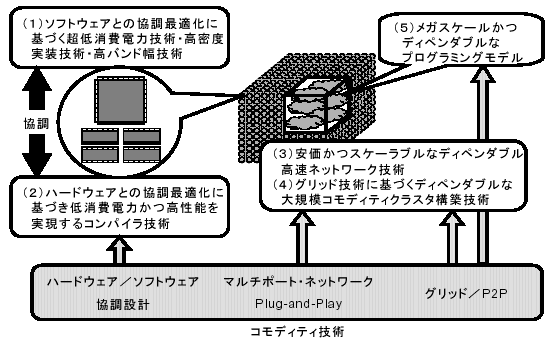
図1 プロジェクトの全体構成
第3章 ハイエンドコンピューティング研究開発の動向
3.2.2 メガスケールコンピューティングの構想
中島 浩 委員
1. はじめに
著者らは,科学技術振興事業団の戦略的基礎研究推進事業の研究領域「情報社会を支える新しい高性能情報処理技術」の研究プロジェクトとして、「超低電力化技術によるディペンダブルメガスケールコンピューティング」を進めている。本稿では、この研究プロジェクトの構想を示す。
2. 概要
ゲノム情報/生命工学などのライフサイエンス、環境・気象シミュレーションなどの複雑な物理系が絡み合う系、大規模な都市における地震や山火事などの災害シミュレーション、などでは、1ペタフロップス以上の計算能力が期待されている。その半面、従来のMPP/クラスタ計算機技術の延長でのプロセッサ数増加は、設置面積、消費電力、メンテナンス、ソフトウェア開発の面で限界に来ている。例えば、米国のASCIプロジェクトによるMPPやわが国の地球シミュレータは1万プロセッサで既に小スタジアムほどの大きさを占め、電力も数十メガワットを消費する。量子コンピュータやバイオコンピュータなどのブレークスルーも期待されるが、汎用性や実現性および信頼性の面で当面現実的とはいえない。
一方、より一般的な計算機技術分野において、メガスケールコンピューティングを実現する技術の別のコンテクストでの研究開発が進みつつ、または注目されつつある。これらは、従来のようにハイエンドではなく、むしろ汎用的なコモディティ技術の基盤となるもの、あるいはそれをベースとするものである。本節の著者らの主張は、これらの技術をベースとするアプローチ、すなわち単純に高性能や高機能を目指した従来型の高性能システムの研究開発とは根本的に異なったアプローチで、はじめてメガスケールの高性能計算を達成できるというものである。これらの技術は以下に示す、ハードウェア/ソフトウェア協調による低電力化技術、サーバ計算機などのディペンダブル技術、インターネット上の数百万ノードの計算機を統合するグリッド/Peer-to-Peer(P2P)技術、などである。
2.1 ハードウェア/ソフトウェア協調による低電力化技術
現実的な設置規模でメガスケールのシステムを構築するためには高密度実装が不可欠であるが、そのためにはまずプロセッサの消費電力を極力削減する必要がある。すなわち高密度実装がもたらす発熱密度の上昇、高性能計算に不可欠なプロセッサ高速化による発熱量の上昇、およびメガスケールという規模の拡大の3つの相乗を打ち消し、現実的な冷却/給電を可能とする必要がある。
この問題を解決して、超低消費電力かつ超高性能で超高密度実装可能なコンピュータシステムを開発するためには、プロセッサ内部からオフチップメモリやネットワークに至るアーキテクチャの見直しが必要である。特に重要なポイントは、プロセッサ、メモリ、ネットワークの相互データ転送路が消費電力・性能・実装密度の全てを律していることであり、相互データ転送の量や頻度を削減することが問題解決の唯一の方策である。
そこで本プロジェクトでは、ハードウェアとソフトウェアの協調によりデータ転送を中心とする最適化を行い、低消費電力と高性能の両立を目指した研究を行う。まずハードウェア側では、ソフトウェア制御可能なメモリ階層など、データ転送削減に有益でかつソフトウェアに可視のハードウェア機構について研究する(研究項目1)。一方ソフトウェア側では、消費電力を最適化の重点項目としたコンパイラについて、ハードウェアが提供する新たな機構の最適な活用を中心とした研究を行う(研究項目2)。
2.2 ディペンダビリティ技術
