成するといった利用法がある。コンテンツ・プロバイダは、現状のようにPC
向けと携帯電話向けのコンテンツを作り分ける必要がなくなる。
このトランスコーディングをさらに進めて、テキストの要約などの内容に基づく処理の精度を高める工夫を盛り込んだのが、筆者の提案するセマンティック・トランスコーディングである[4]。具体的には、コンテンツに含まれるテキスト文要素に言語構造や語彙情報をアノテーションとして関連付けることによって、要約や翻訳などの自然言語処理の精度を大きく向上させることができる。たとえば、アノテーションによってコンテンツに含まれるテキスト文の意味を明確にすると、正確な要約や翻訳が期待できる。コンテンツにアノテーションを付ける手間が増すが、誤解なく伝達すべき重要な情報にはアノテーションを付与して、より適切な形で伝達・共有すべきだろう。このアノテーションはコンテンツの内容理解を促進するものとして機能する。
セマンティック・トランスコーディングは、ユーザが指定したWeb 上の新聞記事などのコンテンツを任意の圧縮率で要約して表示したり、テレビ番組などの映像データからユーザの好みに応じた話題だけを抜き出して、ダイジェスト映像を作成するといったことを可能にする。さらに、要約したコンテンツを翻訳したり、テキストを音声化して聴くこともできる。
コンテンツサーバにおかれたテキスト、画像、音声、映像などのコンテンツはトランスコーディングプロキシによって、ユーザの使用するデバイス(PC、携帯電話、カーナビなど)
や、ユーザの要求(概要をつかみたい、母国語で読みたい、声で聞きたい、など) に合わせて加工される。このとき、アノテーションと呼ばれる付加情報を用いて、より精度の高い要約・翻訳を行なう。アノテーションはアノテーションサーバに蓄えられている。
セマンティック・トランスコーディングは、基本的にテキストコンテンツの処理を中心としたものであるが、その手法は映像や画像などの非テキストコンテンツの加工にも応用され、マルチメディアデータを含むコンテンツに適用できる。
セマンティック・トランスコーディングを実行する複数のソフトウェア・モジュール(トランスコーダ) は、HTTP プロキシ上で機能するプラグインとして実装した。トランスコーダを制御するHTTP プロキシをトランスコーディングプロキシと呼ぶ。
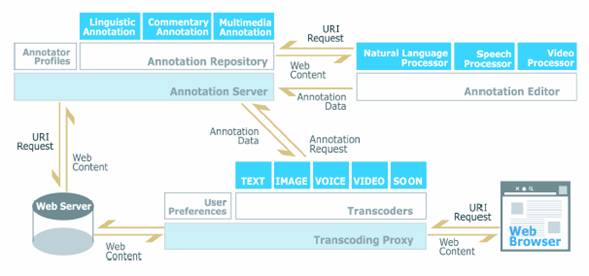
図2 セマンティック・トランスコーディングシステムの構成
図2はセマンティック・トランスコーディングシステムの構成を表している。トランスコーディングプロキシを中心とした情報の流れは次のようになる。
トランスコーディングプロキシは、実装環境としてIBM Almaden Research Center の開発したWBI (Web Intermediaries)
を使用した[2]。このWBIを利用したトランスコーディングプロキシには、以下の3つの主要な機能がある。個人情報の管理、アノテーションデータの収集と管理、そしてトランスコーダの起動と結果の統合である。
個人情報の管理を行なうには、まずアクセスしてきたユーザを特定する必要がある。ユーザの特定にCookieを使う。個人情報を管理するIDを、Cookieデータとしてユーザに渡す。これにより、ユーザのアクセスポイントに関係なくユーザの特定が行なえる。ただし、既存のWeb
ブラウザは、Cookieをセットしたサーバに対して、そのCookieを渡すものであり、プロキシのCookie 利用は考慮されていない。通常プロキシは、ホスト名とIPアドレスのみによってユーザを識別する。そこで、ユーザが個人情報をセットした時に、Cookie
情報(ユーザID) と個人情報を関連付け、一方、アクセスポイントの変化ごとにIP アドレスとホスト名、Cookie 情報(ユーザID) を関連付け直す。これによりIP
アドレスが変化してもユーザの特定が行なえる。
トランスコーディングプロキシは、アノテーションサーバと通信して、アノテーションデータを入手する。アノテーションサーバは複数存在することができるので、それぞれのサーバの管理するアノテーションデータのインデックスを定期的に作っておく。このインデックスを、どのアノテーションサーバからデータを入手すべきかを判断するときに役立てる。トランスコーディングプロキシの最も重要な役割は、個人情報とアノテーションデータに基づいてコンテンツを加工することである。コンテンツの加工は、必要なトランスコーダを起動し、その結果を統合することによって行なう。現在、開発済みのトランスコーダは、テキスト文、画像、音声、映像にそれぞれ対応したものである。これらのトランスコーダは、直列あるいは並列に結合することで、複合的なトランスコーディングが実現できる。たとえば、文書を要約後に翻訳して、さらに音声化するなどの一連の処理をトランスコーダの使い分けにより行なう。
