folon3媦傃edam偵偍偄偰丄MPI傪梡偄偰峴楍愊墘嶼傪崅懍偵 峴偆僾儘僌儔儉傪嶌惉偡傞丅忦審偼丄
a. 僒僀僘偼 1000, 2000, 3000, (壜擻側傜偽 4000)偲偡傞丅
僜乕僗僼傽僀儖傪偙偙偵嵹偣傑偟偨丅
摿偵嬅偭偨偙偲偼壗傕峴傢偢丄MPI偺Scatterv(), Bcast(), Gatherv()傪 偦偺傑傑梡偄偨丅壓庤偵帺暘偱幚憰偡傞傛傝傕婛懚偺娭悢傪巊偭偨傎偆偑 崅懍偱偁傝丄傑偨慡懱偵偍偗傞幚峴帪娫斾棪偑彮側偄偨傔嵟揔壔 偺昁梫惈偑偁傑傝柍偄偲巚傢傟偨偨傔偱偁傞丅
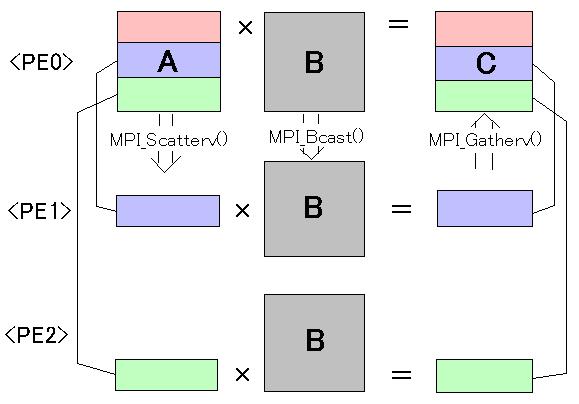
A*B=C偺峴楍墘嶼傪峴偆偵偁偨傝丄A傪峴曽岦偵暘妱偡傞丅偦偺暘妱偟偨A 偲B傪偐偗傞偙偲偵傛傝丄C偺堦晹傪摼傞偙偲偑弌棃傞丅奺PE偵A偺堦晹偲B傪 憲傝丄C偺堦晹傪寁嶼偝偣偨寢壥傪PE0偵廤傔傞偙偲偵傛傝C傪摼傞丅 奣擮恾傪埲壓偵帵偡丅
Scatterv, Gatherv偼Scatter, Gather偺奼挘斉偱丄奺PE偵憲傞僨乕僞偺 僒僀僘傪巜掕偡傞偙偲偑弌棃傞丅傑偢丄峴楍偺僒僀僘傪慡PE偵 Bcast偡傞丅偦偟偰丄帺暘偑峴楍偺偳偺晹暘傪寁嶼偡傞偺偐 乮Scatterv, Gatherv偺堷悢偲側傞丄偳偺PE偵偳偺僨乕僞傪憲傞偺偐傪 昞偡攝楍乯傪寁嶼偡傞丅偦傟傪梡偄偰A傪Scatterv偟丄B傪Bcast偟丄 峴楍愊傪寁嶼偟偨屻丄寢壥傪Gatherv偱廤傔偰偄傞丅偙偺曽朄偵傛傝丄 1埲忋偺擟堄偺戝偒偝偺峴楍丄擟堄偺悢偺PE偵偍偄偰幚峴偡傞偙偲偑偱偒傞丅
峴楍偼丄儔儞僟儉偱抣傪嶌惉偡傞曽朄偲僼傽僀儖偐傜撉傒崬傓曽朄 偺俀偮傪慖傇偙偲偑弌棃傞丅僐儅儞僪儔僀儞偵悢傪巜掕偡傟偽偦偺戝偒偝偺 儔儞僟儉側峴楍傪惗惉偟丄僼傽僀儖柤傪巜掕偡傟偽偦偺僼傽僀儖偐傜撉傒崬傓丅 傑偨丄僾儕僐儞僷僀儖帪偺define傪偐偊傞偙偲偵傛傝丄抣偺惓摉惈専徹傕 峴偆偙偲偑弌棃傞丅
慜婜偺戝愇愭惗偺悢抣寁嶼偺丄峴楍愊崅懍壔偺儗億乕僩傪尦偵偟偰
嶌惉偟偨丅
峴楍傪崅懍壔偡傞偨傔偺曽朄偲偟偰丄
丒儖乕僾岎姺
丒儖乕僾傾儞儘乕儕儞僌
丒僽儘僢僋壔
摍偑偁傞丅
偙偺拞偱嵟傕岠壥偑偁傞偺偼峴楍偺僽儘僢僋壔偱偁傞丅
怓乆側僒僀僘傪帋偟偰傒偨偲偙傠丄120*120偺戝偒偝偑
嵟傕寢壥偑傛偐偭偨丅
儖乕僾傾儞儘乕儕儞僌偼峴楍僒僀僘偺栺悢偱偁傞偲
岠壥偑崅偄偨傔丄偦傟偵偁傢偣偨偲偙傠丄
傾儞儘乕儕儞僌悢偑40偺応崌偑嵟傕崅懍偲側偭偨丅
傑偨丄僽儘僢僋壔偟偨応崌偵偼丄儖乕僾偺弴斣傪岎姺偟偰傕
懍偔偼側傜側偐偭偨丅
傑偨丄僽儘僢僋壔偱偼丄A*B=C偺寁嶼偺偲偒偵丄尦偺攝楍偐傜 A,B傪堦晹暘僐僺乕(tA,tB)偟偰寁嶼偟偨寢壥(tC=tA*tB)傪 嵞傃C偵僐僺乕偡傞偺偑偄偄偼偢偱偁傞偑丄捈愙C偵擖傟偨 応崌偺傎偆偑懍偐偭偨丅
傑偨丄僐儞僷僀儖僆僾僔儑儞偲偟偰丄
丒-O3 乧 嵟揔壔僆僾僔儑儞
丒-march=i686 乧 i686偵摿壔偟偨僐乕僪傪偼偔
丒-funroll-loops 乧 儖乕僾傪揥奐偡傞乮傜偟偄乯
傪巜掕偟偨偑丄-O3埲奜偼傎偲傫偳摦嶌懍搙偼懍偔側傜側偄丅
偪傚偭偲懍偔側傞婥偑偡傞掱搙偱偁傞丅
偦偺懠偺岺晇偲偟偰丄僽儘僢僋壔偟偨晹暘傪暿娭悢偲偟偰偄傞偑丄 屇傃弌偟偺僆乕僶乕僿僢僪傪彮側偔偡傞偨傔偵丄僀儞儔僀儞揥奐 傪梡偄偰偄傞丅偙傟偵傛傝彮偟偩偗懍搙偑岦忋偟偨婥偑偡傞丅