メガスケールのシステムは、インターネット並の故障率に対応しつつ、それを遥かに上回る信頼性を確保しなければならない。一方現状のクラスタ計算機では、特にネットワークの耐故障性の低さが信頼性の隘路となっている。また均質なノードを一括して組み上げるという構築手法や、それを前提としたソフトウェア基盤も、メガスケールシステムでの部分的故障やノード(群)の追加・更新に対応することができない。
そこでシステムの耐故障性を飛躍的に向上させるために、ネットワークについてはコモディティ技術であるマルチポート・ネットワークを基盤とする研究を行う(研究項目3)。すなわち各ノードが複数のポートを備えることで冗長性に基づく耐故障性を獲得し、同時に並列効果による高バンド幅も実現することができる。
またネットワークやノードの交換・追加・更新をシステム全体を停止せずに行うPlug-and-Playは、長期的なメガスケールシステムの運用に必須の機能である。この機能をcheckpointingなどの耐故障技術と組合わせたミドルウェアで実現することにより、OSに依存せず非均質な構成に対応可能なディペンダブルなソフトウェア基盤を構築する(研究項目4)。
2.3 グリッド/P2P技術
メガスケールという規模は、前述の耐故障性以外にもインターネットやグリッドコンピューティングに相通じる性質を持っている。すなわちノードの非均質性、複数クラスタの統合、大きな通信遅延など、従来のMPPやクラスタとは全く異なる性質がある。したがって、メガスケールのソフトウェア基盤やプログラミングモデルの構築の出発点として、グリッド技術の枠組を利用することが妥当かつ有望である。
ソフトウェア基盤については、前述の耐故障性に加え、性能可搬性とクラスタ連携が重要な課題となる(研究項目4)。前者については、システムの漸進的構築や進化的改良によって生じるアーキテクチャや性能が非均質な状況下でも、一定の性能が保証されるように計算を分配する機構を研究する。後者は、複数の大規模クラスタをグリッド上でセキュアかつ高性能に連携させる技術であり、メガレベルのスケーラビリティを得るために必須の要件である。
プログラミングモデルについては、Peer-to-Peer(P2P)の枠組によるタスク並列を基盤として、汎用性の高い大規模計算モデルの構築を目指す(研究項目5)。すなわち、問題を独立性が高く粒度が大きな部分計算へ分割する宣言的な枠組と、部分計算の進行に大きなバラツキを許容する計算統括・制御機構の大規模分散化を中心に研究を進める。
このような新しいコモディティな計算基盤技術に根ざし、(単なる掛け声ではなく本気で)100万プロセッサ級の汎用のディペンダブルなメガスケールコンピューティングを実現するために、上述の5つの研究項目を設定する。すなわち、コモディティメガスケールクラスタ構築のための基礎技術として;
| 1) | ソフトウェアとの協調最適化に基づく超低消費電力技術・高密度実装技術・高バンド幅技術(プロセッサ技術) |
| 2) | ハードウェアとの協調最適化に基づき低消費電力かつ高性能を実現するコンパイラ技術(コンパイラ技術) |
| 3) | 安価かつスケーラブルなディペンダブル高速ネットワーク技術(ネットワーク技術) |
| 4) | グリッド技術に基づくディペンダブルな大規模コモディティクラスタ構築技術(クラスタ構築技術) |
| 5) | メガスケールかつディペンダブルなプログラミングモデル(プログラミング技術) |
の研究を行い、さらにこれらを大規模プロトタイプ上に統合的に実現する(図1)。具体的には、従来の10倍以上の高密度実装で、1/10以下の消費電力を達成する大規模高密度クラスタ計算機を実現する。成果は各研究項目の要素技術を中心に特許化するとともに、パブリックドメインあるいはIPとして積極的に流布させ実際のメガスケール計算機の構築基盤技術とする。
図1 プロジェクトの全体構成
3. プロセッサ技術(図2)
ソフトウェア制御可能なメモリ階層をハードウェア的に提供することを中心に、ハードウェアとソフトウェアの協調により、消費電力の多くを占めるVLSI間転送を減らし、高密度実装を妨げるVLSI間配線を削減しても、豊富なVLSI内バンド幅を有効に活用することで、システム全体としての高バンド幅を実現するアーキテクチャの実現を目指す研究を行う。