セマンティック・トランスコーディングで用いるアノテーションは、主に文書の言語構造、マルチメディアの内容に基づく構造化情報、任意のコンテンツに対するコメント情報などである。これらは、ある種のリテラシーがあれば誰にでも作成可能な情報である。そのようなリテラシーは、アノテーションエディタと呼ばれるツールを使っているうちに自然に獲得されていくような仕組みにすべきだと思っている。
一方、「現在の」Semantic Webにおける主な(メタ)コンテンツは、RDFによるグラフ構造によるメタデータは何をどう作ればよいのかよくわからないし、OWL[11]によるオントロジカルなデータは、さらに何をどう記述すればよいのかわからない。やはり、具体的なコンテンツに関して、自然に追加できるような内容でないと動機的にも技量的にもとっかかりがないのである。
アノテーションは、コンテンツと乖離したトップダウン的なものであるべきではないし、段階的により高度なものに発展させていく必要があるだろう。そのために必要なのは、コンテンツをサーバ側で変換して配信する場合にも、オリジナルデータへのポインター(データベースURL
やレコードID など) を変換後のコンテンツの該当する部分に挿入し、アノテーションがオリジナルデータに直接関連付けられるように工夫することである。
また、当然ながら、Semantic Web は、現状のWebとシームレスに統合できるものでなければならない。トランスコーディングプロキシはサーバとクライアントの「中間」で処理を行なうため現在のWeb
のアーキテクチャに自然に統合される。ここで必要なのは、URL のようなコンテンツのポインターを要求するだけでなく、どのプロキシにどのような変換を必要するかということも含めて要求とすることである。これは、現在ではブラウザの機能とトランスコーディングプロキシのデータベースを用いることで解決しているが、たとえば、トランスコーディングのためのプロファイルをXML
を用いて標準化して、SOAP (Simple Object Access Protocol)[9]等でリクエストを送るようにすれば、より一般化できるだろう。
3.6.7 マルチメディアコンテンツのアノテーションとその応用
Semantic Web には、具体的なコンテンツの意味構造化に関する視点がまったく欠けていると言わざるを得ない。文書に対する言語構造のアノテーションに関しては別稿に譲ることにして、ここでは、マルチメディアコンテンツのへのアノテーションとその応用について述べる。
映像や音声を含むマルチメディアコンテンツは、テキストコンテンツに比べて、内容に基づく処理が極めて困難である。そこで、マルチメディアコンテンツの検索変換を行う上で必要となるインデックス情報を生成・加工し、これらをアノテーションとしてオリジナルコンテンツに関連付けておく、という手法が考えられる。われわれは、特にビデオデータを対象に研究を進めている[5,
18, 3]。
ビデオデータがさまざまな視聴環境で利用される状況を考える場合、その対処方法としては以下の2 通りが考えられる。
セマンティック・トランスコーディングが採用しているのは、後者の方法である。すなわち、コンテンツ提供者はデータを1
種類のみ用意すればよく、利用者側の環境や要求に応じてサーバがコンテンツ変換を行うようなシステムである。この場合の変換は、画面サイズやビットレートなどの視聴環境のパラメータを用いて行なう単純な変換の場合と、要約や翻訳のようなユーザの好みと(アノテーションによってもたらされる)
コンテンツの意味情報を同時に考慮して行なう複雑な変換の場合がある。セマンティック・トランスコーディングは、特にアノテーションに基づくさまざまなコンテンツ加工を特徴としている。
ただし、これを可能にするためには、コンテンツ変換を容易にするアノテーションを適宜付与しておく必要がある。コンテンツ変換を容易にするアノテーションとは、すなわちそのコンテンツの内容記述である。ビデオデータであれば、データ中のシーンやシーンに含まれる対象、人物の発話内容などである。
以下では、われわれが試作しているマルチメディアコンテンツ検索システムの概要について述べ、アノテーションに基づいたビデオ検索を実現する手法を現状のシステムを例に提案、解決すべき問題について考察する[18]。
