MPIを使って並列動作するFFTプログラムを作成し、FolonIV上で実行しました。
作成に当たり、効率は悪くてもとりあえず動くものをつくり、その上で時間に余裕があればより効率の良いものに改良する、という方針にしました。改良は、絶対性能を上げることよりも、並列化に伴うオーバーヘッドを減らすことに注力し、なるべく台数効果が出るようにしました。
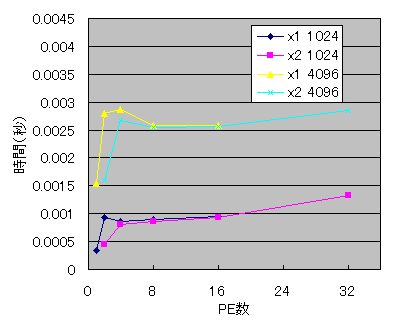
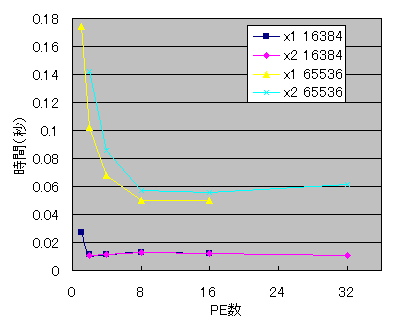
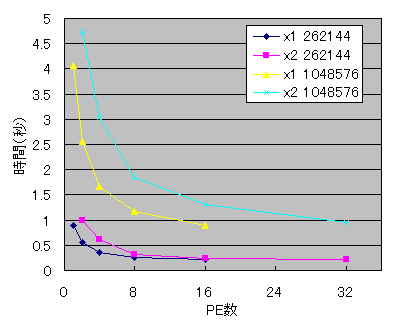
ランダムに生成した配列に対して「変換→逆変換」を何回か繰り返し、1セット当たりの実行時間を計測しました。プログラムを3回実行し、最小値を使っています。Cコンパイラはicc、オプションは-O2を使用しました。
凡例の「x1」は1PCで1PE使って実行したもの、「x2」は2PEずつ使ったものです。その後の数字はデータ数です。
1PEで実行したときの何倍の性能が出たかを表すグラフです。全てのせるとグラフが込み合ってしまうので、データ数の大きなもの、中くらいのもの、小さいものからそれぞれ特徴的なものを抜き出しました。

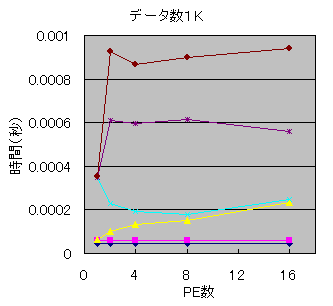
データ数が1Kと1Mの場合について、各処理にかかっている時間を詳細に調べ、何がボトルネックになっているのか調べました。
 |
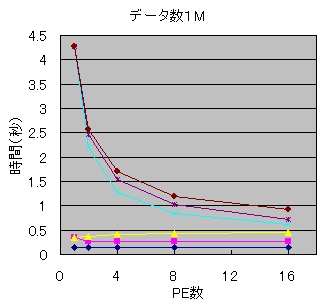 |
 |
データ数が大きいときは並列化の効果が出ていますが、4092以下の場合には並列化によって余計に時間がかかるようになってしまいました。また、データ数が16Kや256Kの時には、並列化の効果は出ているものの、途中からPE数を増やしても速度がほとんど変化しなくなってしまいました。
ステージごとの時間を見ると、データ数が少ない場合には、最初にデータを各PEに送信するときや、通信しながら変換しているとき、変換が終了したデータを集計するときなど、通信を伴う処理の時間が支配的になっていることが分かります。現在のプログラムには通信方法にまだ改善の余地があるので、このオーバーヘッドはもう少し減らすことができるかもしれません。
各PCで2PEずつ使って処理をした場合、データ数が大きいときには非常に遅くなっていますが、データ数が少なくなるにつれその差は小さくなり、4K以下では2PEずつ使ったほうが速くなっています。2PEずつ使った場合は、メモリバスの衝突が起こるために速度が低下しますが、データ数が少なくキャッシュ上に乗っている場合は、メモリアクセスの回数が少ないのでその影響が小さくて済む為です。また、データ数が多いときには、PE数が半分になっても各PC1PEで実行したほうが速いという結果になりましたが、プログラムの局所参照性を改善してメモリアクセスの頻度を抑えれば違う結果になるかもしれません。
データ数が16Kの場合、PE数が2の時に並列効果が2倍を超えています。これはちょうどキャッシュに全てのデータが乗ったため、と思ったのですが、1PEで実行した場合でもデータのサイズは256KBで、三角関数の値を保持する配列のサイズ128KBとあわせても2次キャッシュサイズ512KBを下回っています。この原因についてはもう少し詳しく調べる必要があるようです。
最終更新日:2003/2/22