このサブテーマではまず、ソフトウェアから制御可能なメモリ階層を提供するハードウェアアーキテクチャを検討する。特徴は、従来のアーキテクチャとの互換性を維持する点である。本研究は、計算機・情報機器産業界全体へ、そして社会全体へ受け入れられるメガコンピューティングの実現を目指しており、そのため、提案するアーキテクチャは広い応用分野で有効でなくてはならない、と考えるからである。具体的なアイディアとしては、従来のプロセッサではハードウェア制御下にある名前変換用レジスタ(renaming
register)を、動的にソフトウェアによる制御も可能とし、さらに、ハードウェアだけが制御可能であった多階層のキャッシュメモリをアドレス指定可能なメモリ空間としても動的に解放することで、ソフトウェア可制御性を実現する。この動的な再構成自身もソフトウェアからの制御が可能とする。これにより、処理対象の特徴に応じてコンパイラが最適な構成で、名前変換用レジスタとアドレス指定可能なメモリを利用可能となると同時に、従来のアーキテクチャとの互換性も全く失われない。
次に、並行して行われている「コンパイラ技術」と緊密な研究体制をとり、そこで開発されるコンパイラと上記ハードウェアを協調させた場合の、単体のプロセッサの性能面と消費電力の検討を行う。特に、多階層メモリをソフトウェアからも制御可能とするために増加するハードウェアが、性能と消費電力へ与えるオーバヘッドを定量的に評価しながら、必要となるメモリの階層性とハードウェア機構について検討を加える。
また、「ネットワーク技術」とも緊密な研究体制をとり、そこで開発される高速ネットワーク技術を実現する際の各ノードプロセッサの消費電力、実装密度、実効バンド幅の検討を行うことで、メガスケールコンピューティングを真に実現可能であることを示す。
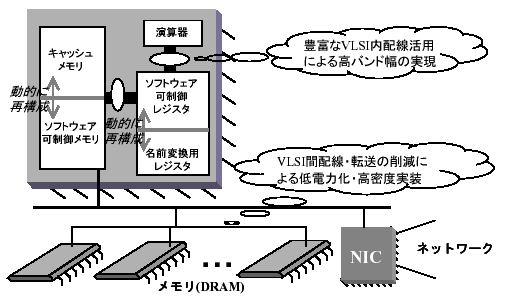
図2 プロセッサ技術
4. コンパイラ技術(図3)
消費電力を最適化の重点項目とし、ソフトウェア制御可能なメモリ階層を有効活用するためのコンパイラについて研究する。
このサブテーマではまず、設計段階において,「プロセッサ技術」と協調し、最適なアーキテクチャを探るために、アーキテクチャの様々な要素に関する記述に対応する柔軟なコンパイラシステムを開発する。この記述にはレジスタ構成や命令セットの他に、電力消費などのコストもパラメータとして含め、ハードウェア設計の最適化に対応するほか、研究をするコンパイラ最適化アルゴリズムに反映させる。
プロセッサアーキテクチャ設計において、コンパイラとの協調に関し、低消費電力化、高性能化のポイントとして以下を検討する。
| (1) | プロセッサチップとメモリ間のデータ転送の最適化:消費電力の主要部を占めるのは、オフチップメモリアクセスであり、ソフトウェアから制御可能なメモリ階層を提供できるハードウェアのアーキテクチャを検討し、そのための最適化を行う。この最適化では、命令コードの再配置による命令キャッシュの最適化や、データのオンチップメモリ利用最適化を検討する。 |
| (2) | レジスタ構成、レジスタ数に関する最適化:レジスタは最も基本的なアーキテクチャの要素であり、与えられたレジスタ構成に関して、spillが少ない割り当てアルゴリズム、ソフトウェアパイプラインなどを検討するほか、最適なレジスタ構成についてもハードウェア設計と協調し、検討する。 |
| (3) | 命令コードの選択、スケジューリング:高性能かつ低消費電力となる命令の選択やスケジューリング技法について検討する。 |