3.6.7.1 先行研究・事例
完全なビデオデータを対象とした研究や実例は少ないが、単語と動画像の相互検索(ただし、音声ではなくクローズドキャプション(字幕)
のような映像に付加されているテキストを利用)[15]、話者と発話内容の同時検索[17]、Web 上の文書と画像のクロスメディア検索[14]、画像から画像の検索、ニュース音声のトランスクリプトに対する検索[16]
など、これまでに多くの研究がなされており、岡らのグループが研究・開発したCrossMediator[13]
は、現在実用化されているマルチメディア検索システムの1 つである。彼らは、音素や濃度ヒストグラムといったデータの時系列特徴量をインデックスとして用いて検索を行っている。
音声データを音素系列として記述する方法は、音声認識誤りによる検索精度の劣化や未知語に対して強いという利点を持つ一方で、同音語や単語境界誤り、短い単語による精度劣化や、内容に基づいた検索や要約が難しいという欠点がある。
個人が家庭で録画したデータに対して検索を行う場合には、このような手法が適していると考えられるが、Web 上で無数のデータが公開されるような場合、それらに対して検索・要約を行うためには十分な内容記述が必要である。
3.6.7.2 ビデオ検索におけるアノテーションの有用性
3.6.7.2.1 テキスト検索・イメージ検索との比較
例として、次のような検索要求を考えてみる。「テロで航空機がビルに激突したらしい」
テキスト検索ではどうだろうか。検索エンジンGoogle(www.google.com) でAnd をとる単語を増やしながら検索した結果を表1 に示す。
検索キーワード |
ヒット件数 |
| テロ | 376,000 |
| テロ, ビル | 76,500 |
| 航空機, ビル | 30,700 |
| テロ, 航空機 | 25,500 |
| テロ, 航空機, ビル | 11,400 |
| 貿易センタービルに航空機が激突 | 90 |
検索キーワードとしてユーザが与える語数は平均1,2 語と言われているが、テキストコンテンツの量がビデオコンテンツとは比較にならないほど多いことを考慮しても、検索結果としてユーザが確認・視聴するためには、相当の絞り込みや提示方法の工夫が必要であることが予想される。
一方、イメージ検索について考えてみると、この例の場合、「航空機」、「ビル」、「爆発・炎上」といったイメージあるいは単語列から検索を行うことになる。イメージからの検索は精度面から考えて現状では非常に困難であるため、ここでは単語列からの検索のみについて考える。同様にGoogleのイメージ検索を利用した結果を表2
に示す。
| 検索キーワード | ヒット件数(正解) |
| テロ | 1,700 (計測不能) |
| テロ, ビル | 117 (15) |
| 航空機, ビル | 44 (6) |
| テロ, 航空機 | 37 (6) |
| テロ, 航空機, ビル | 11 (4) |
上記の正解件数は、テロに関係するものをカウントしており、この中で実際に航空機が写っているものはわずかであった。これは、イメージの説明文としてニュース記事の文章を利用していることにより、航空機という単語が補完された結果であると考えられる。逆に、ニュースのように公共性の高い情報でなく十分な説明がなされていない場合には、イメージの検索は容易ではない。これはビデオ検索についても同様に当てはまる。
3.6.7.2.2 ビデオデータの特徴
ビデオデータの最大の特徴は、映像が持つ過去の事象の時間的連続性である。テキストには、それを扱う人間の知識や状況が反映され、時間軸の前後やスキップも容易である。イメージには、瞬間の情報は凝縮されているが、時間情報が欠落している。
ビデオデータをテキスト(実際には音声) とイメージの合成と考えると、補完の最も難しい情報は時間の経過によって我々が得ることのできる真実である。
先ほどのテロの例を考えてみる。同様の例として、イタリア・ミラノで起きた小型機事故と合わせて、テロという事実情報に着目してみる。
米国同時多発テロの場合は、事件の初期段階では、テロという言葉は断定的には使われていない。大統領の声明により、その瞬間から事件はテロであるとの認識が定まったわけである。このため、1機目と2機目の激突のシーンに対してテロという情報を与えるには、その真実を理解した人間の介在が必要になる。
一方、イタリア・ミラノ小型機事故の場合は、事件の第一報で、「テロ攻撃の可能性が非常に高い」との見方が示されたと報じたが、その後に事故説と自殺説が出た。このため、事件直後のテロという情報が誤っていることを与えるためには、やはり同様に人間の介在が必要である。
このように、ビデオデータの場合は、必ずしもその時点での音声が真実を表しているとは限らない。そのため、後からアノテーション情報を付与することが可能な仕組みが非常に重要であると考えられる。
3.6.7.3 アノテーションを利用したコンテンツ変換例
アノテーションが付与されているデータは、様々な自然言語処理が可能である。
 |
 |
|
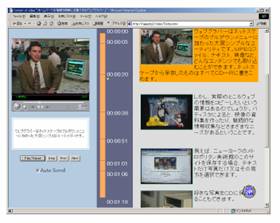
図3 ビデオドキュメント |
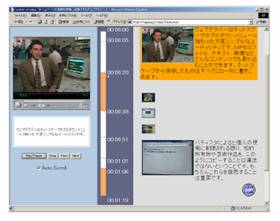
図4 要約されたビデオドキュメント |
 |
 |
|
図5 PDA 用に変換された
ビデオドキュメント |
図6 携帯電話用に変換された
ビデオドキュメント |
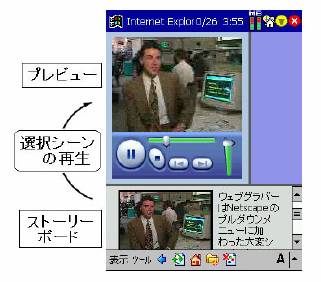
その例として、ビデオデータからHTML ドキュメントへのコンテンツ変換を行った例を図3 に示す。また、図4 は、このビデオドキュメントを要約した例を示す。さらに、図5
と図6 に、それぞれPDA 用と携帯電話用に変換されたビデオドキュメント示す。
このように、検索されたビデオデータを、ユーザの利用環境や嗜好に応じて適宜変換して提示することも、アノテーションを付与することによって可能になる。一度に多くの検索結果を視聴することのできないビデオデータにとって、これらの処理を可能にするアノテーション情報は必要不可欠である。
3.6.8.1 システム概要
我々が提案するアノテーションに基づいたビデオ検索システムの概要を図7 に示す。
システムは、コンテンツ提供者側によるアノテーション生成処理、ユーザからの検索要求に対する検索処理、ユーザ環境に応じた検索結果の変換処理、の大きく3つに分けられる。
検索結果の変換処理については、セマンティック・トランスコーディング[4] によって行う。
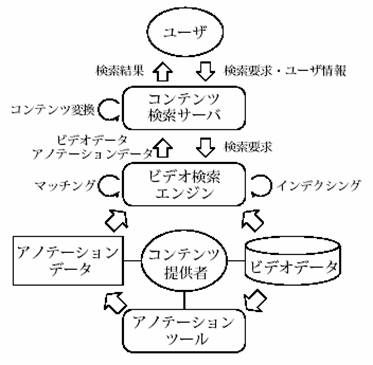
図7 ビデオ検索システムの概要
3.6.8.2 アノテーション作成
我々は、ビデオデータ中の発話情報、シーン情報、シーン内オブジェクト情報をアノテーションとして生成・編集・関連付けすることを可能にするツールとして、多言語ビデオトランスクリプタを開発している(図8)。
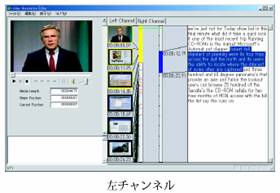
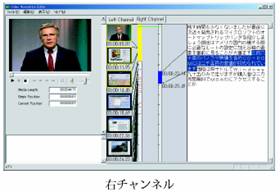
図8 多言語ビデオトランスクリプタ
ビデオデータへのアノテーションの付与は、図9に示される手順にしたがって行われ、作成したアノテーションデータは、XMLで記述される。
アノテーションによって扱う内容記述は、シナリオにおけるト書きのような情景描写(シーン) と登場人物の台詞に相当する発話文(トランスクリプト)、およびフレーム内に登場するオブジェクトの記述から構成される。
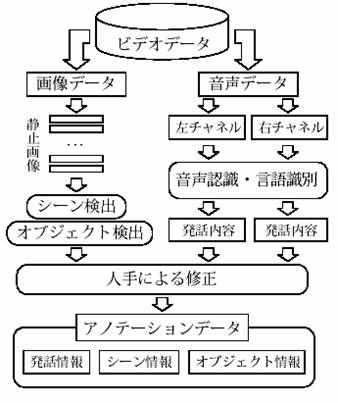
図9 ビデオアノテーションデータ生成までの手順
発話情報にはタイムコードと発話内容、シーン情報にはタイムコードとインデックスタイトル、オブジェクト情報にはタイムコードと名称、説明、矩形、リンク情報等が含まれる。
現在、音声認識、言語識別、シーン検出は自動的に処理されているが、認識誤り訂正、シーン統合、オブジェクトの切り出し、シーン記述等は、人間が行う仕組みになっている。
3.6.8.3 アノテーションに基づく検索処理
生成されるアノテーションデータには、代表シーン画像やオブジェクト画像も含まれるが、これらは検索後のコンテンツ変換や要約時に使われ、検索時には利用されない。検索の原理としては通常のテキスト検索と同じであり、代表的なベクトル空間モデルを用いて類似度を計算する。
ビデオデータの場合は、類似度の高いデータの中から目的のシーン(タイムコード) を検出することが要求されるため、類似度計算はビデオファイル全体とビデオファイル中に含まれる全シーンに対して行われる。
ビデオファイルVi がm 個のシーンから構成されるとする。
![]()
このとき、各シーンの特徴ベクトルを ![]() とすると、ビデオVi
の特徴ベクトルは、シーンの時間長とターム数によって正規化された次の式で表される。
とすると、ビデオVi
の特徴ベクトルは、シーンの時間長とターム数によって正規化された次の式で表される。