以上の最適化に関しては、静的な解析と同時に実行のプロファイルを収集する機能を実装し、消費電力の最適化を含むプログラムの動的な挙動を反映したコード生成、最適化ができるようにする。また、アルゴリズムレベルにおいて、オンチップメモリを有効に利用するなどの低消費電力化のためのアルゴリズムについても検討を行う。
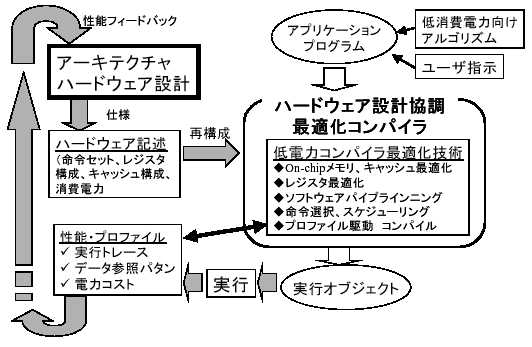
図3 コンパイラ技術
5. ネットワーク技術(図4)
コモディティネットワークの高い価格性能比を利用したマルチポート・ネットワーク技術を基盤として、耐故障性、並列効果による高バンド幅、Plug-and-Playを実現する新たなメガスケールのネットワークソリューションとしてRI2N(Redundant
Interconnection with Inexpensive Network)を提案する。
RI2Nのベースとして、高密度実装されたマルチポートネットワークインタフェースに対し、ドライバレベルでマルチパス制御・故障チェックを行うシステムを設計・開発する。故障チェックには定期的なテストパケットの交換を用い、一時的なエラーと恒久的なエラーを区別する。通常はマルチパスはユーザから透過なバンド幅倍増モードで用いられるが、故障が検出された場合は残りチャネルを代替パスとして利用しつつ、上位レベルソフトウェアとの協調により故障検出・対応プロンプティングを行う。これらの基本システムを研究前期で設計・開発する。研究後期では、ネットワークインタフェース単位またはノード単位での故障部位の活線交換に関し,「クラスタ構築技術」との連携により一貫したPlug-and-Playシステムを実現する。さらに、マルチポートNICにどのようにトラフィックを割り振るかについて、メッセージパッシング、ソフトウェアDSM等の用途に応じた最適化を可能とし、最終的にメガスケールシステムに対応したバンド幅とディペンダビリティを提供する。
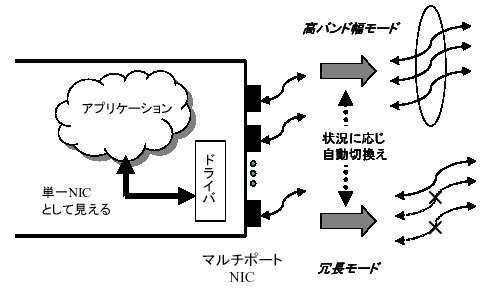
図4 ネットワーク技術
6. クラスタ構築技術(図5)
グリッド技術を基盤とするミドルウェアにより、耐故障性、Plug-and-Play、性能可搬性、クラスタ連携を実現するソフトウェア基盤技術について研究する。
実行環境を限定してしまう特殊OSに頼らず、グリッド技術によりミドルウェアレベルでディペンダブルなメガスケールクラスタを実現する技術研究を行う。開発されるミドルウェアは、(1)
柔軟でユーザ透過、かつpartial faultに対応する高性能な耐故障性、(2) クラスタの動的な更新を可能にするplug-and-play 性、(3)
異機種実行時の性能の可搬性、(4) グリッド上の複数の大規模クラスタのセキュアな連携(フェデレーション)、の4点を、タスクパラレル、データパラレル、およびそれらの混合的プログラミングのモデルでサポートすることを目指す。
耐故障性:単一ノード上の効率的なユーザレベルcheckpointing, 種々の複数ノードcheckpointingおよびlogging&recoveryアルゴリズム、ディペンダブルな通信ライブラリ、フォルトの検出器、さらに実際のメガスケールクラスタでの実行のシミュレータなどをツールキット上に構成し、様々なフォルトとリカバリモデルを柔軟に実現できるようにする。特に、検出はモデルベースのシミュレーション実行と常時比較を行い、モデルと大幅にずれた場合はpartial
faultとする。
| (1) | Plug-and-Play:(1)の耐故障性を基礎とし、さらに(3)並びに【研究項目3、5】と協調して、松岡らのグリッドの研究成果を用いて動的なノードの追加削除に柔軟に対応する。 |
| (2) | 性能可搬性:データパラレル・MPIメッセージパッシングにおいては仮想プロセッサ技法を、データパラレル・マルチスレッド実行では佐藤らのOpenMPコンパイラを用い、プログラム解析並びにランタイムでヘテロ性に対処する。タスクパラレルでは松岡らが研究してきたNinf並びに【研究項目5】の実行モデルをスケーラブルに資源並びに問題の複雑さに応じてスケジューリングする。 |