![]()
(lj : シーン時間長、L : ビデオ時間長、 nj : シーン中ターム数、N : 全ターム数)
各シーンの特徴ベクトル![]() は、発話情報Sj (t)、シーン情報Sj (s) 、オブジェクト情報Sj (o) 中に出現するタームのタームベクトルと、各々の情報に対する重み係数α、β、γ によって以下の式で表される。
は、発話情報Sj (t)、シーン情報Sj (s) 、オブジェクト情報Sj (o) 中に出現するタームのタームベクトルと、各々の情報に対する重み係数α、β、γ によって以下の式で表される。
![]()
![]()
タームベクトルを構成する各タームの重みは、TF ・IDF 法によって求められる。検索は、まず全ビデオファイルに対してビデオの特徴ベクトルを用いて類似度計算を行い、次にその中の上位R 件に含まれる全シーンに対して同様に類似度計算を行いランク付けする。最終的に、ランキング上位のrシーンを検索結果として出力する。
3.6.8.4 システムの問題点
多言語ビデオトランスクリプタにより、人間の介在する半自動的なビデオアノテーション作成の支援が可能になったが、アノテーションを付与する際の問題として、次の2 点が挙げられる。
これらは、処理の自動化と検索・要約等の実用性の意味において互いにトレードオフの関係にある。そこで、以下ではそれぞれの問題を解決する上で今後取り組む必要のある技術的課題について考察する。
3.6.8.4.1 内容記述量・精度
すでに述べたとおり、マルチメディアコンテンツは内容に基づく処理が極めて困難であることから、アノテーションツールを用いた内容記述は、ビデオ等のコンテンツの検索・要約を実現するために重要な役割を果たすと考える。しかし、内容記述が乏しかったり、機械処理に頼ることで内容記述の精度が悪いと、その後の検索や要約結果の精度を低下させる原因となる。
図10 に示すグラフは、音声認識誤りをシミュレーションして、実際の検索精度にどの程度影響を及ぼすかを分析するとともに、検索において期待されるアノテーション情報の質を予測したものである。具体的には、RWCP
検索・要約用ニュース音声データベース(192 記事、3,517 異なり単語)[12] を用いて、検索対象となる記事中に含まれる単語をランダムに除去した場合と、文書の特徴付けに有効でない単語をIDF(逆文書頻度)
値により優先的に除去した場合の2 通りについて検索実験を行い比較した。

図10 単語除去率と検索精度の関係
評価尺度には、再現率と適合率から求められるF-measureを用いた。入力クエリーにオリジナルの記事を用いており検索対象数も少ないことから、除去率が小さいときには両者に大きな差は見られないが、除去率90%になるとその差は40%程度になる。すなわち、検索に有意な10%以上の単語を音声認識の脱落誤りによって失うと、検索精度に多大な影響があることがわかる。さらに、置換誤りや挿入誤りが起こると検索精度に対する信頼性は著しく低下する。
そこで、内容記述量を向上させると同時に内容記述精度そのものを向上させる技術が必要である。前者については、アノテーションツールによる内容記述処理の自動化によってある程度は達成されているが、オブジェクト認識・トラッキング等の画像処理や発話内容に基づく談話構造化など、改良の余地はまだ多く残されている。後者については、発話文認識精度向上のための言語モデルの修正や、認識結果に対する事後処理としての認識誤り訂正処理が挙げられる。
特に、入力音声については、話題に応じた言語制約を加えることにより精度改善が期待される。音声対話システムの場合はリアルタイム性を重視するために、通常音声認識処理は1
度しか行われないが、本研究のようなオフライン処理の場合は、音声認識と言語モデル修正を繰り返し行うことにより、認識結果の精度改善を図ることが可能であると考える(図11)。言語モデルの修正には、認識結果以外に、クローズドキャプション、Web
テキスト、アノテーション情報等の外部知識が利用できる。

図11 話題に応じた言語モデルの選択・修正処理例
また、内容記述量・精度を客観的に示す評価尺度が必要である。コンテンツ時間長に対する内容記述量や、発話文認識結果の認識精度、構文としての正しさ、等を統一的な評価尺度で測った上で検索時にその評価量を導入することにより、検索結果に対する信頼性を向上させることが可能であると考えられる。
3.6.8.4.2 内容記述コスト
アノテーション付与において内容記述にかかるコストは、本システムにおける最大の課題である。内容記述にともなう機械処理の精度を極限もしくはタスク達成に必要な精度まで向上させることが最も重要であることは言うまでもないが、現実的に実用レベルのアノテーションを付与するためには人間の介在が不可欠であるため、人間がスムーズに作業を行うための入力支援やインタフェースの改良も必要である。
現時点の多言語ビデオトランスクリプタを用いて、Windows PC (CPU: PentiumIII 800MHz、Memory:512MB) 上でアノテーションを行った場合にかかるコストを表3
に示す。アノテーション作業は、まずツールの使用方法を説明した後にテストファイルを用いて10 分間操作に慣れてもらい、その後、新しいビデオファイル(88
秒) に対して作業を行ってもらった。これを計3 人分計測した。シーンとオブジェクトについては、作業者によって結果が異なるため、作業時間をシーン数、オブジェクト数で平均してある。
| 分類 | 作業者 | 平均 | ||
| A | B | C | ||
| (a) | ||||
| (b) | 88 | 70 | 74 | 77 |
| (c) | 23 | 30 | 17 | 23 |
| (d) | 528 | 394 | 425 | 449 |
| シーン数 | 5 | 4 | 4 | |
| オブジェクト数 | 2 | 3 | 2 | |
| (b-d) | 1014 | 764 | 755 | 844 |
| 計 | 1072 | 822 | 813 | 902 |
| (認識結果の単語正解率78.5%, 正解精度73.9%) (a) 機械処理(音声認識、シーン検出) 時間[sec] (b) シーン統合・内容記述時間[sec] (c) オブジェクト切り出し・内容記述時間[sec] (d) 発話内容修正時間[sec] |
表3より、音声認識精度が70〜80%の場合、アノテーション作業を行う人間にかかる時間的なコストは、機械処理にかかる時間の約15倍、アノテーションを付与する対象データ時間の10倍程度であることがわかる。誰もが手軽にアノテーションを付与できるようにするためには、今後さらなる改良が必要であると思われる。
より実用的なSemantic Web に向けて、筆者の考えと提言を述べた。また、筆者のグループで研究開発しているマルチメディアコンテンツのアノテーションとその応用システムの概要について説明し、アノテーションに基づいたビデオ検索を実現する手法を具体的なシステムを例に提案した。また、現状のシステムの問題点として、アノテーションにおける内容記述量・精度と内容記述コストを挙げ、これら解決すべき問題について考察した。今後は、システムの問題点を改善しながら個々の技術を検討し、大量のデータに対して提案した検索手法の有効性を評価していきたいと考えている。
また、昨年度のTREC-2001よりVideo Retrieval Track が導入され[6]、ビデオデータにおける類似検索の研究促進が期待されているので、こちらの動向にも注目しながら研究を進めていく予定である。
今後の課題には、もちろん、アノテーションの作成コストを下げていくことが含まれるが、その他に、アノテーションに基づく、コンテンツからの知識発見を実現することがある。近い将来には、Web上の情報検索には、既存の検索エンジンから、複数のコンテンツから新たな知識を得てその結果を要約して出力するような、いわば知識発見エンジンを使うようになるだろう。それによって、ハイパーリンクを集めた大量のリストの代わりに、短時間で容易に理解できるように要約されたコンテンツを読むことができるようになると思われる。また、映像や音声といったマルチメディアデータを含むデジタルコンテンツの効率的な検索も重要である。この場合の検索の質問には単なるキーワードではなく、音声あるいはテキストの自然言語文を用いることができるようになるだろう。
| [1] | Chieko Asakawa and Hironobu Takagi. Annotationbased transcoding for nonvisual Web access. In Proceedings of the Fourth International ACM Conference on Assistive Technologies (ASSETS 2000), pp. 172?179, 2000. |
| [2] | Steven C. Ihde, Paul P. Maglio, Joerg Meyer, and Robert Barrett. Intermediary-based transcoding framework. IBM SYSTEMS JOURNAL, Vol. 40, No. 1, pp. 179?192, 2001. |