| (3) | クラスタ連携:グリッド技術を用いクラスタ間の単一の認証ドメインを実現するとともに、 クラスタを接合してメガスケールまで発展させるためのスケジューリング、高速データ転送、ファイアウォールやプライベートアドレスなどの既存セキュリティインフラへの高効率な対応、などを研究する。 |
研究の基盤として、初期はすでに松岡研究室に存在する大規模グリッド・クラスタテストベッド(3台の200プロセッサ級クラスタ)を増設してミドルウェア開発に用いるが、大規模高密度クラスタ計算機の開発にも関与し、後期には高密度クラスタプロトタイプ上に研究基盤を移す。
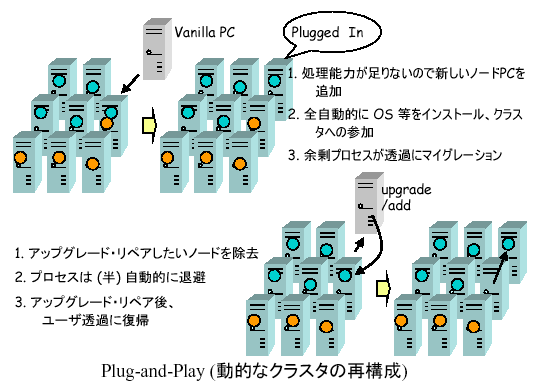
図5 クラスタ構築技術
7. プログラミング技術(図6)
Peer-to-Peer(P2P)コンピューティングの枠組を基盤として、問題を独立性が高く粒度が大きな部分計算へ分割する宣言的な枠組と、部分計算の進行に大きなバラツキを許容する計算統括・制御機構の大規模分散化を中心に、メガスケールのプログラミングモデルを構築するための研究を行う。
7.1 問題分割・統合の宣言的記述
このサブテーマでは、スクラッチからの並列プログラミングではなく、parameter surveyなどのように既設計の逐次・並列プログラムを多数並列に実行するための枠組みを研究する。すなわち既設計の「オブジェクト・プログラム」を入力引数を変化させて繰り返すなどの「メタ・プログラム」を記述する枠組みの構築が目的である。
このメタ・プログラム言語は、オブジェクト・プログラム間の関係だけではなく、オブジェクト・プログラムの挙動を部分的に記述できるように設計する。たとえばオブジェクト・プログラムが以下の関数foo(i,n)の形に表現できるとする。
foo(i,n) {
Result_Type r = initial_value_of_reduction;
for (;i<n;i++) {
r = reduction_function(r, bar(i));
}
return(r);
}
このとき、メタ・プログラムの基本的な表現は;
r = initial_value_of_reduction;
for (i=0;i<N;) {
n = next_step(i);
r = reduction_function(r, foo(i,n));
i = n;
}
のようになり、fooを単位とする処理であることが記述される。またnext_step
をシステムに委ねて、自動的な負荷調整を図ることもできる。さらにメタ・プログラムを;
r = initial_value_of_reduction;
for (i=0;i<N;i++) {
r = reduction_function(r, bar(i));
}
のように記述し、この構造がfooを利用可能であることをシステムに自動認識させてメタレベルの記述性向上を図ることもできる。
なお上記の例ではC風の記述としたが、プログラミング容易性を高くするためにPerlなどをベースとしたスクリプト言語とし、オプショナルにコンパイルも可能とする。
7.2 予測・投機による計算負荷調整
上記のメタ・プログラムの並列実行は、コンパイル時あるいは実行時の解析に基づいて行われるが、オブジェクト・プログラムの挙動を完全に解析することはできない。そこで、以下の手法を用いて計算量・通信量の予測を行い、その結果に基づき投機的に負荷調整を行う。
7.3 計算統括機構の大規模分散化
メガスケールコンピューティングでは、上記の負荷調整などの計算の統括を集中的に行うのは非現実的である。そこで計算統括機構自体も103〜104スケールに分散し、統括機構のボトルネック化を回避すると同時に負荷調整等の通信遅延耐性を高める。

図6 プログラミング技術