| [3] | Katashi Nagao, Shigeki Ohira, and Mitsuhiro Yoneoka. Annotation-based multimedia summarization and translation. In Proceedings of the Nineteenth International Conference on Computational Linguistics (COLING-02), 2002. |
| [4] | Katashi Nagao, Yoshinari Shirai, and Kevin Squire. Semantic annotation and transcoding: Making Web content more accessible. IEEE MultiMedia Special Issue on Web Engineering, Vol. 8, No. 2, pp. 69?81,2001. |
| [5] | Shigeki Ohira, Mitsuhiro Yoneoka, and Katashi Nagao. A multilingual video transcriptor and annotation-based video transcoding. In Proceedings of the Second InternationalWorkshop on Content-Based Multimedia Indexing (CBMI-01), 2001. |
| [6] | Text Retrieval Conference (TREC). TREC-2002 Video Track, 2002.http://www-nlpir.nist.gov/projects/trecvid/. |
| [7] | W3C. XML Linking Language (XLink) Version 1.0,2001. http://www.w3.org/TR/xlink/. |
| [8] | W3C. Resource Description Framework (RDF) Model and Syntax Specification, 2002. http://www.w3.org/TR/REC-rdf-syntax/. |
| [9] | W3C. Simple Object Access Protocol (SOAP) 1.1,2002. http://www.w3.org/TR/SOAP/. |
| [10] | W3C. The Semantic Web Community Portal, 2002.http://www.semanticweb.org/. |
| [11] | W3C. Web-Ontology (WebOnt) Working Group,2002. http://www.w3.org/2001/sw/WebOnt/. |
| [12] | 伊藤克亘, 田中和世, 中沢正幸, 岡隆一. ニュース音声コーパスの構築. 日本音響学会講演論文集, pp. 171?172,1999. |
| [13] | 岡隆一, 西村拓一. パターン検索のアルゴリズム・マップ?CrossMediator を支えるもの?. 人工知能学会研究会資料, SIG-J-A101, pp. 1?6, 2001. |
| [14] | 森靖英, 岡隆一. WWW 上の文書・画像混在データのクロスメディア検索. 人工知能学会研究会資料, SIG-CII-2001-MAR-06, 2001 |
| [15] | 森靖英, 高橋裕信, 岡隆一. 画像と単語の相互検索手法. 人工知能学会研究会資料, SIG-CII-2000-NOV-17, 2000. |
| [16] | 西崎博光, 中川聖一. 音声入力によるニュース音声検索システム. 電子情報通信学会技術研究報告, SP99-108, pp.91?96, 1999. |
| [17] | 西田昌史, 緒方淳, 有木康雄. 話者と発話内容の同時検索に関する検討. 人工知能学会研究会資料, SIG-CII-2000-NOV-12, 2000. |
| [18] | 大平茂輝, 長尾確, 白井克彦. アノテーションに基づくビデオ検索システムの提案. 情報処理学会研究報告, SLP-43-6, pp. 33?39, 2002. |